

分组聚合与数据可视化
- 一、分组聚合
* - 1.1、单层分组聚合:df.groupby(by)[‘列索引’].mean()。
– - 1.2、 多层分组聚合:df.groupby(by)[‘列索引’].mean()。
- 二、数据可视化
* - 2.1绘制单条折线图:s.plot()
– - 2.2绘制多条折线图:df.plot()
- 2.3绘制其它类型图
–
一、分组聚合
1.1分组聚合操作的定义
分组聚合操作指的是按照某项规则对数据进行分组,接着对分完组的数据执行总结性统计的操作(比如求和、求均值)。根据其分组方式的不同可以分为 单层分组聚合操作以及 多层分组聚合操作。
1.1、单层分组聚合:df.groupby(by)[‘列索引’].mean()。
单层分组聚合操作指的是针对某一个组进行聚合操作。
In [ 3 ]
1
2 grade_df = pd.DataFrame({'班级': [1, 1, 1, 1, 1, 2, 2, 2, 2, 2],
3
'性别': ['男', '男', '女', '女', '女', '男', '男', '男', '女', '女'],
4
'眼镜': ['是', '否', '是', '否', '是', '是', '是', '否', '否', '否'],
5
'成绩': [95, 90, 96, 92, 94, 85, 87, 80, 81, 86]})
6
7 grade_df
Out [ 3 ]
班级 性别 眼镜 成绩
0 1 男 是 95
1 1 男 否 90
2 1 女 是 96
3 1 女 否 92
4 1 女 是 94
5 2 男 是 85
6 2 男 是 87
7 2 男 否 80
8 2 女 否 81
9 2 女 否 86
grade– [ɡreɪd] –等级、 mean– [miːn]–v.意思是,n.中间,adj.小气的
group–[ɡruːp]–组、by–[baɪ]–通过;经过
例:
In [ 5 ]
1
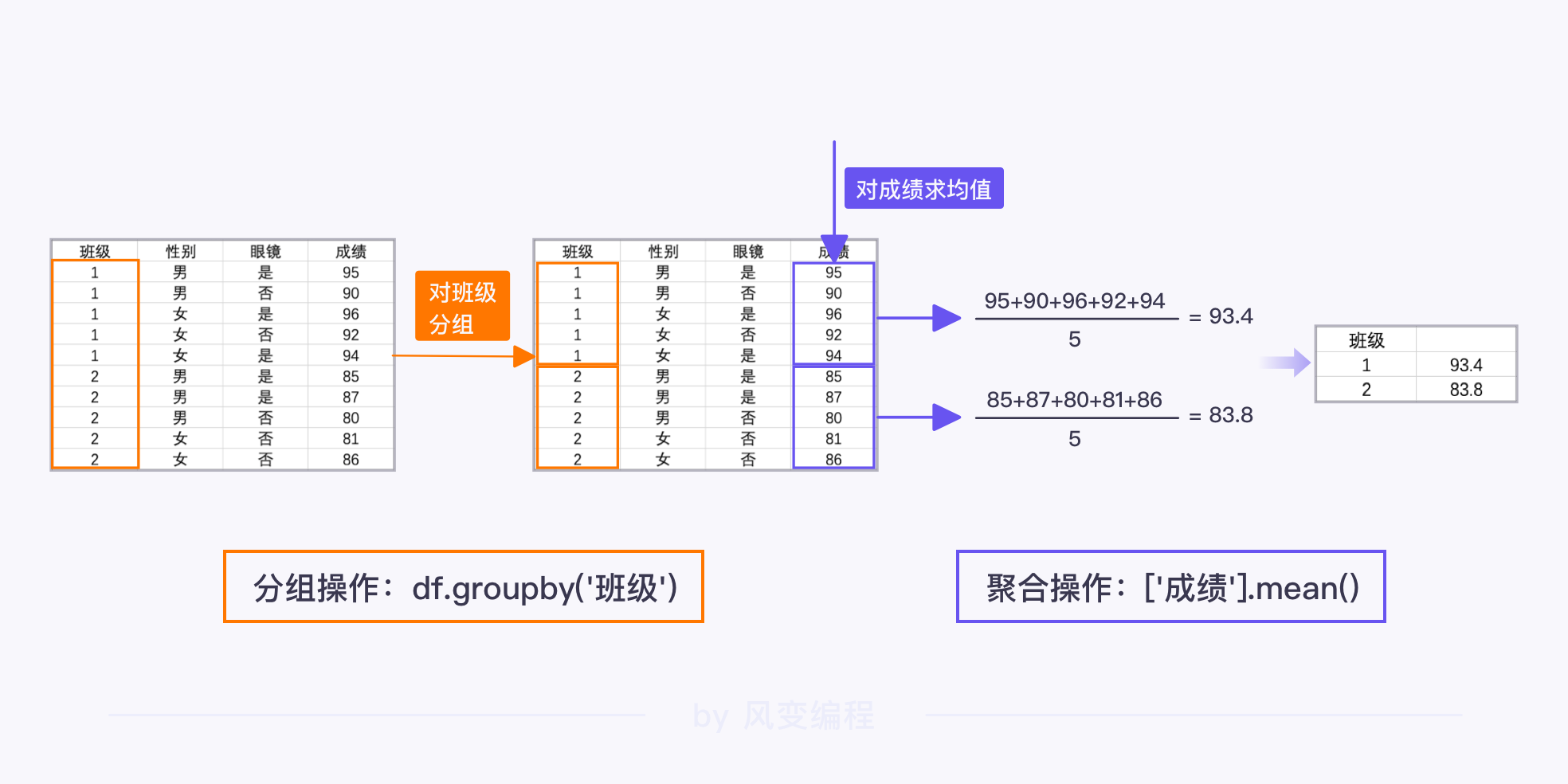
2 grade_df1 = grade_df.groupby('班级')['成绩'].mean()
3
4 grade_df1
Out [ 5 ]
班级
1 93.4
2 83.8
Name: 成绩, dtype: float64
分组聚合操作返回的是一个 Series 对象, 但它的索引会多一个名字,如上面的 班级因为是对班级这一列进行分组的。
1.1.1单层分组:df.groupby(by)
参数 by: 要对哪一列数据进行分组操作,就把列名传给参数,如:’班级’
单层分组操作只能根据一列数据进行分组。
1.1.2聚合操作:[‘列索引’].mean()
‘列索引’指的是需要对哪一列数据进行聚合操作,如要对成绩这一列数据进行聚合操作,就可以将’成绩’传给’列索引’
mean() 指求平均值
聚合操作的其它参数:
sum– [sʌm] –总和
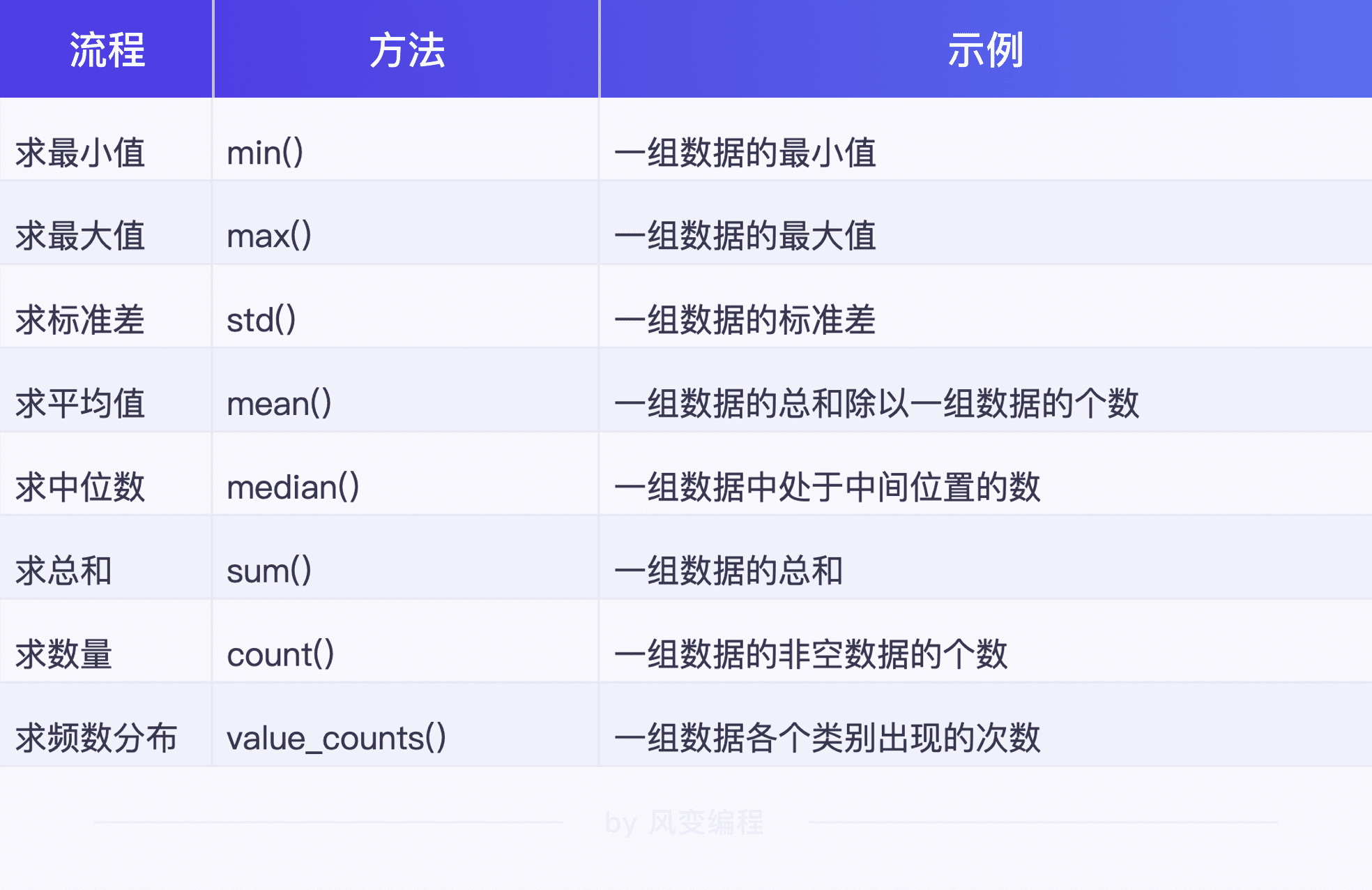

中位数: 当我们对一组数据从小到大排列以后,处于中间位置的数就是中位数。
分组聚合效果图如下:
; 1.2、 多层分组聚合:df.groupby(by)[‘列索引’].mean()。
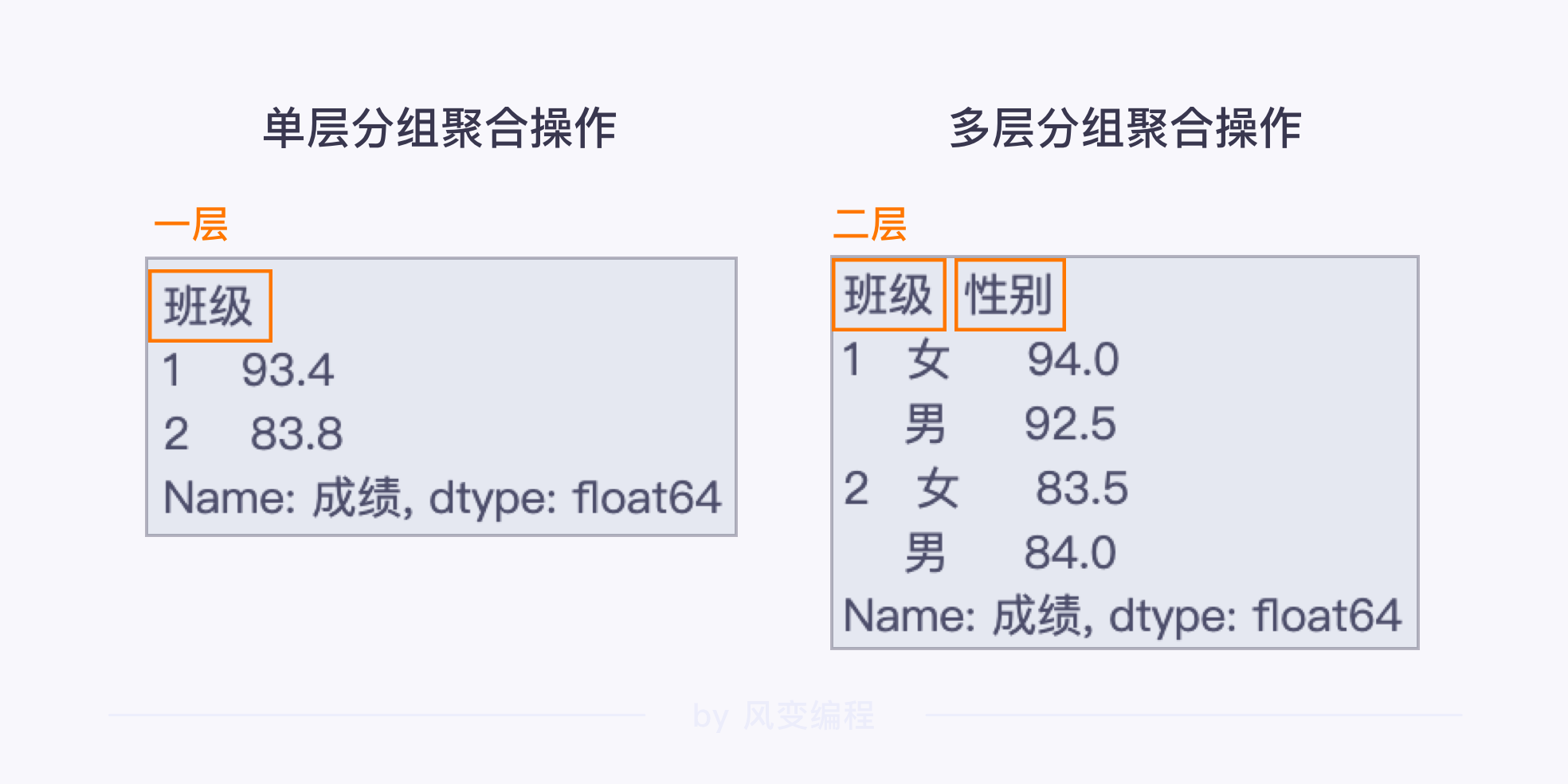
例:grade_df3 = grade_df.groupby([‘班级’, ‘性别’])[‘成绩’].mean()
多层分组聚合和单层分组聚合相比,代码是相同的
多层分组聚合操作返回的也是一个 Series 对象,唯一的不同点在于索引的层数上。
而多层分组聚合操作的索引至少有两层。
这些列索引在传进参数 by 之前,需要先被放进一个”容器”里,这个容器可以是列表。
分组的顺序和列表中的参数是对应的(从左往右依次拆分)。
In [ 15 ]
1
2 grade_df3 = grade_df.groupby(['班级', '性别'])['成绩'].mean()
3
4 grade_df3
运行
Out [ 15 ]
班级 性别
1 女 94.0
男 92.5
2 女 83.5
男 84.0
Name: 成绩, dtype: float64
如:想要在原先分组的基础上,再对’眼镜’这一列进行拆分,看看尖子生是不是更容易出现在戴眼镜的学生群体中:

运行后的结果:
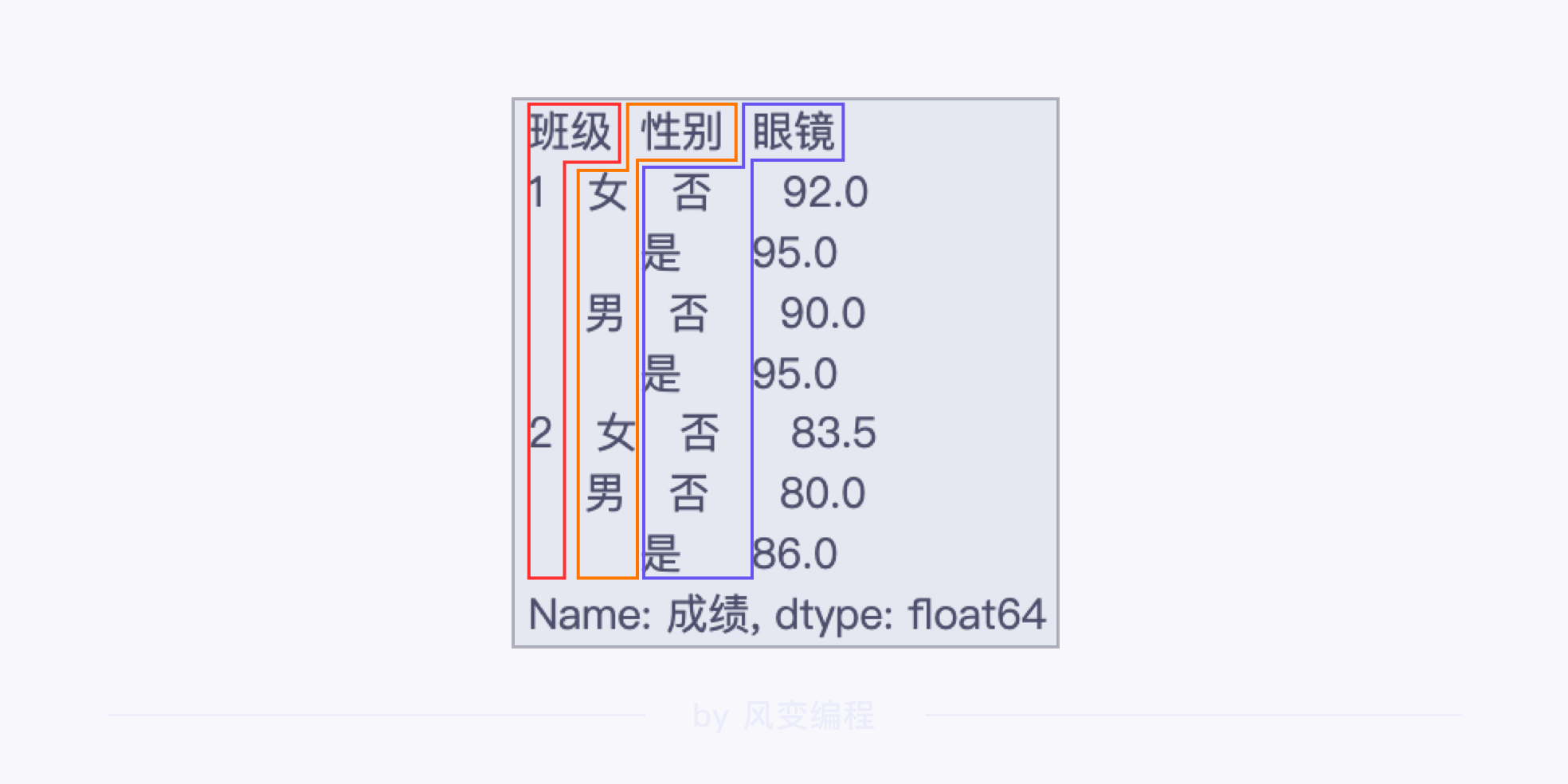
所有的组别信息都扎堆出现在了一个 Series 对象的索引中,看起来有点儿乱。
而通过 s.unstack() 函数,可以将一个多层分组聚合后的 Series 对象转变成 DataFrame 对象。s.unstack() 这个方法是针对多层分组聚合后的 Series 对象来使用的。
unstack--解开、us--[ˌjuː ˈen] 、stack--[stæk] --堆栈

s.unstack() 函数的作用就是将其索引的最后一列转变成 DataFrame 对象的列索引,而剩下的索引则转变成 DataFrame 对象的行索引。

或者:grade_df6 = grade_df.groupby([‘班级’, ‘性别’, ‘眼镜’,])[‘成绩’].mean().unstack()
二、数据可视化
2.1绘制单条折线图:s.plot()
pandas 库是根据一个更加底层的绘图库——matplotlib,封装而来,如图形中须支持中文,要想让 pandas 库能够支持中文字体,需要先让 matplotlib 库能够支持中文字体。
2.1.1为 matplotlib 库添加中文字体
mat– [mæt]–垫子、plot–[plɒt] –情节、lib– [lɪb]
例:
from matplotlib import pyplot as plt
plt.rcParams['font.family'] = ['要设置的字体']
plt.rcParams[‘font.family’] 可以获取 matplotlib 库中的字体
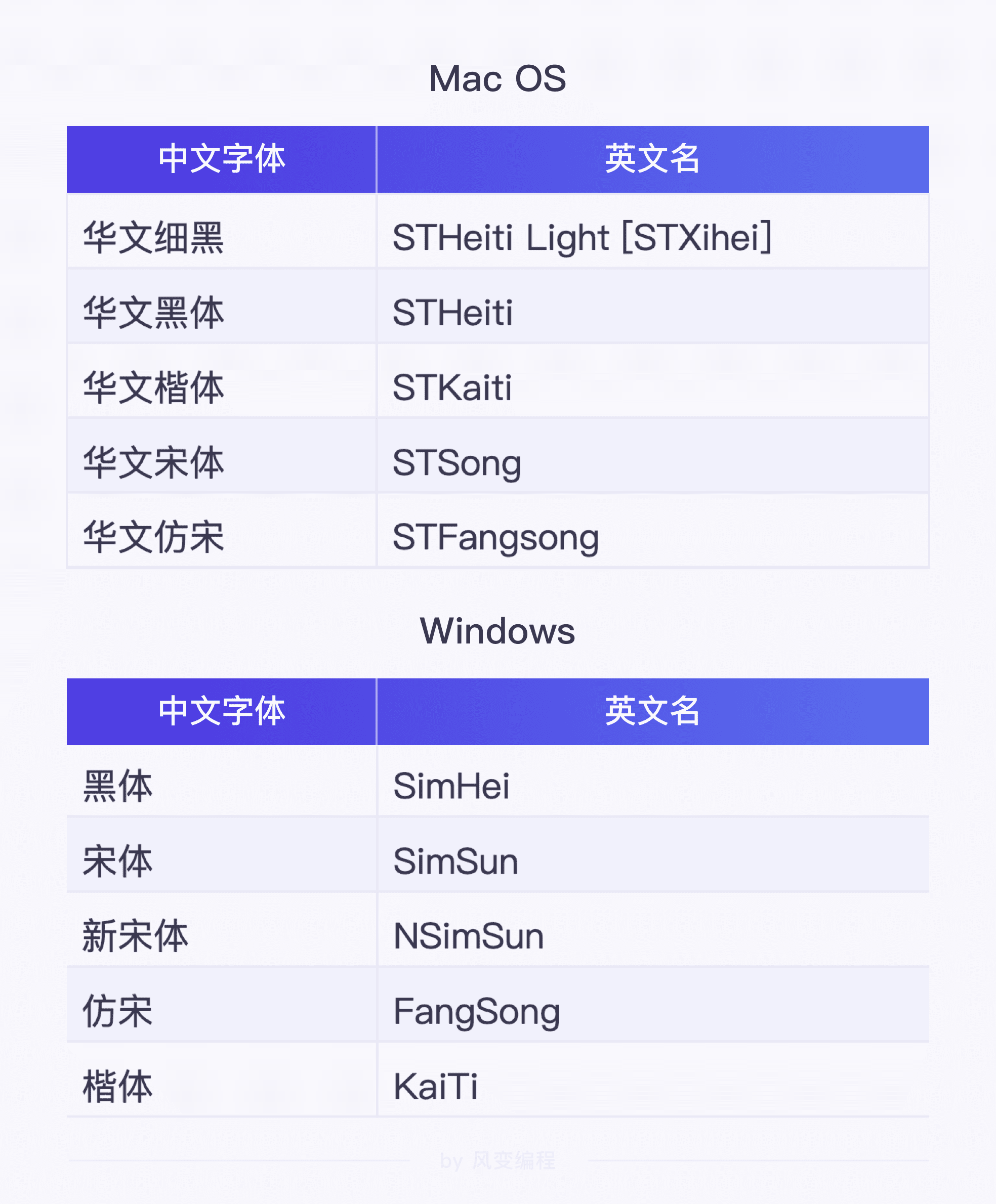
需要导入什么字体, 见下表Windows 和 Mac OS 系统下的常用中文字体。
2.1.2 绘图
绘制单条折线图的函数是:s.plot()
s.plot()常用参数见下表:
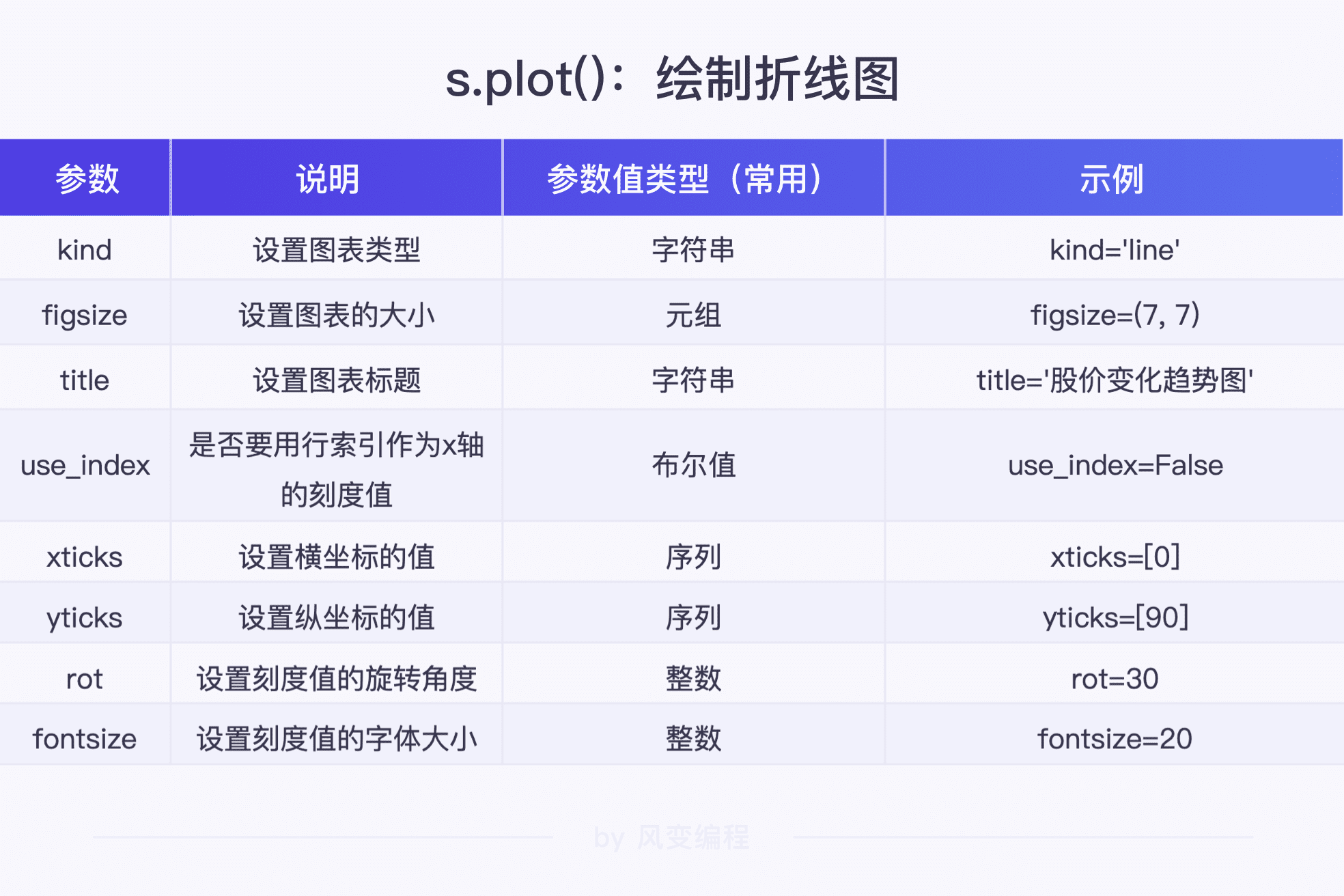
其中参数 kind 指的是图表类型。如果我们要绘制折线图,可以将 ‘line’ 传递给参数 kind。
代码示例:
kind-- [kaɪnd] -- 种类;同类的人(或事物)、 line-- [laɪn]--线;线条;界线
title--[ˈtaɪtl]--标题
li_jian = pd.Series([80, 85, 89, 91, 88, 95],
index=['2月', '3月', '4月', '5月', '6月', '7月'])
li_jian.plot(kind='line', figsize=(6, 7), title='李健月考成绩')
参数 figsize=(6,7)为代表图像宽和高的一个元组,前面6为宽,后面7为高,单位是英寸。
2.2绘制多条折线图:df.plot()
多条折线图是针对一个 DataFrame 对象来绘制的,而单条折线图是针对一个 Series 对象来绘制的。df.plot() 默认会将每一列数据用 s.plot() 绘制成单条折线图,然后合并到同一张图上。
s.plot() 和df.plot()的参数都是可以通用的,效果也相同。
代码示例:
In [ 46 ]
1
2 students_grade = pd.DataFrame({'李健': [80, 85, 89, 91, 88, 95],
3
'王聪': [95, 92, 90, 85, 75, 80],
4
'过凡': [90, 91, 92, 91, 90, 91]
5
}, index=['2月', '3月', '4月', '5月', '6月', '7月'])
6
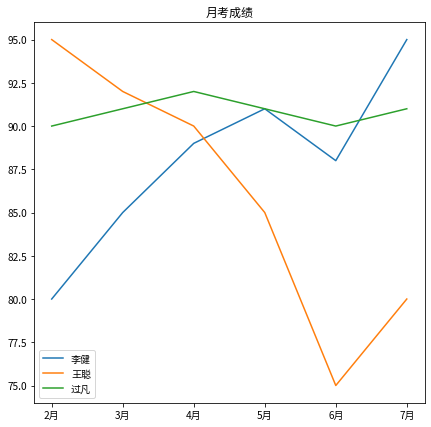
7 students_grade.plot(kind='line', figsize=(7, 7), title='月考成绩')
Out [ 46 ]
AxesSubplot:title={‘center’:’月考成绩’}
还可以通过调用Series和DF的属性与方法,取出行和列来设置X、Y轴坐标来绘图,如:
x = s.index #查看索引 y=s.values #查看数值
x = df.index y=df.values #查看数值
绘图详细教程见
数据分析之数据展现—用matplotlib 库绘制图形
2.3绘制其它类型图
2.3.1饼图
代码示例:
my_data = pd.read_csv('./工作/clean_data.csv', encoding='utf-8')
profession = my_data['行业'].value_counts()/my_data['行业'].value_counts().sum()
profession.plot(kind='pie', autopct='%.2f%%', figsize=(7, 7), title='行业频率分布图', label='')
2.3.2条形图
代码示例:
position = my_data['岗位'].value_counts()/my_data['岗位'].value_counts().sum()
position.plot(kind='bar', figsize=(13, 6), title='岗位频率分布条形图')
Original: https://blog.csdn.net/weixin_53823523/article/details/119715703
Author: 随风的博客
Title: 数据分析三、pandas库 分组聚合与数据可视化
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/677435/
转载文章受原作者版权保护。转载请注明原作者出处!