

文章目录
*
– pandas在pycharm的安装
– Pandas的数据结构:
– Series
– Series的创建
– Series的内容读取
– Series间的计算
– Series的常用函数、自定义函数
– DataFrame:
– DataFrame创建
– DataFrame内容读取
– DataFrame运算
Pandas简介:
一个用于统计分析常用Python模块,Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。Pandas的基本功能:以字段为单位的数学运算,灵活处理缺失数据合并、连接等关系型运算
这里我们用pycharm进行学习
pandas在pycharm的安装
安装代码
pip insatall pandas

若下载缓慢,则加上清华源后缀
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/

在代码的开头导入pandas即可使用,习惯上,导入pandas后会起一个别名pd
import pandas as pd
Pandas的数据结构:
Series(一维):一维数组,与Python基本的数据结构List相近。
DataFrame(二维):二维的表格型数据结构。可以将DataFrame理解为Series的容器
Series
Series是一种类似于一维数组的对象,它由一组数据以及一组与之相关的数据标签(即索引)组成 ,可以理解为带标签的列表List
Series的创建
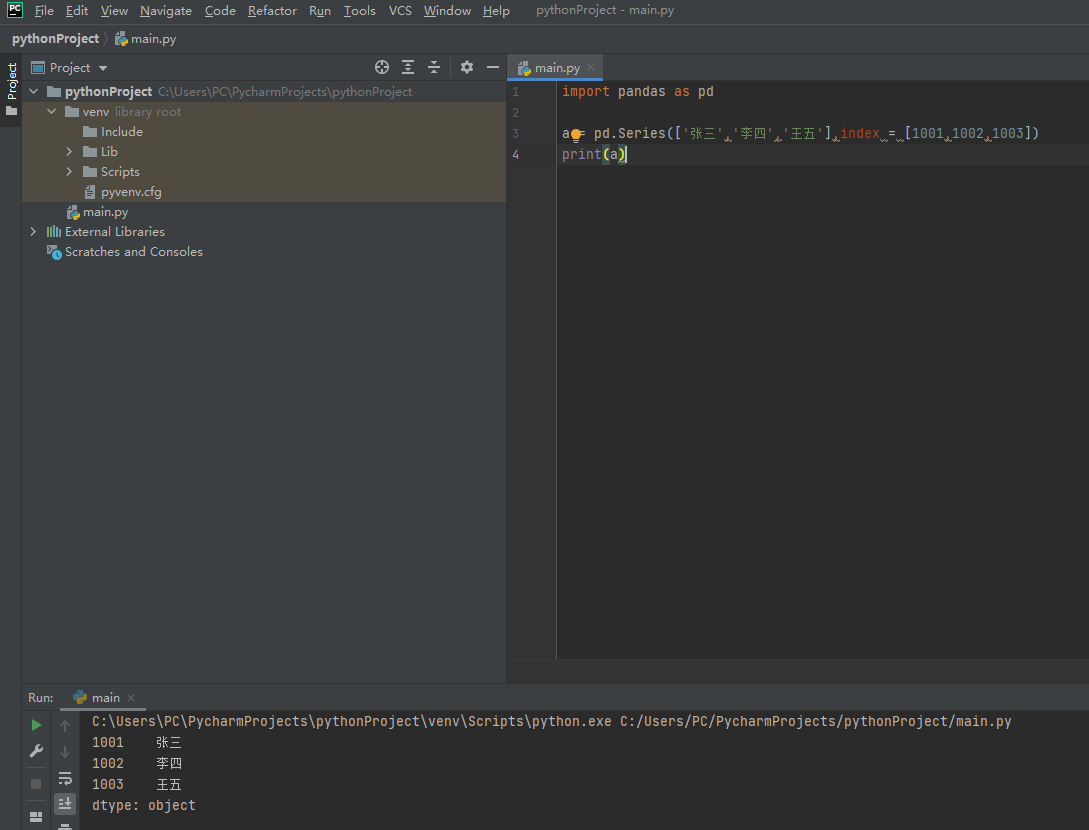
import pandas as pd
a = pd.Series(['张三','李四','王五'],index = [1001,1002,1003])
print(a)
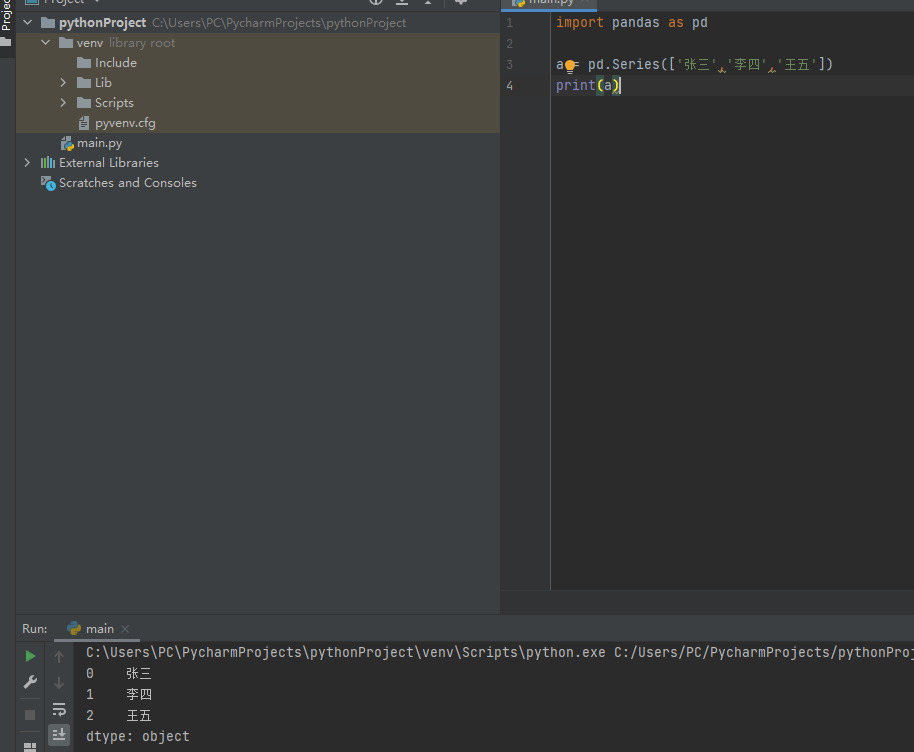
不使用索引,则默认,0开始
import pandas as pd
a = pd.Series(['张三','李四','王五'])
print(a)
字典创建
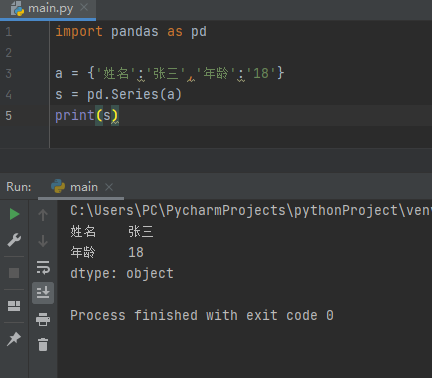
import pandas as pd
a = {'姓名':'张三','年龄':'18'}
s = pd.Series(a)
print(s)
Series的内容读取
1、使用index、values读取索引列表、值列表(注意:它们不是函数;可以转成list格式再使用)
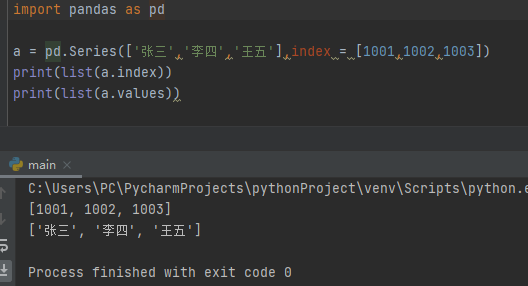
import pandas as pd
a = pd.Series(['张三','李四','王五'],index = [1001,1002,1003])
print(list(a.index))
print(list(a.values))
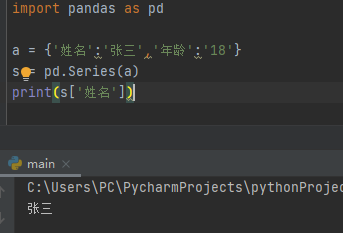
2、2、索引取值,方法和列表或字典相似中括号内如果是标签名,则取对应的值,如果是数字下标,则取对应下标的值
import pandas as pd
a = {'姓名':'张三','年龄':'18'}
s = pd.Series(a)
print(s['姓名'])
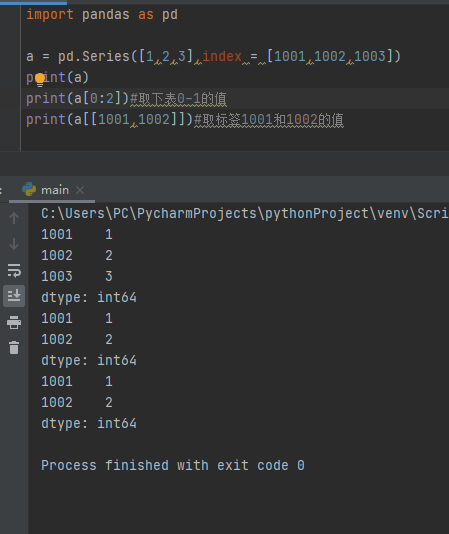
3、若要按下标取值,和索引
Series间的计算
1、加减乘除运算,将对应位置的值计算,若数量不对等,则产生NaN,计算的结果是一个新的Series
import pandas as pd
a = pd.Series([1,2,3])
b = pd.Series([4,5,6])
print(a+b)
2、比较运算,满足条件的,结果为True,不满足的为False,然后组成一个新的Series(此时值已失去,仅剩标签)
import pandas as pd
a = pd.Series([1,2,3])
b = pd.Series([4,5,6])
print(a>=2)
Series的常用函数、自定义函数
1、求和、均值,最大最小值函数
a = pd.Series([1,2,3])
print(a.sum())
print(a.max())
print(a.min())
print(a.mean())
2、自定义函数apply,对每一个值执行相同的操作,相当于map的功能
import pandas as pd
a = pd.Series([1,2,3])
def func(x):
return x*x
print(a.apply(func))
DataFrame:
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)
DataFrame创建
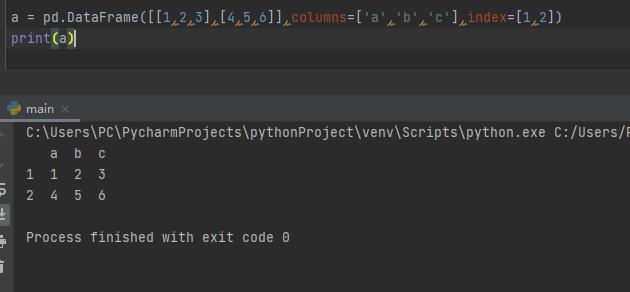
import pandas as pd
a = pd.DataFrame([[1,2,3],[4,5,6]],columns=['a','b','c'],index=[1,2])
print(a)
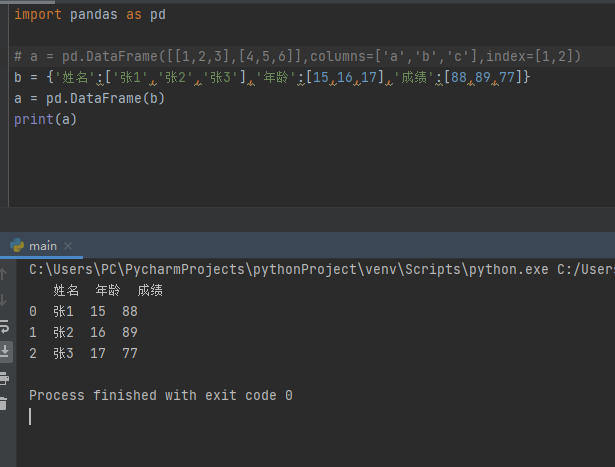
字典创建
import pandas as pd
b = {'姓名':['张1','张2','张3'],'年龄':[15,16,17],'成绩':[88,89,77]}
a = pd.DataFrame(b)
print(a)
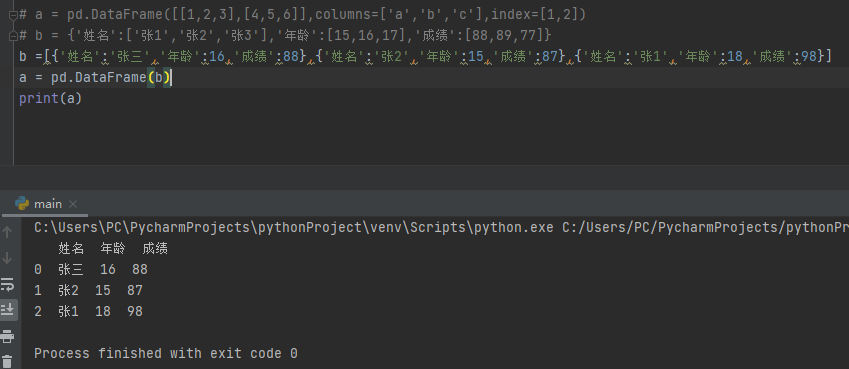
列表字典创建
import pandas as pd
b =[{'姓名':'张三','年龄':16,'成绩':88},{'姓名':'张2','年龄':15,'成绩':87},{'姓名':'张1','年龄':18,'成绩':98}]
a = pd.DataFrame(b)
print(a)
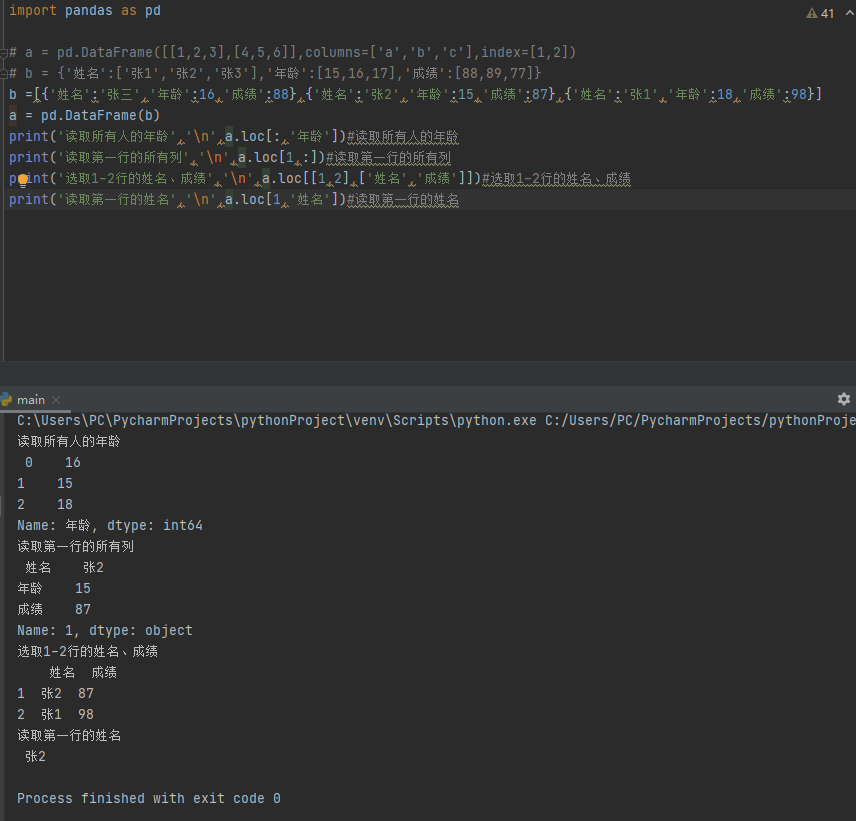
DataFrame内容读取
通用方法:loc按索引取值,iloc按下标取值(少用)
格式:df.loc[ 行索引或范围, 列索引或范围 ]
其中,范围用列表来表示,且可以用冒号: 表示全范围
返回结果:
如果行和列都是范围,结果为dataframe
行和列其中一个是范围,结果为Series
行和列都是一个值,结果为单个元素
import pandas as pd
b =[{'姓名':'张三','年龄':16,'成绩':88},{'姓名':'张2','年龄':15,'成绩':87},{'姓名':'张1','年龄':18,'成绩':98}]
a = pd.DataFrame(b)
print('读取所有人的年龄','\n',a.loc[:,'年龄'])
print('读取第一行的所有列','\n',a.loc[1,:])
print('选取1-2行的姓名、成绩','\n',a.loc[[1,2],['姓名','成绩']])
print('读取第一行的姓名','\n',a.loc[1,'姓名'])
import pandas as pd
b =[{'姓名':'张三','年龄':16,'成绩':88},{'姓名':'张2','年龄':15,'成绩':87},{'姓名':'张1','年龄':18,'成绩':98}]
a = pd.DataFrame(b)
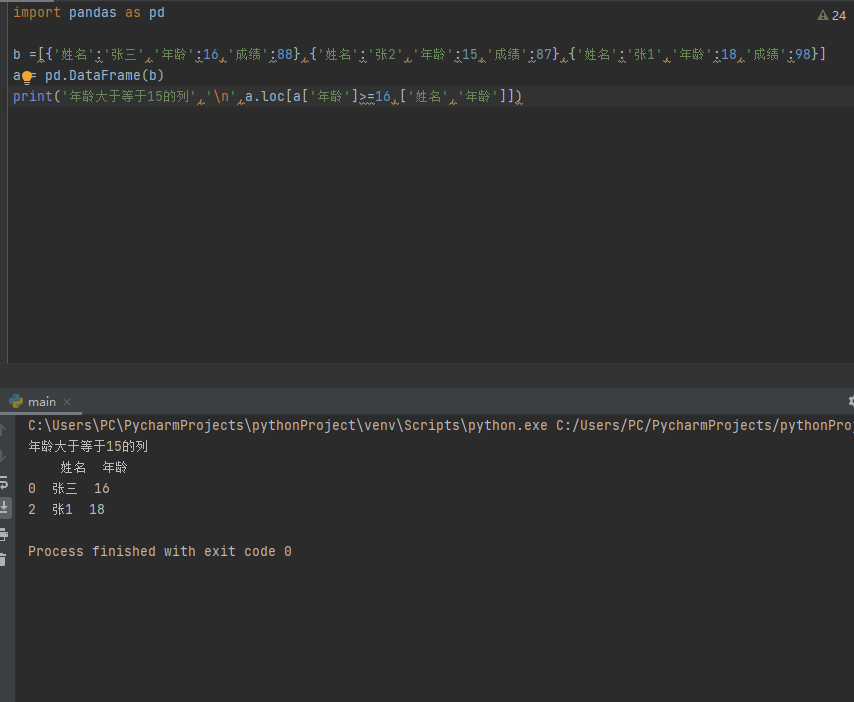
print('年龄大于等于15的列','\n',a.loc[a['年龄']>=16,['姓名','年龄']])
DataFrame运算
Dataframe的加减乘除运算,就是对应位置的Series进行计算
import pandas as pd
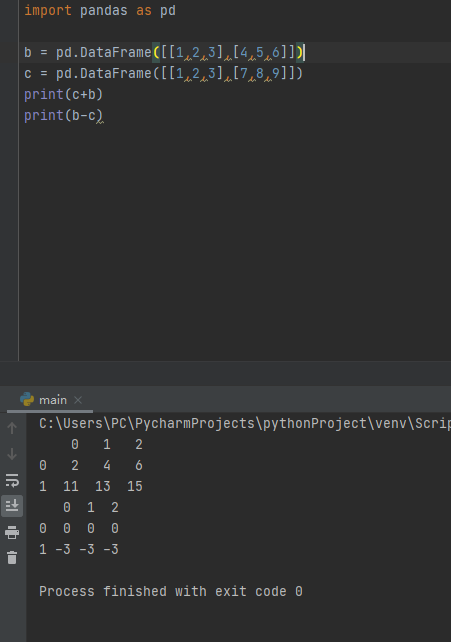
b = pd.DataFrame([[1,2,3],[4,5,6]])
c = pd.DataFrame([[1,2,3],[7,8,9]])
print(c+b)
print(b-c)
import pandas as pd
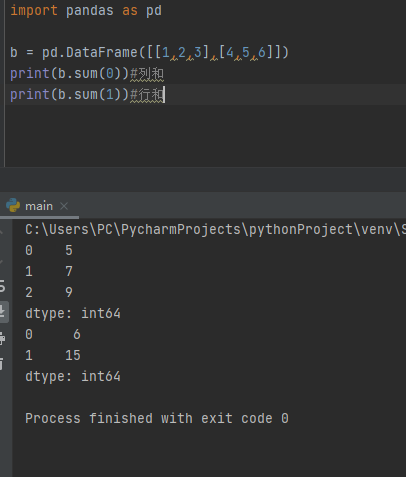
b = pd.DataFrame([[1,2,3],[4,5,6]])
print(b.sum(0))
print(b.sum(1))

DataFrame的常用函数:
自定义函数apply
示例:给df增加一个新的列d,它的值为abc列的值的和
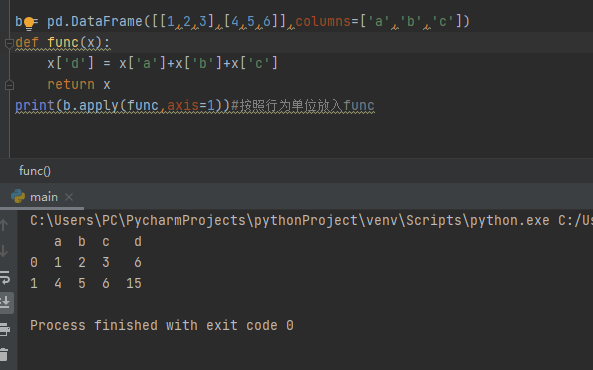
import pandas as pd
b = pd.DataFrame([[1,2,3],[4,5,6]],columns=['a','b','c'])
def func(x):
x['d'] = x['a']+x['b']+x['c']
return x
print(b.apply(func,axis=1))
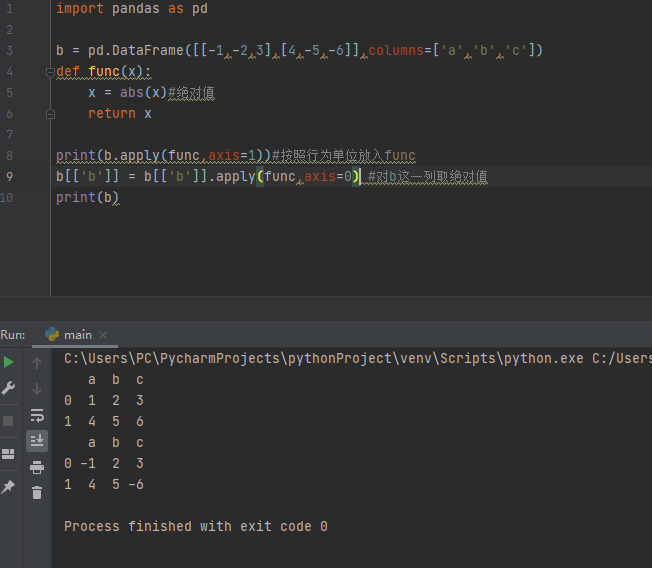
import pandas as pd
b = pd.DataFrame([[-1,-2,3],[4,-5,-6]],columns=['a','b','c'])
def func(x):
x = abs(x)
return x
print(b.apply(func,axis=1))
b[['b']] = b[['b']].apply(func,axis=0)
print(b)
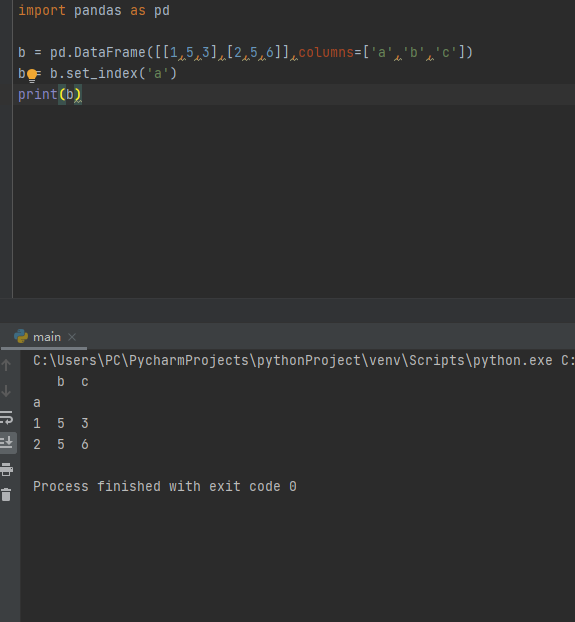
索引对象:
索引对象可以理解为表的主键,DataFrame默认是没有索引对象的,且默认从0开始计数,可以使用set_index函数设置某个字段标签为索引对象
import pandas as pd
b = pd.DataFrame([[1,5,3],[2,5,6]],columns=['a','b','c'])
b = b.set_index('a')
print(b)
Original: https://blog.csdn.net/THREEFUCT/article/details/122315751
Author: 南师大蒜阿熏呀
Title: pandas数据预处理(Series DataFrame)详解附带案例
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678626/
转载文章受原作者版权保护。转载请注明原作者出处!