

Task05
本次学习参照Datawhale开源学习:https://github.com/datawhalechina/machine-learning-toy-code/tree/main/ml-with-sklearn
内容安排如下,主要是一些代码实现和部分原理介绍。

; 5. k均值聚类
无监督学习训练样本的标签信息是未知的,目标是通过对无标签训练样本的学习来揭示数据的内在性质及规律,此类学习应用最广的是聚类。聚类试图将数据集中的样本划分为若干个通常不相交的子集,每个子集称为一个”簇”。
5.1. 性能度量
聚类的目的是把数据集中相似的样本聚成一个簇,将不相似的样本分为不同的簇。因此聚类时需要保证同一簇中的样本相似度要尽可能高,而簇与簇之间的样本相似度要尽可能的低。聚类性能度量大致有两类:
- 外部指标:将聚类结果和某个”参考模型”进行比较。
- 内部指标:直接考察聚类结果而不利用任何参考模型。

内部指标:
- Jaccard系数J C = a a + b + c JC=\frac{a}{a+b+c}J C =a +b +c a
- FM指数F M I = a a + b ⋅ a a + c FMI=\sqrt{\frac{a}{a+b}\cdot\frac{a}{a+c}}F M I =a +b a ⋅a +c a
- Rand指数R I = 2 ( a + d ) m ( m − 1 ) RI=\frac{2(a+d)}{m(m-1)}R I =m (m −1 )2 (a +d )
外部指标:
- DB指数D B I = 1 k ∑ i = 1 k m a x j ≠ i ( a v g ( C i ) + a v g ( C j ) ) d c e n ( μ i , μ j ) ) DBI=\frac{1}{k}\sum_{i=1}^{k}\underset {j\not=i}{max}(\frac{avg(C_i)+avg(C_j))}{d_{cen}(\mu_i,\mu_j)})D B I =k 1 i =1 ∑k j =i ma x (d c e n (μi ,μj )a v g (C i )+a v g (C j )))
- Dunn指数D I = m i n i ⩽ j ⩽ k ( m i n j ≠ i d m i n ( C i , C j ) m a x i ⩽ j ⩽ k d i a m ( C l ) ) DI=\underset {i\leqslant{j}\leqslant{k}}{min}(\underset {j\not=i}{min}\frac{d_{min}(C_i,C_j)}{\underset {i\leqslant{j}\leqslant{k}}{max}diam(C_l)})D I =i ⩽j ⩽k min (j =i min i ⩽j ⩽k ma x d i a m (C l )d m i n (C i ,C j ))
; 5.2. 距离计算
对函数d i s t ( ⋅ , ⋅ ) dist(\cdot,\cdot)d i s t (⋅,⋅),若它是一个”距离度量”,则需满足基本性质:
非 负 性 : d i s t ( x i , x j ) ⩾ 0 非负性:dist(x_i,x_j)\geqslant0 非负性:d i s t (x i ,x j )⩾0 同 一 性 : d i s t ( x i , x j ) = 0 当 且 仅 当 x i = x j 同一性:dist(x_i,x_j)=0当且仅当x_i=x_j 同一性:d i s t (x i ,x j )=0 当且仅当x i =x j 对 称 性 : d i s t ( x i , x j ) = d i s t ( x j , x i ) 对称性:dist(x_i,x_j)=dist(x_j,x_i)对称性:d i s t (x i ,x j )=d i s t (x j ,x i )直 递 性 : d i s t ( x i , x j ) ⩽ d i s t ( x i , x k ) + d i s t ( x k , x j ) 直递性:dist(x_i,x_j)\leqslant{dist(x_i,x_k)}+dist(x_k,x_j)直递性:d i s t (x i ,x j )⩽d i s t (x i ,x k )+d i s t (x k ,x j )给定样本x i = ( x i 1 ; x i 2 ; . . . ; x i n ) x_i=(x_{i1};x_{i2};…;x_{in})x i =(x i 1 ;x i 2 ;…;x i n )与x j = ( x j 1 ; x j 2 ; . . . ; x j n ) x_j=(x_{j1};x_{j2};…;x_{jn})x j =(x j 1 ;x j 2 ;…;x j n ),最常用的是” 闵可夫斯基距离“:d i s t m k ( x i , x j ) = ( ∑ u = 1 n ∣ x i u − x j u ∣ p ) 1 p dist_{mk}(x_i,x_j)=(\sum_{u=1}^{n}|x_{iu}-x_{ju}|^p)^\frac{1}{p}d i s t m k (x i ,x j )=(u =1 ∑n ∣x i u −x j u ∣p )p 1 当p = 1 p=1 p =1时就是曼哈顿距离,当p = 2 p=2 p =2时就是欧氏距离,当p p p趋近于无穷大时就是切比雪夫距离。

(绿色路径为两点间欧氏距离,红色黄色路径为两点间曼哈顿距离)

(当p为其它值时)
5.3. k均值聚类
给定样本集D = { x 1 , x 2 , . . . , x m } D=\left{\begin{matrix}x_1,x_2,…,x_m \end{matrix}\right}D ={x 1 ,x 2 ,…,x m },”k均值”算法针对聚类所得簇划分C = { C 1 , C 2 , . . . , C k } C=\left{\begin{matrix}C_1,C_2,…,C_k \end{matrix}\right}C ={C 1 ,C 2 ,…,C k }最小化平方误差:E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 2 E=\sum_{i=1}^{k}\sum_{x\in{C_i}}^{}||x-\mu_i||2^2 E =i =1 ∑k x ∈C i ∑∣∣x −μi ∣∣2 2 其中均值向量:μ i = 1 C i ∑ x ∈ C i x \mu_i=\frac{1}{C_i}\sum{x\in{C_i}}x μi =C i 1 x ∈C i ∑xE值越小则簇内样本相似度越高。如何找到最优解:

动态图演示过程:

; 5.4. sklearn k均值聚类
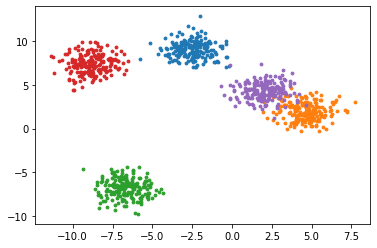
'''生成数据'''
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=1000,
n_features=2,
centers=5,
random_state=42)
fig, ax=plt.subplots(1)
for i in range(5):
ax.scatter(X[y==i, 0], X[y==i,1],marker='o',s=8,)
plt.show()
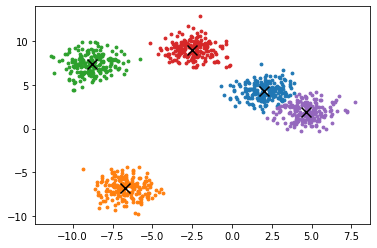
'''聚类'''
from sklearn.cluster import KMeans
cluster = KMeans(n_clusters=5,random_state=0).fit(X)
y_pred = cluster.fit_predict(X)
centroid=cluster.cluster_centers_
inertia=cluster.inertia_
'''画出聚类质心'''
fig, ax=plt.subplots(1)
for i in range(n_clusters):
ax.scatter(X[y_pred==i, 0], X[y_pred==i, 1],
marker='o',
s=8)
ax.scatter(centroid[:,0],centroid[:,1],marker='x',s=100,c='black')
5.5. 参数说明
class sklearn.cluster.KMeans(n_clusters=8, *, init='k-means++', n_init=10, max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True, algorithm='auto')
n_clusters:int,default=8。质心(centroids)数。
init:三个可选值:”k-means++”, “random”,或者一个ndarray向量。默认值为 ‘k-means++’。
- “k-means++” 用k-means++方法选定初始质心从而能加速迭代过程的收敛。
- “random”随机从训练数据中选取初始质心。
- 如果传递的是一个ndarray,则应该形如 (n_clusters, n_features) 并给出初始质心。
n_init:int,default=10。用不同的质心初始化值运行算法的次数,最终解是在inertia意义下选出的最优结果。
max_iter:int,default=300。最大迭代次数。
tol:float,default= 1e-4。容许误差,确定收敛条件。
verbose:int,default=0。结果的信息复杂度
random_state:int,default=None。numpy的随机数生成器。
copy_x:bool,default=True。当我们precomputing distances时,将数据中心化会得到更准确的结果。如果把此参数值设为True,则原始数据不会被改变。如果是False,则会直接在原始数据上做修改并在函数返回值时将其还原。
algorithm:三个值可选:”auto”, “full”, “elkan”, default=”auto”。
Original: https://blog.csdn.net/weixin_45397053/article/details/122133711
Author: 黑小板
Title: sklearn机器学习(五)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/560596/
转载文章受原作者版权保护。转载请注明原作者出处!