

原文:learning-with-hypergraphs-clustering-classification-and-embedding
摘要:
贡献:超图表示超越双边关系的复杂关系。
-
提出谱聚类超图:用无向图中的谱聚类应用在超图
-
由超图拉普拉斯提出超图嵌入和直推算法。
引言:
一个具有成对关系的对象集可以自然地表示为一个图,其中顶点表示对象,任意两个有某种关系的顶点由一条边连接在一起。图可以是无向的,也可以是有向的。它取决于对象之间的成对关系是否对称。欧氏空间中与核矩阵相关的有限点集是无向图的一个典型例子。关于有向图,一个著名的例子是万维网。一个超链接可以被认为是一条有向边,因为给定一个任意的超链接,我们不能期望一定存在逆边,也就是说,基于超链接的关系是不对称的[20]。
然而,在许多现实问题中,将一组复杂的关系对象表示为无向图或有向图是不完全的。为了说明这一观点,让我们考虑一个问题,将一组文章分成不同的主题。给定一篇文章,假设我们拥有的唯一信息是谁写的这篇文章。我们可以构建一个无向图,其中两个顶点由一条边连接在一起,如果它们对应的文章中至少有一个共同的作者(图1),然后应用一种基于无向图的聚类方法,例如谱图技术[7,11,16]。为每条边赋予等于共同作者数量的权值,可以进一步修饰无向图。但这上面的方法听起来很自然,但在它的图形表示中,我们显然忽略了同一个人是否参与了三篇或更多文章的写作。这种信息丢失是意外的,因为同一个人的文章可能属于同一主题,因此这些信息对我们的分组任务很有用。
补救上述方法中出现的信息丢失问题的一种自然方法是将数据表示为超图。超图是这样一种图:一条边可以连接两个以上的顶点[2]。换句话说,一条边是顶点的子集。下面我们将把一般的无向图或有向图统一地称为简单图。此外,无需特别说明,所提到的简单图是无向的。很明显,简单图是一种特殊的超图,每条边只包含两个顶点。在前面提到的文章聚类问题中,用代表文章的顶点和代表作者的边构造一个超图是非常简单的(图1)。每条边包含对应作者的所有文章。更重要的是,如果我们有,我们可以考虑在边缘加上正权重,将我们之前的知识编码到作者的作品中。例如,对于一个在广泛领域工作的人,我们可以给他相应的边指定一个相对较小的值。
现在我们可以用超图来完全表示对象之间的复杂关系。然而,一个新的问题出现了。如何划分超图?这是本文要解决的主要问题。划分简单图的一种强大技术是谱聚类。因此,我们将谱聚类技术推广到超图上,具体地说,是[16]的归一化切割方法。此外,对于简单的图表,超图的实值放松规范化削减标准导致的矩阵分解半正定矩阵,可以被视为一个所谓的拉普拉斯算子模拟简单的图表(cf。[5]),因此我们暗示地称之为超图拉普拉斯算子。因此,我们开发了基于超图拉普拉斯算子的超图嵌入和转导推理算法。
实际上,关于超图划分已有大量的文献,这些文献来源于各种实际问题,如划分电路网表[11]、分类数据聚类[9]、图像分割[1]等。然而,与目前的工作不同的是,他们通常使用我们在一开始讨论的启发式或其他特定领域的启发式将超图转换为简单图,然后应用基于简单图的谱聚类技术。[9]提出了一种迭代方法,它确实是为超图设计的。然而,它不是光谱方法。此外,[6]和[17]还考虑了超图上的传播标签分布。
本文的结构如下。第二节首先介绍超图的一些基本概念。在第三节中,我们将简单图的归一化切割推广到超图。如第4节所示,超图归一化切割基于与超图自然相关的随机漫步有一个优雅的概率解释。在第5节中,我们介绍了用实值松弛近似得到超图归一化割的方法,以及由该松弛导出的超图拉普拉斯算子。在第6节中,我们开发了一种基于超图拉普拉斯算子的光谱超图嵌入技术。在第7节中,我们讨论了超图的转导推理,即在超图的某些顶点已被标记的情况下对其顶点进行分类。第8节给出了实验结果,第9节给出了本文的结论。
引言:
现实生活很多图,无向图,有向图:超链接等
超图的必要性:对于无向图,只能存储部分信息。比如论文图,无向图只能存储两篇论文的共同作者关系,以共同作者数量作为边的权重。而超图可以获取同一作者的多篇论文关系。
超图的构建:一个边包含多个顶点,可以根据顶点之前的信息对边进行加权,比如如果作者的研究领域很广泛,则他相关的超边的权重设置较小。
本文主要工作- 超图划分(超图分类)实现超图的Ncut谱聚类:简单图-谱聚类,超图-基于超图拉普拉斯实现超图聚类。以往工作的问题:都是使用启发式将超图转化为简单图,再用简单图的谱聚类解决分类问题。或者没有用谱方法的超图。
① 提出基于超图的Ncut谱聚类最优化问题
②基于随机游走解释超图Ncut谱聚类的合理性
③通过实值松弛得到超图Ncut,得到超图拉普拉斯
④基于超图拉普拉斯得到谱超图嵌入,解决直推性分类问题
超图相关知识:
超图G(V,E,w),超边权重w
超顶点的度=所有关联超边的权重和 超边的度=超顶点的个数
De(边的度对角矩阵)Dv(顶点度对角矩阵)
顶点v到j的超路径:能通过多个超边从v到达j
连通超图:每个顶点之间可以相互到达
表示超图:关联矩阵H(|V|*|E|):(v,e)=1表示v在e上


邻接矩阵:HWH^T-Dv表示超顶点的邻接矩阵
谱图聚类:只要知道图的邻接结构以及权重,就可以用拉普拉斯将图进行聚类
前置条件:
- 拉普拉斯矩阵L:
除了上述的拉普拉斯矩阵,还有规范化的 Laplacian 矩阵形式:
简单图的谱聚类思想:找到一种分割方法,使得将分割后的子图内部的权重尽可能高,连接子图之间的权重尽可能低。分为两种:Ratio-cut和Ncut
因此,对于
个不同的类别 ,优化的目标为:
其中每个单项表示连接该类和对类之间边的权重。
以二分为例,将图聚类成两个类:
类和类。假设用来表示图的划分,我们需要的结果为:
问题1:如果这样分割,很容易出现不好的分割,子图节点个数不均衡,一个类只有一个点,比如:
解决方法:加入子图内部权重和
其中|Ai|表示子图的节点个数,vol(Ai)表示子图内所有节点的度(权重)之和
因为个数多不一定代表节点之间的关系更加紧密,所以以权重衡量即Ncut一般比Ratiocut表现更好。
- 拉普拉斯和Ncut优化函数的关系:
Ncut = fLf,其中ff^T=I
f为h的行
谱聚类的过程:
超图谱聚类:
- 超图G=(V,E,w):
子图体积:所有子图节点度之和
子图S的超边边界:(和其他的子图之间的超边权重):
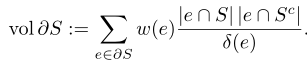
理解:假设一条超切边e,其中e∩S表示在S中的节点,e∩Sc表示在Sc的节点,所以将e假设分为全连接子边,则e中共|e∩S|*|e∩Sc|条子边,每条子边权重相同,为w(e)/δ(e)
则超图聚类问题化为最小值问题:

- 通过数学计算:
上面最优化问题松弛转化为:

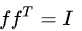
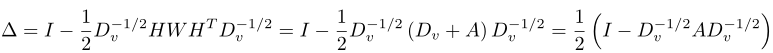
- 根据数学知识:当f为△的最小的特征向量的时候上式取得最小值,本质上就是求△最小的非零特征值所对应的特征向量。
当要聚类成多个类的时候:

即求解△的最小k个特征值对应的k个特征向量,将k个特征向量竖着排列,每行作为样本的嵌入,再用kmeans进行聚类
(PS:f本应为指示向量,但是用特征向量进行松弛,所以还需要进行聚类)
- 转导推理(类似于半监督,用标记数据和未标记测试集同时训练模型,但是新数据加进去的时候需要重新训练模型)比如-SVM,KNN-适用于标记样本很少的情况
实验:
属性超图:将属性值作为超边,即具有相同属性的所有样本放在同一超边中,具有多少个属性值就有多少条超边。一个样本可以有多个属性
①对动物进行聚类:每个动物都有17个属性
②对蘑菇进行分类(可食用和不可食):每个蘑菇都有11个属性:
③对文本进行分类(4类)
④对信封进行分类(A-E五类)
对比实验:简单图(相同属性就有边)
超图嵌入:利用谱聚类得到每个样本的欧式空间的向量,即样本的嵌入
超图应用-生物网络、社交网络交易。。。
优点:提出超图的谱聚类以及超图的相关概念
缺点:实验说明不充足,有点没太看懂
Original: https://blog.csdn.net/qq_42217335/article/details/120456827
Author: DestinationYSJ
Title: 超图学习:聚类、分类和嵌入(实现超图谱聚类和节点嵌入)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549930/
转载文章受原作者版权保护。转载请注明原作者出处!