

另外,本文所使用的实验环境为1个GTX 1080 GPU,数据集为VOC2007,超参数为hyp.scratch-low.yaml,训练200个epoch,其他参数均为源码中默认设置的数值。
YOLOv5中修改网络结构的一般步骤:
models/common.py:在common.py文件中,加入要修改的模块代码models/yolo.py:在yolo.py文件内的parse_model函数里添加新模块的名称models/new_model.yaml:在models文件夹下新建模块对应的.yaml文件
一、Shufflenetv2
[Cite]Ma, Ningning, et al. “Shufflenet v2: Practical guidelines for efficient cnn architecture design.” Proceedings of the European conference on computer vision (ECCV). 2018.
旷视轻量化卷积神经网络Shufflenetv2,通过大量实验提出 四条轻量化网络设计准则,对输入输出通道、分组卷积组数、网络碎片化程度、逐元素操作对不同硬件上的速度和内存访问量MAC(Memory Access Cost)的影响进行了详细分析:
- 准则一:输入输出通道数相同时,内存访问量MAC最小
- Mobilenetv2就不满足,采用了拟残差结构,输入输出通道数不相等
- 准则二:分组数过大的分组卷积会增加MAC
- Shufflenetv1就不满足,采用了分组卷积(GConv)
- 准则三:碎片化操作(多通路,把网络搞的很宽)对并行加速不友好
- Inception系列的网络
- 准则四:逐元素操作(Element-wise,例如ReLU、Shortcut-add等)带来的内存和耗时不可忽略
- Shufflenetv1就不满足,采用了add操作
针对以上四条准则,作者提出了Shufflenetv2模型,通过Channel Split替代分组卷积,满足四条设计准则,达到了速度和精度的最优权衡。
Shufflenetv2有两个结构:basic unit和unit from spatial down sampling(2×)
- basic unit:输入输出通道数不变,大小也不变
- unit from spatial down sample :输出通道数扩大一倍,大小缩小一倍(降采样)
Shufflenetv2整体哲学要紧紧向论文中提出的轻量化四大准则靠拢,基本除了准则四之外,都有效的避免了。
为了解决GConv(Group Convolution)导致的不同group之间没有信息交流,只在同一个group内进行特征提取的问题,Shufflenetv2设计了Channel Shuffle操作进行通道重排,跨group信息交流
class ShuffleBlock(nn.Module):
def __init__(self, groups=2):
super(ShuffleBlock, self).__init__()
self.groups = groups
def forward(self, x):
'''Channel shuffle: [N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,W] -> [N,C,H,W]'''
N, C, H, W = x.size()
g = self.groups
return x.view(N, g, C//g, H, W).permute(0, 2, 1, 3, 4).reshape(N, C, H, W)
- common.py文件修改:直接在最下面加入如下代码
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(batchsize, -1, height, width)
return x
class conv_bn_relu_maxpool(nn.Module):
def __init__(self, c1, c2):
super(conv_bn_relu_maxpool, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
def forward(self, x):
return self.maxpool(self.conv(x))
class Shuffle_Block(nn.Module):
def __init__(self, inp, oup, stride):
super(Shuffle_Block, self).__init__()
if not (1 stride 3):
raise ValueError('illegal stride value')
self.stride = stride
branch_features = oup // 2
assert (self.stride != 1) or (inp == branch_features << 1)
if self.stride > 1:
self.branch1 = nn.Sequential(
self.depthwise_conv(inp, inp, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(inp),
nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(inp if (self.stride > 1) else branch_features,
branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
@staticmethod
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
- yolo.py文件修改:在yolo.py的
parse_model函数中,加入conv_bn_relu_maxpool, Shuffle_Block两个模块(如下图红框所示)
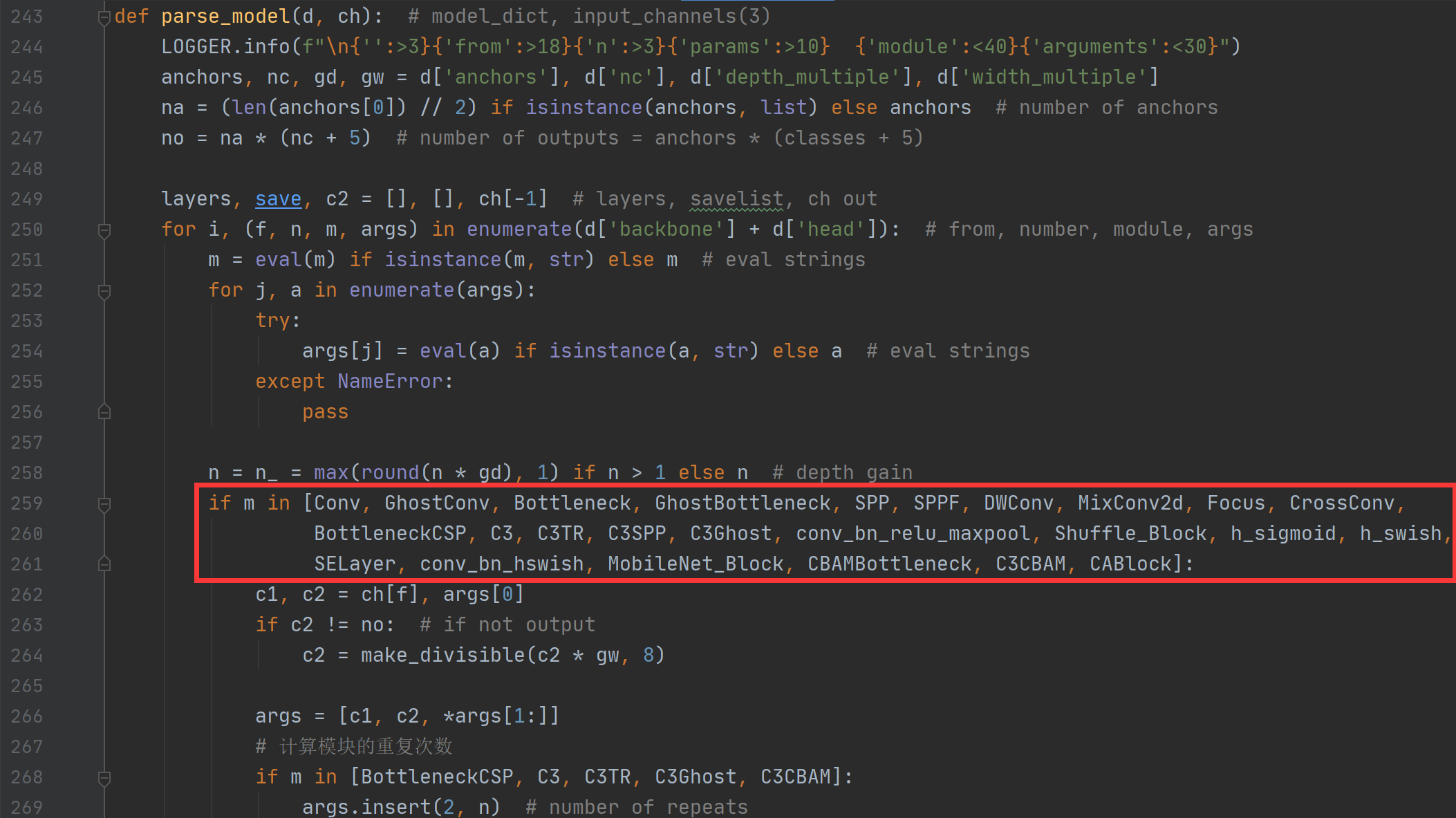

- 新建yaml文件:在model文件下新建
yolov5-shufflenetv2.yaml文件,复制以下代码即可
nc: 20
depth_multiple: 1.0
width_multiple: 1.0
anchors:
- [10,13, 16,30, 33,23]
- [30,61, 62,45, 59,119]
- [116,90, 156,198, 373,326]
backbone:
[[ -1, 1, conv_bn_relu_maxpool, [ 32 ] ],
[ -1, 1, Shuffle_Block, [ 128, 2 ] ],
[ -1, 3, Shuffle_Block, [ 128, 1 ] ],
[ -1, 1, Shuffle_Block, [ 256, 2 ] ],
[ -1, 7, Shuffle_Block, [ 256, 1 ] ],
[ -1, 1, Shuffle_Block, [ 512, 2 ] ],
[ -1, 3, Shuffle_Block, [ 512, 1 ] ],
]
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]],
[-1, 1, C3, [256, False]],
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]],
[-1, 1, C3, [128, False]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, 11], 1, Concat, [1]],
[-1, 1, C3, [256, False]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, 7], 1, Concat, [1]],
[-1, 1, C3, [512, False]],
[[14, 17, 20], 1, Detect, [nc, anchors]],
]
二、Mobilenetv3
[Cite]Howard, Andrew, et al. “Searching for mobilenetv3.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
MobileNetV3,是谷歌在2019年3月21日提出的轻量化网络架构,在前两个版本的基础上,加入神经网络架构搜索(NAS)和h-swish激活函数,并引入SE通道注意力机制,性能和速度都表现优异,受到学术界和工业界的追捧。
主要特点:
Mobilenetv1提出了深度可分离卷积,就是将普通卷积拆分成为一个 深度卷积(Depthwise Convolutional Filters)和一个逐点卷积(Pointwise Convolution):
- Depthwise Convolutional Filters:将卷积核拆分成为单通道形式,在不改变输入特征图像深度的情况下, 对每一通道进行卷积操作,这样就得到了 和输入特征图通道数一致的输出特征图,这样就会有一个问题,通道数太少,特征图的维度太少,能获取到足够的有效信息吗?
- Pointwise Convolution:逐点卷积就是1×1卷积,主要作用就是对特征图进行升维和降维,在深度卷积的过程中,假设得到了8×8×3的输出特征图,我们用256个1×1×3的卷积核对输入特征图进行卷积操作,输出的特征图和标准的卷积操作一样都是8×8×256了
深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道,如果来的通道很少的话,DW深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要”扩张”通道。
既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征,这样不管输入通道数是多少, 经过第一个PW逐点卷积升维之后,深度卷积都是在相对的更高6倍维度上进行工作。
Inverted residuals: 为了像Resnet一样复用特征,引入了 shortcut结构,采用了 1×1 -> 3 ×3 -> 1 × 1 的模式,但是不同点是:
- ResNet 先降维 (0.25倍)、卷积、再升维
-
Mobilenetv2 则是 先升维 (6倍)、卷积、再降维
-
SE组件的作用是:可以通过显示地建模通道之间的相互依存关系来增强通道级的特征响应(说白了就是 学习一组权重,将这组权重赋予到每一个通道来进一步改善特征表示),使得重要特征得到加强,非重要特征得到弱化
- 具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = y.view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
近似操作模拟swish和relu,公式如下:
h _ s w i s h ( x ) = x ∗ R e L U 6 ( x + 3 ) 6 h_swish(x)=x*\frac{ReLU6(x+3)}{6}h _s w i s h (x )=x ∗6 R e L U 6 (x +3 )、h _ s i g m o i d ( x ) = R e L U 6 ( x + 3 ) 6 h_sigmoid(x)=\frac{ReLU6(x+3)}{6}h _s i g m o i d (x )=6 R e L U 6 (x +3 )
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
- common.py文件修改:直接在最下面加入如下代码
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = y.view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class conv_bn_hswish(nn.Module):
"""
This equals to
def conv_3x3_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
h_swish()
)
"""
def __init__(self, c1, c2, stride):
super(conv_bn_hswish, self).__init__()
self.conv = nn.Conv2d(c1, c2, 3, stride, 1, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = h_swish()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class MobileNet_Block(nn.Module):
def __init__(self, inp, oup, hidden_dim, kernel_size, stride, use_se, use_hs):
super(MobileNet_Block, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
if inp == hidden_dim:
self.conv = nn.Sequential(
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim,
bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
SELayer(hidden_dim) if use_se else nn.Sequential(),
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim,
bias=False),
nn.BatchNorm2d(hidden_dim),
SELayer(hidden_dim) if use_se else nn.Sequential(),
h_swish() if use_hs else nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
y = self.conv(x)
if self.identity:
return x + y
else:
return y
- yolo.py文件修改:在yolo.py的
parse_model函数中,加入h_sigmoid, h_swish, SELayer, conv_bn_hswish, MobileNet_Block五个模块 - 新建yaml文件:在model文件下新建
yolov5-mobilenetv3-small.yaml文件,复制以下代码即可
nc: 20
depth_multiple: 1.0
width_multiple: 1.0
anchors:
- [10,13, 16,30, 33,23]
- [30,61, 62,45, 59,119]
- [116,90, 156,198, 373,326]
backbone:
[[-1, 1, conv_bn_hswish, [16, 2]],
[-1, 1, MobileNet_Block, [16, 16, 3, 2, 1, 0]],
[-1, 1, MobileNet_Block, [24, 72, 3, 2, 0, 0]],
[-1, 1, MobileNet_Block, [24, 88, 3, 1, 0, 0]],
[-1, 1, MobileNet_Block, [40, 96, 5, 2, 1, 1]],
[-1, 1, MobileNet_Block, [40, 240, 5, 1, 1, 1]],
[-1, 1, MobileNet_Block, [40, 240, 5, 1, 1, 1]],
[-1, 1, MobileNet_Block, [48, 120, 5, 1, 1, 1]],
[-1, 1, MobileNet_Block, [48, 144, 5, 1, 1, 1]],
[-1, 1, MobileNet_Block, [96, 288, 5, 2, 1, 1]],
[-1, 1, MobileNet_Block, [96, 576, 5, 1, 1, 1]],
[-1, 1, MobileNet_Block, [96, 576, 5, 1, 1, 1]],
]
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]],
[-1, 1, C3, [256, False]],
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]],
[-1, 1, C3, [128, False]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, 16], 1, Concat, [1]],
[-1, 1, C3, [256, False]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, 12], 1, Concat, [1]],
[-1, 1, C3, [512, False]],
[[19, 22, 25], 1, Detect, [nc, anchors]],
]
三、Ghostnet
Han, Kai, et al. “Ghostnet: More features from cheap operations.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
Ghostnet出自 华为诺亚方舟实验室,作者发现在 传统的深度学习网络中存在着大量冗余,但是对模型的精度至关重要的特征图。这些特征图是由卷积操作得到,又输入到下一个卷积层进行运算,这个过程包含大量的网络参数,消耗了大量的计算资源。
作者考虑到这些feature map层中的冗余信息可能是一个成功模型的重要组成部分, 正是因为这些冗余信息才能保证输入数据的全面理解,所以作者在设计轻量化模型的时候并没有试图去除这些冗余feature map,而是 尝试使用更低成本的计算量来获取这些冗余feature map。
Ghost卷积部分将传统卷积操作分为两部分:
- 第一步,使用少量卷积核进行卷积操作(比如正常用64个,这里就用32个,从而减少一半计算量)
- 第二步,使用3×3或5×5的卷积核进行逐通道卷积操作(Cheap operations)
最终将第一部分作为一份恒等映射(Identity),与第二步的结果进行Concat操作
GhostBottleneck部分有两种结构:
- stride=1,不进行下采样时,直接进行两个Ghost卷积操作
- stride=2,进行下采样时,多出来一个步长为2的深度卷积操作
在最新版本的YOLOv5-6.1源码中,作者已经加入了Ghost模块,并在 models/hub/文件夹下,给出了 yolov5s-ghost.yaml文件,因此直接使用即可。
class GhostConv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, g=1, act=True):
super().__init__()
c_ = c2 // 2
self.cv1 = Conv(c1, c_, k, s, None, g, act)
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)
def forward(self, x):
y = self.cv1(x)
return torch.cat([y, self.cv2(y)], 1)
class GhostBottleneck(nn.Module):
def __init__(self, c1, c2, k=3, s=1):
super().__init__()
c_ = c2 // 2
self.conv = nn.Sequential(GhostConv(c1, c_, 1, 1),
DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(),
GhostConv(c_, c2, 1, 1, act=False))
self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False),
Conv(c1, c2, 1, 1, act=False)) if s == 2 else nn.Identity()
def forward(self, x):
return self.conv(x) + self.shortcut(x)
class C3Ghost(C3):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
References
Original: https://blog.csdn.net/weixin_43799388/article/details/123597320
Author: 嗜睡的篠龙
Title: 【魔改YOLOv5-6.x(上)】结合轻量化网络Shufflenetv2、Mobilenetv3和Ghostnet
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/688006/
转载文章受原作者版权保护。转载请注明原作者出处!