

1.了解数据重构的方法
2.学会使用groupby作数据运算
什么是数据重构?
数据重构:指数据从一种格式到另一种格式的转换,包括结构转换、格式变化、类型替换等,以解决空间数据在结构、格式和类型上的统一,实现多源和异构数据的联接与融合。
合并数据集 stack
使用pandas进行数据重排时,经常用到stack和unstack两个函数。stack的意思是堆叠,堆积,unstack即”不要堆叠”。
常见的数据层次化结构有:花括号和表格。
表格在行列方向上均有索引(类似于DataFrame)。
花括号结构只有”列方向”上的索引(类似于层次化的Series)。
stack函数会将数据从”表格结构”变成”花括号结构”,即将其行索引变成列索引,反之,unstack函数将数据从”花括号结构”变成”表格结构”,即要将其中一层的列索引变成行索引。
stack:stack函数会将数据从”表格结构”变成”花括号结构” ,将列索引转为行索引,完成层级索引
unstack:unstack函数将数据从”花括号结构”变成”表格结构”,层级索引展开 ,默认操作内层索引
df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2'])
df_obj


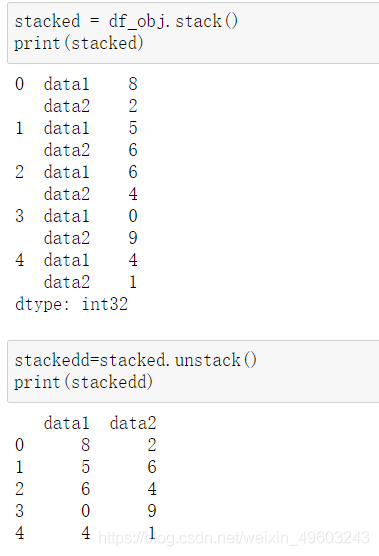
stacked = df_obj.stack()
print(stacked)
stackedd=stacked.unstack()
print(stacked)
代码结果如下所示·:
concat
Pandas中的pd.concat与np.concatenate类似,但可选参数更多,功能更为强大。
pd.concat可以简单地合并一维的对象:
ser1 = pd.Series(['A', 'B', 'C'], index=[1, 2, 3])
ser2 = pd.Series(['D', 'E', 'F'], index=[4, 5, 6])
pd.concat([ser1, ser2])
多维数据合并:
df1 = make_df('AB', [1, 2])
df2 = make_df('AB', [3, 4])
display('df1', 'df2', 'pd.concat([df1, df2])')
numpy中concatenate和pd.concat的很像。
他俩的主要差异就在于pd.concat在合并时会保留索引,即使索引是重复的。但是pandas中也提供了检查重复索引和忽略索引的参数,见上表。
【代码实现】
#构造一个函数,方便后面表示
x = make_df('AB', [0, 1])
y = make_df('AB', [2, 3])
y.index = x.index # 复制索引
display('x', 'y', 'pd.concat([x, y])')
#捕捉索引重复
try:
pd.concat([x, y], verify_integrity=True)
except ValueError as e:
print("ValueError:", e)
#忽略索引
display('x', 'y', 'pd.concat([x, y], ignore_index=True)')
#增加多级索引
display('x', 'y', "pd.concat([x, y], keys=['x', 'y'])")
join
通过索引或者指定的列连接两个DataFrame,通过一个list可以一次高效的连接多个DataFrame。
DataFrame.join(other, on=None, how=’left’, lsuffix=”, rsuffix=”, sort=False)
小结:
DataFrame的join默认为左连接
DataFrame的join连接时,caller的关键列默认为index,可以使用参数on指定别的列为关键列,但是other的关键列永远都是index,所有使用别的列为关键列是,常常使用set_index()
append
append是series和dataframe的方法,使用它就是默认沿着列进行凭借(axis = 0,列对齐)
DataFrame.append(*other*, *ignore_index=False*, *verify_integrity=False*, *sort=None*)
merge
pd.merge()函数可实现可实现三种数据连接:一对一、多对一和多对多。
一对一连接
df1 = pd.DataFrame({'employee': ['Bob', 'Jake', 'Lisa', 'Sue'],
'group': ['Accounting', 'Engineering', 'Engineering', 'HR']})
df2 = pd.DataFrame({'employee': ['Lisa', 'Bob', 'Jake', 'Sue'],
'hire_date': [2004, 2008, 2012, 2014]})
display('df1', 'df2')
df3 = pd.merge(df1, df2)
df3
多对一连接
df4 = pd.DataFrame({'group': ['Accounting', 'Engineering', 'HR'],
'supervisor': ['Carly', 'Guido', 'Steve']})
display('df3', 'df4', 'pd.merge(df3, df4)')
多对多连接
df5 = pd.DataFrame({'group': ['Accounting', 'Accounting',
'Engineering', 'Engineering', 'HR', 'HR'],
'skills': ['math', 'spreadsheets', 'coding', 'linux',
'spreadsheets', 'organization']})
display('df1', 'df5', "pd.merge(df1, df5)")
实战部分:
#导入数据
import numpy as np
import pandas as pd
载入data文件中的:train-left-up.csv
df=pd.read_csv(r'.\data\train-left-up.csv')
df.head()
数据的合并
任务一:将data文件夹里面的所有数据都载入,观察数据的之间的关系
text_left_up = pd.read_csv("data/train-left-up.csv")
text_left_down = pd.read_csv("data/train-left-down.csv")
text_right_up = pd.read_csv("data/train-right-up.csv")
text_right_down = pd.read_csv("data/train-right-down.csv")
任务二:使用concat方法:将数据train-left-up.csv和train-right-up.csv横向合并为一张表,并保存这张表为result_up
list_up = [text_left_up,text_right_up]
result_up = pd.concat(list_up,axis=1)
result_up.head()
任务三:使用concat方法:将train-left-down和train-right-down横向合并为一张表,并保存这张表为result_down。然后将上边的result_up和result_down纵向合并为result。
list_down=[text_left_down,text_right_down]
result_down = pd.concat(list_down,axis=1)
result = pd.concat([result_up,result_down])
result.head()
任务四:使用DataFrame自带的方法join方法和append:完成任务二和任务三的任务
resul_up = text_left_up.join(text_right_up)
result_down = text_left_down.join(text_right_down)
result = result_up.append(result_down)
result.head()
任务五:使用Panads的merge方法和DataFrame的append方法:完成任务二和任务三的任务
result_up = pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down = pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
result = resul_up.append(result_down)
result.head()
任务六:完成的数据保存为result.csv
result.to_csv('result.csv')
任务七:将我们的数据变为Series类型的数据
unit_result=text.stack().head(20)
groupby
groupby()用法:
根据DataFrame本身的某一列或多列内容进行分组聚合
若按某一列聚合,则新DataFrame将根据某一列的内容分为不同的维度进行拆解,同时将同一维度的再进行聚合。
若按某多列聚合,则新DataFrame将是多列之间维度的笛卡尔积,例如:”key1″列,有a和b两个维度,而”key2″有one和two两个维度,则按”key1″列和”key2″聚合之后,新DataFrame将有四个group;
注意:groupby默认是在axis=0上进行分组的,通过设置axis=1,也可以在其他任何轴上进行分组。
任务一:计算泰坦尼克号男性与女性的平均票价
df = text['Fare'].groupby(text['Sex'])
means = df.mean()
means
任务二:统计泰坦尼克号中男女的存活人数
survived_sex = text['Survived'].groupby(text['Sex']).sum()
survived_sex.head()
任务三:计算客舱不同等级的存活人数
survived_pclass = text['Survived'].groupby(text['Pclass'])
survived_pclass.sum()
任务四:统计在不同等级的票中的不同年龄的船票花费的平均值
text.groupby(['Pclass','Age'])['Fare'].mean().head()
任务五:将任务二和任务三的数据合并
result = pd.merge(means,survived_sex,on='Sex')
result
任务六:得出不同年龄的总的存活人数,然后找出存活人数的最高的年龄,最后计算存活人数最高的存活率(存活人数/总人数)
#不同年龄的存活人数
survived_age = text['Survived'].groupby(text['Age']).sum()
survived_age.head()
#找出最大值的年龄段
survived_age[survived_age.values==survived_age.max()]
_sum = text['Survived'].sum()
print(_sum)
#首先计算总人数
_sum = text['Survived'].sum()
print("sum of person:"+str(_sum))
precetn =survived_age.max()/_sum
print("最大存活率:"+str(precetn))
Original: https://blog.csdn.net/weixin_44964457/article/details/118863103
Author: 小新儿
Title: 第二章:02数据重构
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678474/
转载文章受原作者版权保护。转载请注明原作者出处!