

#数据源:https://github.com/BlankerL/DXY-COVID-19-Data
#工 具:jupyter notebook + python3.6.5-amd64(pandas、pycharts模块) + pycharm
#参 考:3分钟揭秘python开发动态疫情地图背后原理,python可视化开发案例分享 - 知乎
#读取和转化数据
import pandas as pd #读取excel
from pyecharts import options as opts #可视化选项
from pyecharts.charts import Timeline,Map #时间线、地图
from pyecharts.globals import ThemeType,CurrentConfig,NotebookType #图表主题
#数据源https://github.com/BlankerL/DXY-COVID-19-Data
dxy_file = 'DXYArea.xls'
list_color = ['#color','#color','#color','#color','#color']
#把excel文件读取为DataFrame形式的数据,并筛选出China数据
dxy = pd.read_excel(io = dxy_file, usecols = ['countryEnglishName','provinceName','province_confirmedCount','updateTime'])
dxy0 = dxy[(dxy.countryEnglishName == 'China')]
dxy1 = dxy0[['provinceName','province_confirmedCount','updateTime']]
#类型转换
dxy1['updateTime'] = dxy1['updateTime'].astype(str).str[0:10]
#按省份分组统计
dxy11 = dxy1.groupby(['provinceName','updateTime']).apply(lambda t: t[t.province_confirmedCount == t.province_confirmedCount.max()])
dxy11 = dxy11[['provinceName','province_confirmedCount','updateTime']]
dxy11 = dxy11.drop_duplicates() #删除重复值
dxy2 = dxy11.reset_index(drop=True) #重置索引
dxy2.head()
print(dxy2)
结果:
provinceName province_confirmedCount updateTime
0 上海 5080 2022-03-23
1 上海 5094 2022-03-24
2 上海 5135 2022-03-25
3 上海 5182 2022-03-26
4 上海 5235 2022-03-27
... ... ... ...
1531 黑龙江 2987 2022-06-18
1532 黑龙江 2987 2022-06-20
1533 黑龙江 2987 2022-06-21
1534 黑龙江 2988 2022-06-26
1535 黑龙江 2988 2022-06-27
[1536 rows x 3 columns]
#筛选出6月份指定日期的数据
df_20220323 = dxy2[dxy2['updateTime'].str.contains("2022-03-23")]
df_20220324 = dxy2[dxy2['updateTime'].str.contains("2022-03-24")]
df_20220325 = dxy2[dxy2['updateTime'].str.contains("2022-03-25")]
df_20220326 = dxy2[dxy2['updateTime'].str.contains("2022-03-26")]
df_20220327 = dxy2[dxy2['updateTime'].str.contains("2022-03-27")]
df_20220328 = dxy2[dxy2['updateTime'].str.contains("2022-03-28")]
df_20220329 = dxy2[dxy2['updateTime'].str.contains("2022-03-29")]
df_20220330 = dxy2[dxy2['updateTime'].str.contains("2022-03-30")]
df_20220331 = dxy2[dxy2['updateTime'].str.contains("2022-03-31")]
df_20220401 = dxy2[dxy2['updateTime'].str.contains("2022-04-01")]
df_20220402 = dxy2[dxy2['updateTime'].str.contains("2022-04-02")]
df_20220403 = dxy2[dxy2['updateTime'].str.contains("2022-04-03")]
df_20220404 = dxy2[dxy2['updateTime'].str.contains("2022-04-04")]
df_20220405 = dxy2[dxy2['updateTime'].str.contains("2022-04-05")]
df_20220406 = dxy2[dxy2['updateTime'].str.contains("2022-04-06")]
df_20220407 = dxy2[dxy2['updateTime'].str.contains("2022-04-07")]
df_20220408 = dxy2[dxy2['updateTime'].str.contains("2022-04-08")]
df_20220409 = dxy2[dxy2['updateTime'].str.contains("2022-04-09")]
df_20220410 = dxy2[dxy2['updateTime'].str.contains("2022-04-10")]
df_20220411 = dxy2[dxy2['updateTime'].str.contains("2022-04-11")]
df_20220419 = dxy2[dxy2['updateTime'].str.contains("2022-04-19")]
df_20220429 = dxy2[dxy2['updateTime'].str.contains("2022-04-29")]
df_20220430 = dxy2[dxy2['updateTime'].str.contains("2022-04-30")]
df_20220501 = dxy2[dxy2['updateTime'].str.contains("2022-05-01")]
df_20220502 = dxy2[dxy2['updateTime'].str.contains("2022-05-02")]
df_20220503 = dxy2[dxy2['updateTime'].str.contains("2022-05-03")]
df_20220509 = dxy2[dxy2['updateTime'].str.contains("2022-05-09")]
df_20220510 = dxy2[dxy2['updateTime'].str.contains("2022-05-10")]
df_20220511 = dxy2[dxy2['updateTime'].str.contains("2022-05-11")]
df_20220512 = dxy2[dxy2['updateTime'].str.contains("2022-05-12")]
df_20220513 = dxy2[dxy2['updateTime'].str.contains("2022-05-13")]
df_20220519 = dxy2[dxy2['updateTime'].str.contains("2022-05-19")]
df_20220520 = dxy2[dxy2['updateTime'].str.contains("2022-05-20")]
df_20220521 = dxy2[dxy2['updateTime'].str.contains("2022-05-21")]
df_20220522 = dxy2[dxy2['updateTime'].str.contains("2022-05-22")]
df_20220523 = dxy2[dxy2['updateTime'].str.contains("2022-05-23")]
df_20220524 = dxy2[dxy2['updateTime'].str.contains("2022-05-24")]
df_20220528 = dxy2[dxy2['updateTime'].str.contains("2022-05-28")]
df_20220529 = dxy2[dxy2['updateTime'].str.contains("2022-05-29")]
df_20220530 = dxy2[dxy2['updateTime'].str.contains("2022-05-30")]
df_20220531 = dxy2[dxy2['updateTime'].str.contains("2022-05-31")]
df_20220601 = dxy2[dxy2['updateTime'].str.contains("2022-06-01")]
df_20220602 = dxy2[dxy2['updateTime'].str.contains("2022-06-02")]
df_20220603 = dxy2[dxy2['updateTime'].str.contains("2022-06-03")]
df_20220604 = dxy2[dxy2['updateTime'].str.contains("2022-06-04")]
df_20220605 = dxy2[dxy2['updateTime'].str.contains("2022-06-05")]
df_20220606 = dxy2[dxy2['updateTime'].str.contains("2022-06-06")]
df_20220607 = dxy2[dxy2['updateTime'].str.contains("2022-06-07")]
df_20220608 = dxy2[dxy2['updateTime'].str.contains("2022-06-08")]
df_20220609 = dxy2[dxy2['updateTime'].str.contains("2022-06-09")]
df_20220610 = dxy2[dxy2['updateTime'].str.contains("2022-06-10")]
df_20220611 = dxy2[dxy2['updateTime'].str.contains("2022-06-11")]
df_20220612 = dxy2[dxy2['updateTime'].str.contains("2022-06-12")]
df_20220613 = dxy2[dxy2['updateTime'].str.contains("2022-06-13")]
df_20220614 = dxy2[dxy2['updateTime'].str.contains("2022-06-14")]
df_20220615 = dxy2[dxy2['updateTime'].str.contains("2022-06-15")]
df_20220616 = dxy2[dxy2['updateTime'].str.contains("2022-06-16")]
df_20220617 = dxy2[dxy2['updateTime'].str.contains("2022-06-17")]
df_20220618 = dxy2[dxy2['updateTime'].str.contains("2022-06-18")]
df_20220619 = dxy2[dxy2['updateTime'].str.contains("2022-06-19")]
df_20220620 = dxy2[dxy2['updateTime'].str.contains("2022-06-20")]
df_20220621 = dxy2[dxy2['updateTime'].str.contains("2022-06-21")]
df_20220622 = dxy2[dxy2['updateTime'].str.contains("2022-06-22")]
df_20220623 = dxy2[dxy2['updateTime'].str.contains("2022-06-23")]
df_20220624 = dxy2[dxy2['updateTime'].str.contains("2022-06-24")]
df_20220625 = dxy2[dxy2['updateTime'].str.contains("2022-06-25")]
df_20220626 = dxy2[dxy2['updateTime'].str.contains("2022-06-26")]
df_20220627 = dxy2[dxy2['updateTime'].str.contains("2022-06-27")]
df_20220628 = dxy2[dxy2['updateTime'].str.contains("2022-06-28")]
df_20220629 = dxy2[dxy2['updateTime'].str.contains("2022-06-29")]
#将筛选出的数据,组合成一个list
df_list = [df_20220601,df_20220602,df_20220603,df_20220604,
df_20220605,df_20220606,df_20220607,df_20220608,df_20220609,
df_20220610,df_20220611,df_20220612,df_20220613,df_20220614,
df_20220615,df_20220616,df_20220617,df_20220618,df_20220619,
df_20220620,df_20220621,df_20220622,df_20220623,df_20220624,
df_20220625,df_20220626,df_20220627,df_20220628,df_20220629]
df_list
[ provinceName province_confirmedCount updateTime
40 上海 63009 2022-06-01
110 中国 2677846 2022-06-01
179 云南 2149 2022-06-01
293 北京 3382 2022-06-01
361 台湾 2121231 2022-06-01
429 吉林 40293 2022-06-01
477 四川 2334 2022-06-01
539 天津 1975 2022-06-01
623 山东 2735 2022-06-01
706 广东 7303 2022-06-01
775 广西 1634 2022-06-01
924 河北 2005 2022-06-01
969 河南 3182 2022-06-01
1021 浙江 3137 2022-06-01
1198 福建 3262 2022-06-01
1331 重庆 712 2022-06-01
1465 香港 332398 2022-06-01,
provinceName province_confirmedCount updateTime
41 上海 63018 2022-06-02
111 中国 2754879 2022-06-02
180 云南 2150 2022-06-02
294 北京 3393 2022-06-02
362 台湾 2198161 2022-06-02
... ... ... ...
1301 辽宁 1718 2022-06-28
1397 陕西 3329 2022-06-28
1492 香港 336942 2022-06-28,
provinceName province_confirmedCount updateTime
68 上海 63242 2022-06-29
138 中国 4291463 2022-06-29
251 内蒙古 2097 2022-06-29
321 北京 3680 2022-06-29
389 台湾 3728363 2022-06-29
504 四川 2374 2022-06-29
631 山东 2751 2022-06-29
734 广东 7443 2022-06-29
854 江苏 2247 2022-06-29
890 江西 1389 2022-06-29
1040 浙江 3155 2022-06-29
1136 澳门 189 2022-06-29
1226 福建 3422 2022-06-29
1302 辽宁 1718 2022-06-29
1348 重庆 732 2022-06-29
1398 陕西 3329 2022-06-29
1493 香港 337306 2022-06-29]
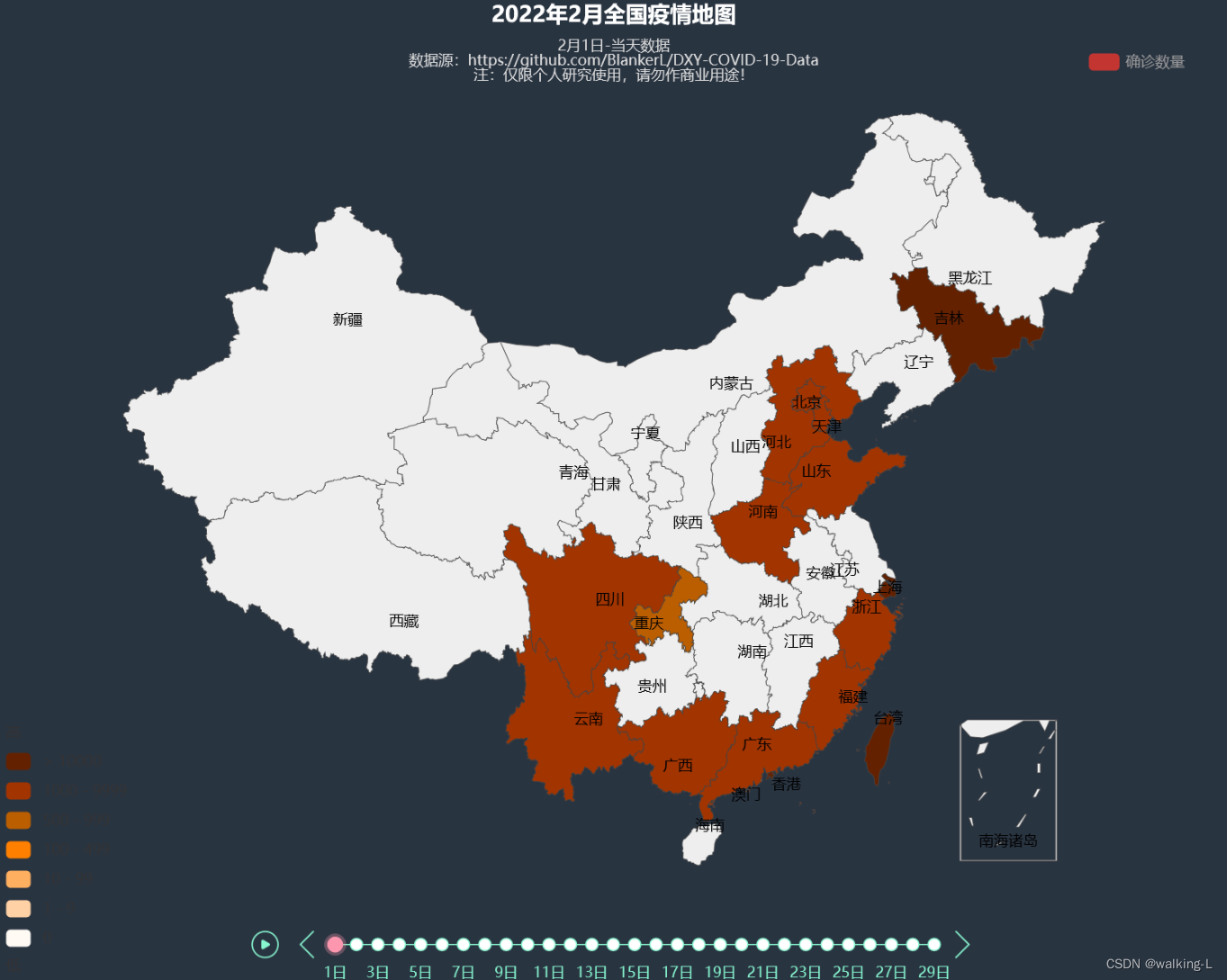
#疫情时间线
def ltimeline() -> Timeline:
tl = Timeline(init_opts=opts.InitOpts(page_title="疫情地图",
theme=ThemeType.CHALK,
width="1000px", #图像宽度
height="800px"),
)
for idx in range(0, 29): #循环十四天
provinces = []
confirm_value = []
for item_pv in df_list[idx]['provinceName']:
provinces.append(item_pv)
for item_pc in df_list[idx]['province_confirmedCount']:
confirm_value.append(item_pc)
zipped = zip(provinces,confirm_value) #组合两个字段
f_map = (
Map(init_opts=opts.InitOpts(width="800px",
height="500px",
page_title="疫情地图",
bg_color=None))
.add(series_name="确诊数量",
data_pair=[list(z) for z in zipped],
maptype="china",
is_map_symbol_show=False)
.set_global_opts(
#设置标题
title_opts=opts.TitleOpts(title="2022年2月全国疫情地图",
subtitle="2月{}日-当天数据\n"
"......".format(idx + 1),
pos_left="center",),
#设置图例
legend_opts=opts.LegendOpts(
is_show=True, pos_top="40px", pos_right="30px"),
#设置视觉映射
visualmap_opts=opts.VisualMapOpts(
is_piecewise=True, range_text=['高','低'], pieces=[ #分段显示
{"min": 10000, "color": "#642100"},
{"min": 1000, "max": 9999,"color": "#a23400"},
{"min": 500, "max": 999, "color": "#bb5e00"},
{"min": 100, "max": 499, "color": "#ff8000"},
{"min": 10, "max": 99, "color": "#ffaf60"},
{"min": 1, "max": 9, "color": "#ffd1a4"},
{"min": 0, "max": 0, "color": "#fffaf4"}
]),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True),
markpoint_opts=opts.MarkPointOpts(
symbol_size=[90,90],symbol='circle'),
effect_opts=opts.EffectOpts(is_show='True',)
)
)
tl.add(f_map, "{}日".format(idx + 1))
tl.add_schema(is_timeline_show=True, #是否显示
play_interval=1000, #播放间隔
symbol=None, #图标
is_loop_play=True #循环播放
)
return tl
ltimeline().render_notebook()
输出结果:

Original: https://blog.csdn.net/liaowang010/article/details/125556806
Author: walking-L
Title: pyecharts制作中国疫情地图
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679078/
转载文章受原作者版权保护。转载请注明原作者出处!