

书接上回~~
整数索引
接下来索引篇的一个难点,处理pandas的整数索引常常会难住新手,因为它与python的内置列表元组的索引方式不同。例如下面代码:
ser = pd.Series(np.arange(3.))
ser
ser[-1]
是不是没什么问题?? 不,这里错了!!!
这里,pandas可以勉强进行整数索引,但是会导致小bug。我们有包含0,1,2的索引,但是引入用户想要的东西(基于标签或位置的索引)很难。
另外,对于非整数索引,不会产生歧义:
In [145]: ser2 = pd.Series(np.arange(3.), index=['a', 'b', 'c'])
In [146]: ser2[-1]
Out[146]: 2.0
为了进行统一,如果轴索引含有整数,数据选取总会使用标签。为了更准确,请使用loc(标签)或iloc(整数):
In [147]: ser[:1]
Out[147]:
0 0.0
dtype: float64
In [148]: ser.loc[:1]
Out[148]:
0 0.0
1 1.0
dtype: float64
In [149]: ser.iloc[:1]
Out[149]:
0 0.0
dtype: float64
算术运算和数据对齐
pandas最重要的一个功能就是,它可以对不同索引的对象进行算术运算。当你把对象相加时,如果存在某个索引不对应,返回结果就是索引的并集。对于用过数据库的同学们来说,这类似与数据库中的自动外连接。以下是示例:
In [150]: s1 = pd.Series([7.3, -2.5, 3.4, 1.5], index=['a', 'c', 'd', 'e'])
In [151]: s2 = pd.Series([-2.1, 3.6, -1.5, 4, 3.1],
.....: index=['a', 'c', 'e', 'f', 'g'])
In [152]: s1
Out[152]:
a 7.3
c -2.5
d 3.4
e 1.5
dtype: float64
In [153]: s2
Out[153]:
a -2.1
c 3.6
e -1.5
f 4.0
g 3.1
dtype: float64
In [154]: s1 + s2
Out[154]:
a 5.2
c 1.1
d NaN
e 0.0
f NaN
g NaN
dtype: float64
自动的数据对齐操作在不重叠的索引处引入了NA值。缺失值会在算术运算过程中传播。
对于DataFrame,对齐操作会同时发生在行和列上:
In [155]: df1 = pd.DataFrame(np.arange(9.).reshape((3, 3)), columns=list('bcd'),
.....: index=['Ohio', 'Texas', 'Colorado'])
In [156]: df2 = pd.DataFrame(np.arange(12.).reshape((4, 3)), columns=list('bde'),
.....: index=['Utah', 'Ohio', 'Texas', 'Oregon'])
In [157]: df1
Out[157]:
b c d
Ohio 0.0 1.0 2.0
Texas 3.0 4.0 5.0
Colorado 6.0 7.0 8.0
In [158]: df2
Out[158]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In [159]: df1 + df2
Out[159]:
b c d e
Colorado NaN NaN NaN NaN
Ohio 3.0 NaN 6.0 NaN
Oregon NaN NaN NaN NaN
Texas 9.0 NaN 12.0 NaN
Utah NaN NaN NaN NaN
因为’c’和’e’列均不在两个DataFrame对象中,在结果中以缺省值呈现。行也是同样。
如果DataFrame对象相加,没有共用的列或行标签,结果都会是空:
In [160]: df1 = pd.DataFrame({'A': [1, 2]})
In [161]: df2 = pd.DataFrame({'B': [3, 4]})
In [162]: df1
Out[162]:
A
0 1
1 2
In [163]: df2
Out[163]:
B
0 3
1 4
In [164]: df1 - df2
Out[164]:
A B
0 NaN NaN
1 NaN NaN
使用填充值的算术方法
经过上面模块的学习,我想你也发现了一个问题,我在这两个不同索引对象运算中,我不想让它生成NaN,我想自己设置出现不同的情况怎么办。pandas当然也设计了如下,比如你要填充值是0时:
In [165]: df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)),
.....: columns=list('abcd'))
In [166]: df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)),
.....: columns=list('abcde'))
In [167]: df2.loc[1, 'b'] = np.nan
In [168]: df1
Out[168]:
a b c d
0 0.0 1.0 2.0 3.0
1 4.0 5.0 6.0 7.0
2 8.0 9.0 10.0 11.0
In [169]: df2
Out[169]:
a b c d e
0 0.0 1.0 2.0 3.0 4.0
1 5.0 NaN 7.0 8.0 9.0
2 10.0 11.0 12.0 13.0 14.0
3 15.0 16.0 17.0 18.0 19.0
In [171]: df1.add(df2, fill_value=0)
Out[171]:
a b c d e
0 0.0 2.0 4.0 6.0 4.0
1 9.0 5.0 13.0 15.0 9.0
2 18.0 20.0 22.0 24.0 14.0
3 15.0 16.0 17.0 18.0 19.0
图5-2列出了Series和DataFrame的算术方法。它们每个都有一个副本,以字母r开头,它会翻转参数。因此这两个语句是等价的:
In [172]: 1 / df1
Out[172]:
a b c d
0 inf 1.000000 0.500000 0.333333
1 0.250000 0.200000 0.166667 0.142857
2 0.125000 0.111111 0.100000 0.090909
In [173]: df1.rdiv(1)
Out[173]:
a b c d
0 inf 1.000000 0.500000 0.333333
1 0.250000 0.200000 0.166667 0.142857
2 0.125000 0.111111 0.100000 0.090909
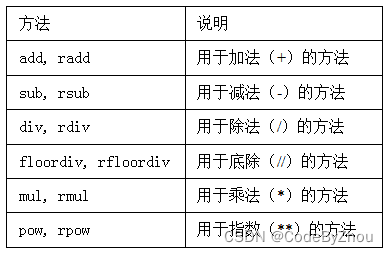

图5-2 灵活的算术方法
与此类似,在对Series或DataFrame重新索引时,也可以指定一个填充值:
In [174]: df1.reindex(columns=df2.columns, fill_value=0)
Out[174]:
a b c d e
0 0.0 1.0 2.0 3.0 0
1 4.0 5.0 6.0 7.0 0
2 8.0 9.0 10.0 11.0 0
DataFrame和Series之间的操作
这两者之间的操作与Numpy中不同维度数组的操作类似,如果你有学习过我之前的文章,这一小节也会理解的非常快。首先举个例子,考虑二维数组和其中一行之间差:
In [175]: arr = np.arange(12.).reshape((3, 4))
In [176]: arr
Out[176]:
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
In [177]: arr[0]
Out[177]: array([ 0., 1., 2., 3.])
In [178]: arr - arr[0]
Out[178]:
array([[ 0., 0., 0., 0.],
[ 4., 4., 4., 4.],
[ 8., 8., 8., 8.]])
当我们从arr减去arr[0],每一行都会执行这个操作。这就叫做广播(broadcasting)。DataFrame和Series之间的运算差不多也是如此:
In [179]: frame = pd.DataFrame(np.arange(12.).reshape((4, 3)),
.....: columns=list('bde'),
.....: index=['Utah', 'Ohio', 'Texas', 'Oregon'])
In [180]: series = frame.iloc[0]
In [181]: frame
Out[181]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In [182]: series
Out[182]:
b 0.0
d 1.0
e 2.0
Name: Utah, dtype: float64
In [183]: frame - series
Out[183]:
b d e
Utah 0.0 0.0 0.0
Ohio 3.0 3.0 3.0
Texas 6.0 6.0 6.0
Oregon 9.0 9.0 9.0
如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集:
In [184]: series2 = pd.Series(range(3), index=['b', 'e', 'f'])
In [185]: frame + series2
Out[185]:
b d e f
Utah 0.0 NaN 3.0 NaN
Ohio 3.0 NaN 6.0 NaN
Texas 6.0 NaN 9.0 NaN
Oregon 9.0 NaN 12.0 NaN
如果你希望匹配行且在列上广播,则必须使用算术运算方法。例如:
In [186]: series3 = frame['d']
In [187]: frame
Out[187]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In [188]: series3
Out[188]:
Utah 1.0
Ohio 4.0
Texas 7.0
Oregon 10.0
Name: d, dtype: float64
In [189]: frame.sub(series3, axis='index')
Out[189]:
b d e
Utah -1.0 0.0 1.0
Ohio -1.0 0.0 1.0
Texas -1.0 0.0 1.0
Oregon -1.0 0.0 1.0
传入的轴号就是希望匹配的轴。在本例中,我们的目的是匹配DataFrame的行索引(axis=’index’ or axis=0)并进行广播。
再分个P~~
Original: https://blog.csdn.net/zhouxyly/article/details/125507914
Author: CodeByZhou
Title: 啃书:《利用python进行数据分析》第五章——pandas入门(二)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678875/
转载文章受原作者版权保护。转载请注明原作者出处!