

文章目录
- 一、Pandas简介
- 二、pandas数据结构
- 三、Series
* - 3.1 Series的创建
– - 3.2 Series的取值和赋值
– - 四、DataFrame
* - 4.1 DataFrame类型的创建
– - 4.2 DataFrame基本属性和整体情况查询
- 4.3 DataFrame的索引
– - 4.4 Dataframe的赋值
- 五、多层索引
* - 5.1 Series多层索引
- 5.2 DataFrame多层索引
- 5.3 按索引层级统计数据
B站视频讲解:
https://www.bilibili.com/video/BV1FM411M72z
; 一、Pandas简介
Pandas官网:https://pandas.pydata.org/

pandas 是一个基于 Numpy 构建, 开源的强大的数据分析工具包。
Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。
Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。Pandas直译为”熊猫”,所以有时看网上的某些数据分析文章时会出现熊猫的说法,其实说的就是Pandas。
Pandas主要功能:
- 独特的数据结构 DataFrame, Series
- 集成时间序列功能
- 提供丰富的数学运算操作
- 灵活处理缺失数据
; 二、pandas数据结构
- Series:一种类似于一维数组的对象,它是由一组数据(各种Numpy数据类型以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生简单的Series。
- DataFrame:一个表格型的数据结构,含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等),DataFrame既有行索引也有列索引,可以被看做是由Series组成的字典。

三、Series

; 3.1 Series的创建
3.1.1 通过一维数组创建Series
Series对象本质上是由两个数组构成,一个数组构成对象的键(index索引),一个数组构成对象的值(values)
import numpy as np
import pandas as pd
s1 = pd.Series([4, 7 ,5, -3], index=['a', 'b', 'c', 'd'])
print(s1)
s2 = pd.Series([4, 7 ,5, -3])
print(s2)
输出结果:
a 4
b 7
c 5
d -3
dtype: int64
0 4
1 7
2 5
3 -3
dtype: int64
3.1.2 通过字典的方式创建Series
s3 = pd.Series({'a':1, 'b': 2, 'c': 10, 'd': 20})
print(s3)
输出结果:
a 1
b 2
c 10
d 20
dtype: int64
3.1.3 创建标量值序列,index表达Series类型的尺寸
s4 = pd.Series(60, index=['a', 'b', 'c', 'd'])
print(s4)
输出结果:
a 60
b 60
c 60
d 60
dtype: int64
3.2 Series的取值和赋值
3.2.1 获取值数组和索引数组
s4 = pd.Series(60, index=['a', 'b', 'c', 'd'])
print(s4.values, type(s4.values), list(s4.values))
print(s4.index, type(s4.index), list(s4.index))
输出结果:
[60 60 60 60] <class 'numpy.ndarray'> [60, 60, 60, 60]
Index(['a', 'b', 'c', 'd'], dtype='object') <class 'pandas.core.indexes.base.Index'> ['a', 'b', 'c', 'd']
3.2.2 Series 支持numpy数组array的特性 – 下标操作
3.2.2.1 Series切片和索引
注意:
Pandas中的非整数索引,切片时左右均为闭区间,就是首尾都包含,不同于Python中的切片
Pandas中的整数索引,切片时为左闭右开区间,就是顾头不顾尾,与Python中的切片相同
s1 = pd.Series({'a':1, 'b': 2, 'c': 10, 'd': 20})
print(s1['a'] , '\n' + '---------')
print(s1[[0,1,3]], '\n' + '---------')
print(s1['a':'c'], '\n' + '---------')
print(s1[0:2], '\n' + '---------')
print(s1[0:4:2], '\n' + '---------')
输出结果:
1
a 1
b 2
c 10
dtype: int64
a 1
c 10
dtype: int64
a 1
b 2
c 10
dtype: int64
1
a 1
c 10
dtype: int64
a 2.0
b 4.0
c NaN
d 40.0
e NaN
dtype: float64
a 1
b 3
c 13
d 33
dtype: int64
3.2.4 Series缺失数据处理
- 缺失数据:使用NaN(Not a Number)来表示缺失数据。其值等于np.nan。内置的None值也会被当做NaN处理。
-
pandas缺失数据的检测
-
pd.isnull() / pd.isna() # 检测是否是缺失值,返回布尔数组,缺失值对应为True
- pd.notnull() / pd.notna() # 检测是否是非缺失值,返回布尔数组,缺失值对应为False
s2 = pd.Series({'a':1, 'b': 2, 'd': 20, 'e': 30})
s3 = pd.Series({'a':1, 'b': 2, 'c': 10, 'd': 20})
print(pd.isnull(s2+s3))
print(pd.isna(s2+s3))
print(pd.notnull(s2+s3))
print(pd.notna(s2+s3))
输出结果:
a False
b False
c True
d False
e True
dtype: bool
a False
b False
c True
d False
e True
dtype: bool
a True
b True
c False
d True
e False
dtype: bool
a True
b True
c False
d True
e False
dtype: bool
-
缺失数据的处理
-
sr.dropna() 或 sr[sr.notnull()]过滤掉值为NaN的行
- sr.fillna(0) 填充缺失数据
s2 = pd.Series({'a':1, 'b': 2, 'd': 20, 'e': 30})
s3 = pd.Series({'a':1, 'b': 2, 'c': 10, 'd': 20})
print((s2+s3).dropna())
print((s2+s3)[(s2+s3).notnull()])
print((s2+s3).fillna(0))
print((s2+s3).fillna(99999))
print((s2+s3).fillna('ssssss'))
输出结果:
a 2.0
b 4.0
d 40.0
dtype: float64
a 2.0
b 4.0
d 40.0
dtype: float64
a 2.0
b 4.0
c 0.0
d 40.0
e 0.0
dtype: float64
a 2.0
b 4.0
c 99999.0
d 40.0
e 99999.0
dtype: float64
a 2.0
b 4.0
c ssssss
d 40.0
e ssssss
dtype: object
四、DataFrame
dataframe是一种二维数据结构,数据以表格形式(与excel类似)存储,有对应的行和列。
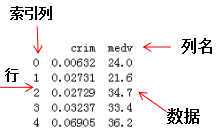
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
; 4.1 DataFrame类型的创建
4.1.1 通过二维ndarray对象创建DF
df = pd.DataFrame(np.arange(10).reshape(2, 5))
print(df)
输出结果:
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
4.1.2 通过二维 列表/元组 创建DF,每个内层 列表/元组 为一行
df1 = pd.DataFrame([['Tom', 'Merry', 'John'],[76, np.nan]])
arr = (('Tom',76),['Merry',98],['Merry',100])
df2 = pd.DataFrame(arr)
df3 = pd.DataFrame(arr, index=['A', 'B', 'C'], columns=['name', 'score'])
print(df1)
print(df2)
print(df3)
输出结果:
0 1 2
0 Tom Merry John
1 76 NaN None
0 1
0 Tom 76
1 Merry 98
2 Merry 100
name score
A Tom 76
B Merry 98
C Merry 100
4.1.3 通过字典的方式创建DF
- 直接使用pd.DataFrame(data=test_dict)即可,括号中的data=写不写都可以
-
使用from_dict方法,两种方法结果与是一样的
-
字典key为Columns,values元素个数相同
dict= {
"Fruit": ["Apples", "Oranges", "Bananas", "Apples", "Oranges", "Bananas"],
"Amount": [4, 1, 2, 2, 4, 5],
"City": ["SF", "SF", "SF", "Montreal", "Montreal", "Montreal"]
}
df = pd.DataFrame(dict, index=list('ABCDEF'))
df1 = pd.DataFrame.from_dict(dict)
print(df)
print(df1)
print(df.index, type(df.index))
print(df.columns, type(df.columns))
print(df.values, type(df.values))
输出结果:
Fruit Amount City
A Apples 4 SF
B Oranges 1 SF
C Bananas 2 SF
D Apples 2 Montreal
E Oranges 4 Montreal
F Bananas 5 Montreal
Fruit Amount City
0 Apples 4 SF
1 Oranges 1 SF
2 Bananas 2 SF
3 Apples 2 Montreal
4 Oranges 4 Montreal
5 Bananas 5 Montreal
Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object') <class 'pandas.core.indexes.base.Index'>
Index(['Fruit', 'Amount', 'City'], dtype='object') <class 'pandas.core.indexes.base.Index'>
[['Apples' 4 'SF']
['Oranges' 1 'SF']
['Bananas' 2 'SF']
['Apples' 2 'Montreal']
['Oranges' 4 'Montreal']
['Bananas' 5 'Montreal']] <class 'numpy.ndarray'>
- 传递一个能够被转换成类似序列结构的字典对象来创建一 个 DF ,遵循广播机制(要么一个元素会被广播到所有行,要么保持元素个数相同)
df = pd.DataFrame({ 'A' : 1.,
'B' : pd.Timestamp('20130102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","trai n","test","train"]),
'F' : 'foo' })
print(df)
输出结果:
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 trai n foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
4.1.4 通过Series创建,每个Series为一行
s1 = pd.Series([101, '鲁班', '18', '150.00', '男'])
s2 = pd.Series([102, '小乔', '19', '167.00', '女'])
s3 = pd.Series([103, '关羽', '30', '180.00', '男'])
s4 = pd.Series([104, '大乔', '20', '170.00', '女'])
s5 = pd.Series([105, '孙策', '22', '185.00', '男'])
series_list = [s1, s2, s3, s4, s5]
df = pd.DataFrame(series_list,index=list('abcde'))
print(df)
输出结果:
0 1 2 3 4
a 101 鲁班 18 150.00 男
b 102 小乔 19 167.00 女
c 103 关羽 30 180.00 男
d 104 大乔 20 170.00 女
e 105 孙策 22 185.00 男
4.1.5 读取CSV或Excel文件
待后详述
df = pd.read_csv('./xxx.csv')
df = pd.read_excel('./xxx.xlsx')
4.2 DataFrame基本属性和整体情况查询

s1 = pd.Series([101, '鲁班', '18', '150.00', '男'])
s2 = pd.Series([102, '小乔', '19', '167.00', '女'])
s3 = pd.Series([103, '关羽', '30', '180.00', '男'])
s4 = pd.Series([104, '大乔', '20', '170.00', '女'])
s5 = pd.Series([105, '孙策', '22', '185.00', '男'])
series_list = [s1, s2, s3, s4, s5]
df = pd.DataFrame(series_list,index=list('abcde'))
print(df)
print(df.shape)
print(df.dtypes)
print(df.ndim)
print(df.index)
print(df.columns)
print(df.values)
print(df.head(3))
print(df.tail(3))
print(df.info)
print(df.describe())
输出结果:
0 1 2 3 4
a 101 鲁班 18 150.6 男
b 102 小乔 19 167.5 女
c 103 关羽 30 180.6 男
d 104 大乔 20 170.7 女
e 105 孙策 22 185.3 男
(5, 5)
0 int64
1 object
2 object
3 float64
4 object
dtype: object
2
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
RangeIndex(start=0, stop=5, step=1)
[[101 '鲁班' '18' 150.6 '男']
[102 '小乔' '19' 167.5 '女']
[103 '关羽' '30' 180.6 '男']
[104 '大乔' '20' 170.7 '女']
[105 '孙策' '22' 185.3 '男']]
0 1 2 3 4
a 101 鲁班 18 150.6 男
b 102 小乔 19 167.5 女
c 103 关羽 30 180.6 男
0 1 2 3 4
c 103 关羽 30 180.6 男
d 104 大乔 20 170.7 女
e 105 孙策 22 185.3 男
<bound method DataFrame.info of 0 1 2 3 4
a 101 鲁班 18 150.6 男
b 102 小乔 19 167.5 女
c 103 关羽 30 180.6 男
d 104 大乔 20 170.7 女
e 105 孙策 22 185.3 男>
0 3
count 5.000000 5.000000
mean 103.000000 170.940000
std 1.581139 13.464138
min 101.000000 150.600000
25% 102.000000 167.500000
50% 103.000000 170.700000
75% 104.000000 180.600000
max 105.000000 185.300000
4.3 DataFrame的索引
- df.loc 通过 标签索引行数据 df.loc[index, column]
- df.iloc 通过 位置获取行数据
- 布尔索引
4.3.1 df.loc 通过标签索引行数据 df.loc[index, column]
s1 = pd.Series([101, '鲁班', '18', 150.60, '男'])
s2 = pd.Series([102, '小乔', '19', 167.50, '女'])
s3 = pd.Series([103, '关羽', '30', 180.60, '男'])
s4 = pd.Series([104, '大乔', '20', 170.70, '女'])
s5 = pd.Series([105, '孙策', '22', 185.30, '男'])
series_list = [s1, s2, s3, s4, s5]
df = pd.DataFrame(series_list,index=list('abcde'))
df.columns=['no','name','age','height','sex']
print(df.loc['a','name'])
print(df.loc['a',['name', 'sex']])
print(df.loc[['a','d'],['name', 'sex']])
print(df.loc['b':'c'])
print(df.loc['b':])
print(df.loc[:, 'name':'sex'])
print(df.loc[:, ['name', 'sex']])
print(df.loc['b':'c', 'name':'sex'])
print(df.loc[['a', 'c'], ['name', 'sex']])
输出结果:
鲁班
name 鲁班
sex 男
Name: a, dtype: object
name sex
a 鲁班 男
d 大乔 女
no name age height sex
b 102 小乔 19 167.5 女
c 103 关羽 30 180.6 男
no name age height sex
b 102 小乔 19 167.5 女
c 103 关羽 30 180.6 男
d 104 大乔 20 170.7 女
e 105 孙策 22 185.3 男
name age height sex
a 鲁班 18 150.6 男
b 小乔 19 167.5 女
c 关羽 30 180.6 男
d 大乔 20 170.7 女
e 孙策 22 185.3 男
name sex
a 鲁班 男
b 小乔 女
c 关羽 男
d 大乔 女
e 孙策 男
name age height sex
b 小乔 19 167.5 女
c 关羽 30 180.6 男
name sex
a 鲁班 男
c 关羽 男
4.3.2 df.iloc 通过位置获取行数据,位置数字索引,前闭后开
s1 = pd.Series([101, '鲁班', '18', 150.60, '男'])
s2 = pd.Series([102, '小乔', '19', 167.50, '女'])
s3 = pd.Series([103, '关羽', '30', 180.60, '男'])
s4 = pd.Series([104, '大乔', '20', 170.70, '女'])
s5 = pd.Series([105, '孙策', '22', 185.30, '男'])
series_list = [s1, s2, s3, s4, s5]
df = pd.DataFrame(series_list,index=list('abcde'))
df.columns=['no','name','age','height','sex']
print(df.iloc[0,1])
print(df.iloc[0,[1, 4]])
print(df.iloc[[0,3],[1, 4]])
print(df.iloc[1:2])
print(df.iloc[1:])
print(df.iloc[:, 1:4])
print(df.iloc[:, [1, 4]])
print(df.iloc[1:2, 1:4])
print(df.iloc[[0, 2], [1, 4]])
输出结果:
鲁班
name 鲁班
sex 男
Name: a, dtype: object
name sex
a 鲁班 男
d 大乔 女
no name age height sex
b 102 小乔 19 167.5 女
no name age height sex
b 102 小乔 19 167.5 女
c 103 关羽 30 180.6 男
d 104 大乔 20 170.7 女
e 105 孙策 22 185.3 男
name age height
a 鲁班 18 150.6
b 小乔 19 167.5
c 关羽 30 180.6
d 大乔 20 170.7
e 孙策 22 185.3
name sex
a 鲁班 男
b 小乔 女
c 关羽 男
d 大乔 女
e 孙策 男
name age height
b 小乔 19 167.5
name sex
a 鲁班 男
c 关羽 男
4.3.3 布尔索引
s1 = pd.Series([101, '鲁班', '18', 150.60, '男'])
s2 = pd.Series([102, '小乔', '19', 167.50, '女'])
s3 = pd.Series([103, '关羽', '30', 180.60, '男'])
s4 = pd.Series([104, '大乔', '20', 170.70, '女'])
s5 = pd.Series([105, '孙策', '22', 185.30, '男'])
series_list = [s1, s2, s3, s4, s5]
df = pd.DataFrame(series_list,index=list('abcde'))
df.columns=['no','name','age','height','sex']
print(df['name']=='鲁班')
print((df['age']<'30') & (df['height']>167))
print(df[df['name']=='鲁班'])
print(df[(df['age']<'30') & (df['height']>167) & (df['sex']=='女')])
print(df[~((df['age']<'30') & (df['height']>167) & (df['sex']=='女'))])
print(df[(df['age']<'30') | (df['height']>167) & (df['sex']=='女')])
输出结果:
a True
b False
c False
d False
e False
Name: name, dtype: bool
a False
b True
c False
d True
e True
dtype: bool
no name age height sex
a 101 鲁班 18 150.6 男
no name age height sex
b 102 小乔 19 167.5 女
d 104 大乔 20 170.7 女
no name age height sex
a 101 鲁班 18 150.6 男
c 103 关羽 30 180.6 男
e 105 孙策 22 185.3 男
no name age height sex
a 101 鲁班 18 150.6 男
b 102 小乔 19 167.5 女
d 104 大乔 20 170.7 女
e 105 孙策 22 185.3 男
4.4 Dataframe的赋值
s1 = pd.Series([101, '鲁班', '18', 150.60, '男'])
s2 = pd.Series([102, '小乔', '19', 167.50, '女'])
s3 = pd.Series([103, '关羽', '30', 180.60, '男'])
s4 = pd.Series([104, '大乔', '20', 170.70, '女'])
s5 = pd.Series([105, '孙策', '22', 185.30, '男'])
series_list = [s1, s2, s3, s4, s5]
df = pd.DataFrame(series_list,index=list('abcde'))
df.columns=['no','name','age','height','sex']
print('# 修改单个数据')
print(df.loc['a','name'])
df.loc['a','name'] = '新名字'
print(df.loc['a','name'])
print('# 修改所有行的指定列')
print(df.loc[:, ['no', 'height']])
df.loc[:, ['no', 'height']] = 200
print(df.loc[:, ['no', 'height']])
print('# 修改所有行的指定列')
print(df.loc[:, ['name', 'sex']])
df.loc[:, ['name', 'sex']] = ['新名字', '未知']
print(df.loc[:, ['name', 'sex']])
输出结果:
鲁班
新名字
no height
a 101 150.6
b 102 167.5
c 103 180.6
d 104 170.7
e 105 185.3
no height
a 200 200
b 200 200
c 200 200
d 200 200
e 200 200
name sex
a 新名字 男
b 小乔 女
c 关羽 男
d 大乔 女
e 孙策 男
name sex
a 新名字 未知
b 新名字 未知
c 新名字 未知
d 新名字 未知
e 新名字 未知
五、多层索引
- 在某个方向上拥有多层索引(两层及两层以上)
- 通过多层索引,pandas能够以低维度形式处理高维度数据
- 通过多层索引,可以按层级统计数据
5.1 Series多层索引
s= pd.Series(['鲁班', '小乔', '关羽', '大乔'],
index=[['一班', '一班', '二班', '二班', ],list('abcd')])
print(s)
print(s.index)
print(s.index.names)
s.index.names = ['班级', '分类']
print(s)
print(s.index)
print(s.index.names)
输出结果:
一班 a 鲁班
b 小乔
二班 c 关羽
d 大乔
dtype: object
MultiIndex([('一班', 'a'),
('一班', 'b'),
('二班', 'c'),
('二班', 'd')],
)
[None, None]
班级 分类
一班 a 鲁班
b 小乔
二班 c 关羽
d 大乔
dtype: object
MultiIndex([('一班', 'a'),
('一班', 'b'),
('二班', 'c'),
('二班', 'd')],
names=['班级', '分类'])
['班级', '分类']
5.2 DataFrame多层索引
`python
s1 = pd.Series([101, ‘鲁班’, ’18’, 150.60, ‘男’])
s2 = pd.Series([101, ‘小乔’, ’19’, 167.50, ‘女’])
s3 = pd.Series([102, ‘关羽’, ’30’, 180.60, ‘男’])
s4 = pd.Series([102, ‘大乔’, ’20’, 170.70, ‘女’])
s5 = pd.Series([102, ‘孙策’, ’22’, 185.30, ‘男’])
series_list = [s1, s2, s3, s4, s5]
df = pd.DataFrame(series_list)
df.columns=[‘class’,’name’,’age’,’height’,’sex’]
print(df)
print(df.index.names)
print(‘———-‘)
df = df.set_index([‘class’, ‘name’])
print(df)
print(df.index.names)
输出结果:
class name age height sex
0 101 鲁班 18 150.6 男
1 101 小乔 19 167.5 女
2 102 关羽 30 180.6 男
3 102 大乔 20 170.7 女
4 102 孙策 22 185.3 男
[None]
Original: https://blog.csdn.net/yuetaope/article/details/120875061
Author: 岳涛@心馨电脑
Title: 【Python百日基础系列】Day11 – Pandas 基础
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/677299/
转载文章受原作者版权保护。转载请注明原作者出处!