



◆ ◆ ◆ ◆ ◆
我是需求
有人问了我一个这样的问题,题目是:……。直接上图吧~
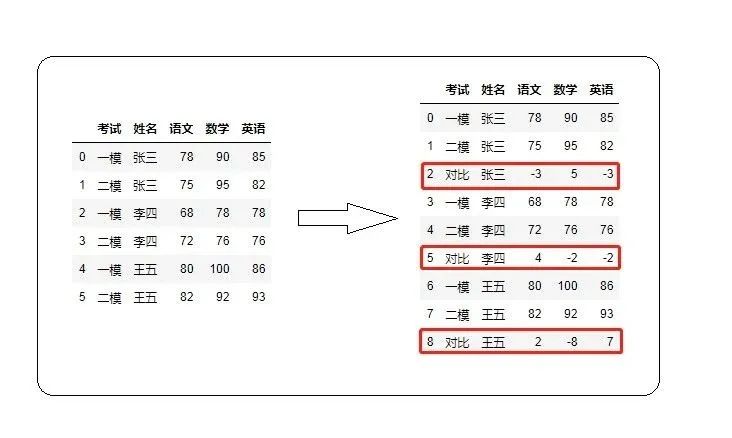
总之一句话,给我
求出每名同学两次模拟考试的成绩涨跌情况 我来安排 1.造点假数据
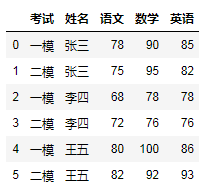
import pandas as pddata = {'考试':['一模','二模','一模','二模','一模','二模'], '姓名':['张三','张三','李四','李四','王五','王五'], '语文':[78,75,68,72,80,82], '数学':[90,95,78,76,100,92], '英语':[85,82,78,76,86,93]}df = pd.DataFrame(data)df
#方法一#
2.1先分组求首尾数据之差
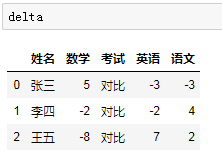
一定要深刻体会groupby后加的字段的不同delta = df.groupby('姓名')['考试','语文','数学','英语'].last() - df.groupby('姓名')['语文','数学','英语'].first()# 重设索引,使姓名列恢复列字段delta.reset_index(inplace = True)# 填充为对比,满足需求的每一个小细节delta.fillna('对比',inplace=True)# 输出瞧一瞧delta
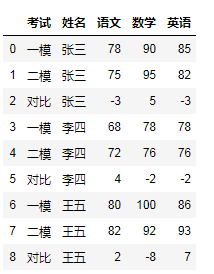
3.1使用append添加结果进去
这种方式是可以设置ignore_index = Truedf.append(delta,ignore_index = True,sort = False).sort_values('姓名').reset_index(drop=True)
#方法二#
2.2先分组使用diff( )方法求差值
delta = df.groupby('姓名').diff().dropna()delta
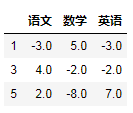
3.2使用append添加结果进去
# 这种方式必须设置ignore_index = False,否则在索引排序时就会匹配不到结果df.append(delta,ignore_index = False,sort = False).sort_index().fillna({'考试':'对比'}).fillna(method = 'ffill')
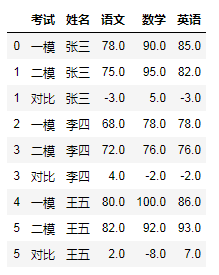
上图结果可以看到,我们利用了索引的一个排序,完成了差值的匹配。当然,可以使用重设索引来更新一下。好了,完成–!!!

在看
, 否则没有动力原创啊!跪谢~ 我是总结
本文讲解了这几大需要掌握的知识点: 1.深入理解分组聚合的众多妙处。 2.不同参数对结果的影响。 3.append方法,fillna方法,diff方法的使用。
— END —
更
多
精
彩
Python 进阶编程之字典的高级用法
Python实现行转列?!超简单,赶快get起来
Python一行命令生成数据分析报告

在看
“的永远18岁~

Original: https://blog.csdn.net/weixin_36362920/article/details/112414660
Author: 比个那噶
Title: df添加一行 python_Python之pandas实现更复杂的Excel操作
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/678305/
转载文章受原作者版权保护。转载请注明原作者出处!