

Pandas读取的数据为DataFrame类型,而DataFrame可以写入到各种格式的文件中,其中包括json、html、文本文件、数据库、Excel文件等等。(注:DataFrame对象可以转化为Numpy的ndarray对象,通过to_numpy函数)。
Pandas内置了10余种数据源读取函数和对应的数据写入函数,常见的数据源有3种,分别为数据库数据,文本文件(包括txt和csv文件)和Excel文件。
下面主要介绍文本文件以及Excel文件的读取:
目录
- 1.读写文本文件
* - 1.1 文本文件的写入
- 1.2 文本文件的读取
- 1.3 文本文件读写的例子
- 2.读写Excel文件
* - 2.1 Excel文件的写入
- 2.2 Excel文件的读取
- 2.3 Excel文件读写的例子
1.读写文本文件
csv文件是一种用分隔符分隔的文件格式,因为其分隔符不一定是逗号,因此又被称为字符分隔文件。csv文件也是一种文本文件,因此也可以通过文本文件的读取函数对csv文件进行读取。
1.1 文本文件的写入
对于DataFrame数据,可以写入到各种格式的文件中,其中包括json、html、使用DataFrame对象的to_csv函数实现csv文件的写入,该函数将DataFrame数据写入到文本文件中。
该函数的语法及常用参数如下:
DataFrame.to_csv(path_or_buf=None, sep=",", na_rep="", float_format=None,
columns=None, header=True, index=True, index_label=None,
mode="w", encoding=None, compression="infer", quoting=None,
quotechar='"', line_terminator=None, chunksize=None,
date_format=None, doublequote=True, escapechar=None, decimal=".",)
参数介绍:
path_or_buf:接收string,代表文件路径
seq:接收string,代表分隔符,默认’,’
na_rep:接收string,代表缺失值,默认”
columns:接收list,代表写入的列名,默认none
header:接收boolean,代表是否将列名写入,默认true
index: 接收boolean,代表是否将行名写入,默认true
index_label: 接收sequence,代表行索引名,默认None
mode:接收特定string,代表数据写入模式,默认w
encoding:接收string,代表存储文件的编码方式,默认None
1.2 文本文件的读取
pandas提供了read_table来读取文本文件,提供了read_csv函数来读取csv文件。对于这两个函数的很多参数是相同的,由于其参数过多,下面只介绍常用的参数如下:
filepath: 接收string。代表文件路径。无默认
sep: 接收string,代表分隔符,read_csv 默认为’,’, read_table 默认为制表符’Tab’
header: 接收int或sequence表示将某行数据作为列名。默认为infer,表示自动识别,None表示数据里面不含列名
names: 接收array,表示列名,默认为None
engine:接收c或者python。代表数据解析引擎。默认为c
nrows:接收int,表示读取前n行。默认为None
usecols:接收元组,读取的为该元组中对应的列
dtype:接收dict,可以读取并结构化数据类型
1.3 文本文件读写的例子
1.准备要保存的数据
4行3列数据,列名为’age’, ‘name’, ‘sex’
import numpy as np
import pandas as pd
from pandas import DataFrame
x = np.arange(12).reshape(4, 3)
data = DataFrame(x, columns=['age', 'name', 'sex'])
print(data.values)
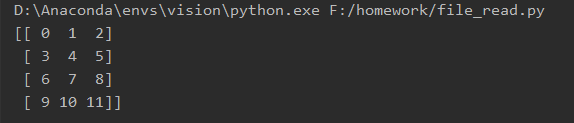

2.写入文件
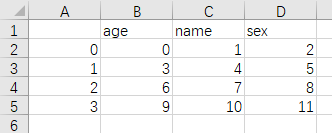
将dataframe类型的数据存入文件3.csv,分隔符为” , “
data.to_csv('3.csv', sep=',')
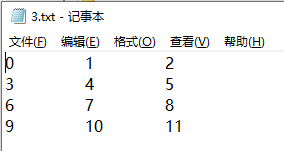
将dataframe类型的数据存入文件3.txt,分隔符为tab,不将列名和行名写入
data.to_csv('3.txt', sep='\t', header=False, index=False)
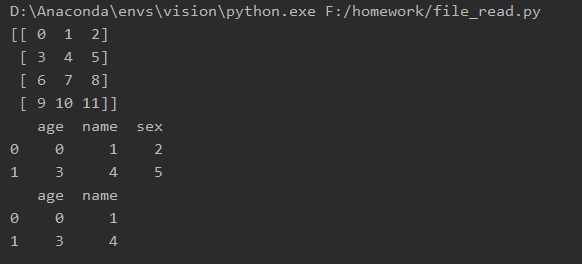
3.读取3.csv中的数据
使用read_csv读取3.csv中前两行的数据
x1 = pd.read_csv('3.csv', sep=',', encoding='utf-8', nrows=2, index_col=0)
print(x1)

使用read_table读取3.txt中前两行前两列的数据,并指定列名为’age’, ‘name’
x2 = pd.read_table('3.txt', sep='\t', encoding='utf-8', names=['age', 'name'], usecols=(0, 1), nrows=2)
print(x2)

完整代码:
import numpy as np
import pandas as pd
from pandas import DataFrame
x = np.arange(12).reshape(4, 3)
data = DataFrame(x, columns=['age', 'name', 'sex'])
print(data.values)
data.to_csv('3.csv', sep=',')
data.to_csv('3.txt', sep='\t', header=False, index=False)
x1 = pd.read_csv('3.csv', sep=',', encoding='utf-8', nrows=2, index_col=0)
print(x1)
x2 = pd.read_table('3.txt', sep='\t', encoding='utf-8', names=['age', 'name'], usecols=(0, 1), nrows=2)
print(x2)
运行结果:
2.读写Excel文件
2.1 Excel文件的写入
使用DataFrame对象的to_excel函数实现excel文件的写入,该函数将DataFrame数据写入到excel文件中。
DataFrame.to_excel(excel_writer=None, sheet_name="Sheet1", na_rep="",
header=True, index=True, index_label=None, mode='w', encoding=None)
to_excel函数与to_csv函数常用的参数基本一致,区别在于to_excel函数指定存储文件的文件路径参数名称为excel_writer,没有seq参数,另外增加了sheet_name参数,用来指定存储的excel sheet的名称,默认为sheet1
2.2 Excel文件的读取
pandas还提供了read_excel函数来读取xls与xlsx两种excel文件,其语法和常用参数如下:
pd.read_excel(io, sheet_name=0, header=0, names=None,dtype=None)
io:接收string
sheet_name:接收string,int,代表Excel表内分表的位置,默认为0
header:接收int或sequence,表示将某行数据作为列名,默认为infer表示自动识别,None表示数据里面不含列名
names: 接收array,表示列名,默认为None
dtype:接收dict,可以读取并结构化数据类型
2.3 Excel文件读写的例子
1.准备要保存的数据
4行3列数据,列名为’age’, ‘name’, ‘sex’
import numpy as np
import pandas as pd
from pandas import DataFrame
x = np.arange(12).reshape(4, 3)
data = DataFrame(x, columns=['age', 'name', 'sex'])
print(data.values)
2.写入文件
写入1.xlsx文件中的表一
data.to_excel(excel_writer='1.xlsx', sheet_name="Sheet1")
打开后该文件中的内容如下:
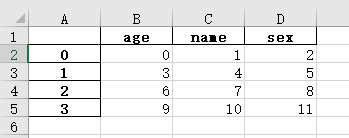
3.读取1.xlsx文件
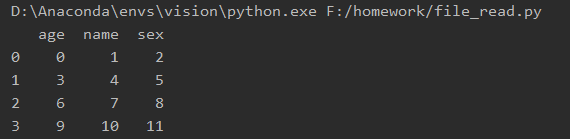
读取1.xlsx中的表1的内容,此处index_col=0参数表明第一列为索引列,不是数据内容,没有该参数,显示的内容会有第一列0,1,2,3的内容。
a = pd.read_excel('1.xlsx', sheet_name=0, index_col=0)
完整代码:
import numpy as np
import pandas as pd
from pandas import DataFrame
x = np.arange(12).reshape(4, 3)
data = DataFrame(x, columns=['age', 'name', 'sex'])
print(data)
data.to_excel(excel_writer='./data/1.xlsx', sheet_name="Sheet1")
a = pd.read_excel('./data/1.xlsx', sheet_name=0, index_col=0)
print(a)
运行结果:
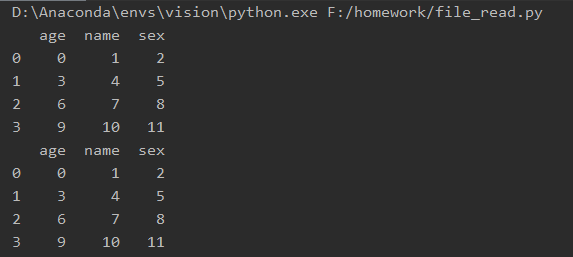
Original: https://blog.csdn.net/qq_38048756/article/details/119618457
Author: 馋学习的身子
Title: pandas读写文件
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678783/
转载文章受原作者版权保护。转载请注明原作者出处!