

最近无意看到一份关于数据分析的Python笔试题,做起来还是很有意思的,特意自己动手做了一下,和大家分享一下,希望大家也可以跟着练习。
题目如下:
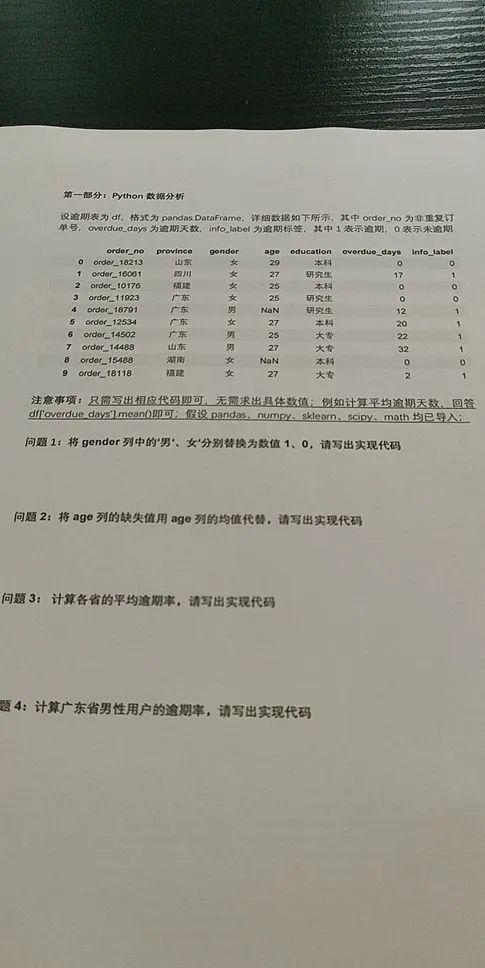

首先,模拟数据:
importpandas aspd
importnumpy asnp
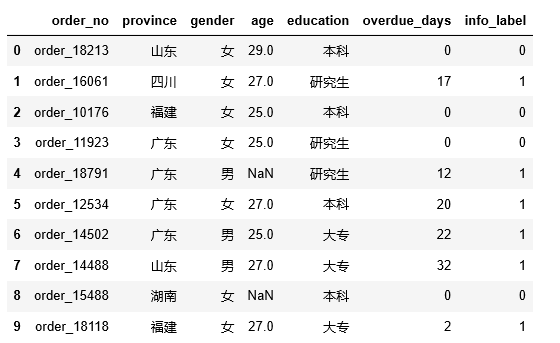
df = pd.DataFrame({ ‘order_no’:[ ‘order_18213’, ‘order_16061’, ‘order_10176’, ‘order_11923’, ‘order_18791’,
‘order_12534’, ‘order_14502’, ‘order_14488’, ‘order_15488’, ‘order_18118’],
‘province’:[ ‘山东’, ‘四川’, ‘福建’, ‘广东’, ‘广东’, ‘广东’, ‘广东’, ‘山东’, ‘湖南’, ‘福建’],
‘gender’:[ ‘女’, ‘女’, ‘女’, ‘女’, ‘男’, ‘女’, ‘男’, ‘男’, ‘女’, ‘女’],
‘age’:[ 29.0, 27.0, 25.0, 25.0,np.nan, 27.0, 25.0, 27.0,np.nan, 27.0],
‘education’:[ ‘本科’, ‘研究生’, ‘本科’, ‘研究生’, ‘研究生’, ‘本科’, ‘大专’, ‘大专’, ‘本科’, ‘大专’],
‘overdue_days’:[ 0, 17, 0, 0, 12, 20, 22, 32, 0, 2],
‘info_label’:[ 0, 1, 0, 0, 1, 1, 1, 1, 0, 1]
})
df
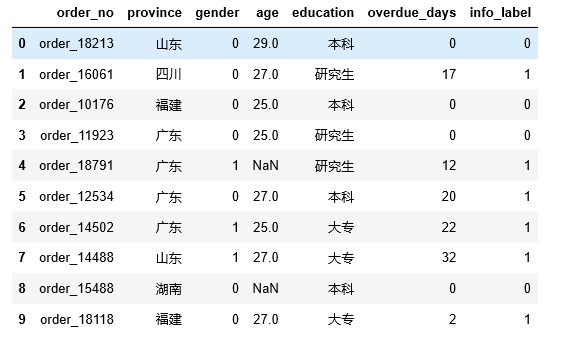
题目1:将gender列中的 男 ,女分别替换为数值1、0
方法1:
df[ ‘gender’]=df[ ‘gender’].map({ ‘男’: 1, ‘女’: 0})
方法2:
df[ ‘gender’]=df[ ‘gender’].replace([ ‘男’, ‘女’],[ 1, 0])
方法3:
df.loc[df[ ‘gender’]== ‘男’, ‘gender’]= 1
df.loc[df[ ‘gender’]== ‘女’, ‘gender’]= 0df
题目2:将age列的缺失值用age列的均值代替
使用fillna填补缺失值即可
df_mean = df[ ‘age’].mean
df[ ‘age’].fillna(df_mean,inplace=True)
df
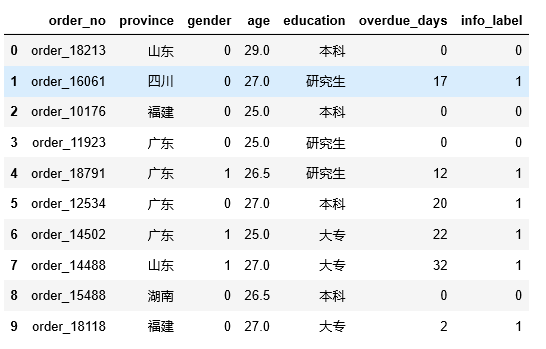
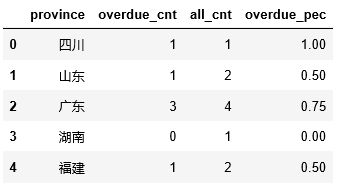
题目3:计算各省的平均逾期率
逾期率=逾期客户/全部客户
计算各省的逾期用户
df_overdue = df.groupby( ‘province’)[ ‘info_label’].sum.reset_index
df_overdue.columns=[ ‘province’, ‘overdue_cnt’]
计算各省的用户数
df_all = df.groupby( ‘province’)[ ‘info_label’].count.reset_index
df_all.columns=[ ‘province’, ‘all_cnt’]
合并各省逾期用户及各省用户数形成新的报表df1
df1 = pd.merge(df_overdue, df_all, on = [ ‘province’], how = ‘left’)
得到各省的逾期率
df1[ ‘overdue_pec’] = df1[ ‘overdue_cnt’]/df1[ ‘all_cnt’]
df1
题目4:计算广东省男性用户的逾期率
计算广东省的逾期男性用户
overdue_pec_gd = df[(df[ ‘province’]== ‘广东’) & (df[ ‘gender’] == 1)][ ‘info_label’].sum/df[(df[ ‘province’]== ‘广东’) & (df[ ‘gender’] == 1)][ ‘info_label’].count
print(overdue_pec_gd)
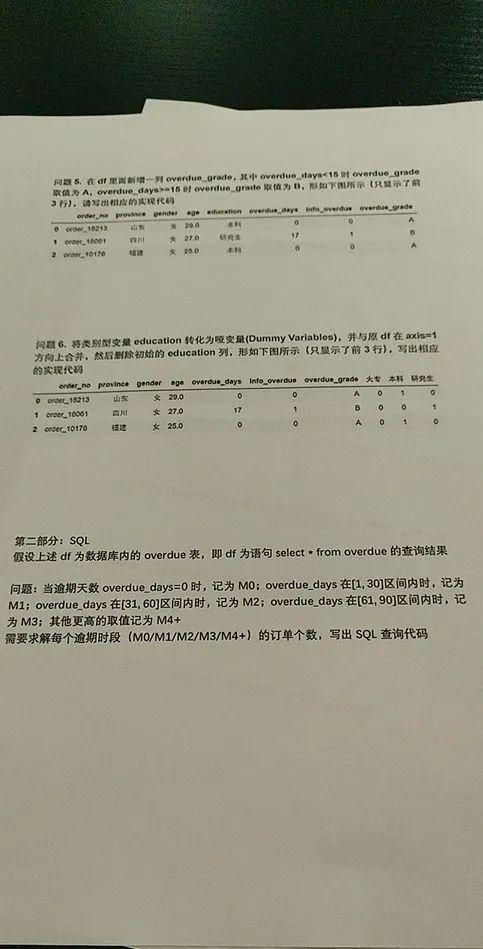
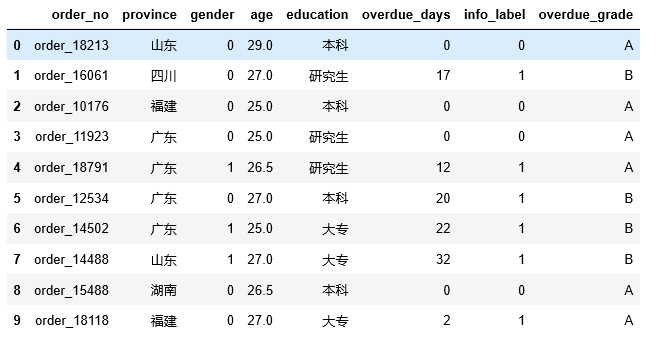
题目5:在df里面新增1列overdue_grade,其中overdue_days
df[ ‘overdue_grade’] = df[ ‘overdue_days’].apply( lambdax: ‘A’ifx< 15else’B’)
df
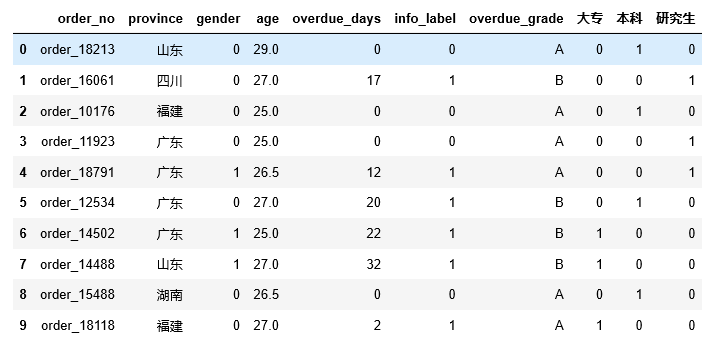
题目6:将类别型变量education 转化为哑变量(Dummy Variables),并与原df在axis=1 方向上合并,然后删除初始的education列
使用get_dummies进行one-hot变量,然后进行数据合并concat,删除使用drop
df=pd.concat((df,pd.get_dummies(df[ ‘education’])),axis= 1)
df.drop([ ‘education’],axis= 1)
如果对Python有兴趣,想了解更多的Python以及AIoT知识,解决测试问题,以及入门指导,帮你解决学习Python中遇到的困惑,我们这里有技术高手。如果你正在找工作或者刚刚学校出来,又或者已经工作但是经常觉得难点很多,觉得自己Python方面学的不够精想要继续学习的,想转行怕学不会的, 都可以加入我们,可领取最新Python大厂面试资料和Python爬虫、人工智能、学习资料!VX【pydby01】暗号CSDN

Original: https://blog.csdn.net/pydby01/article/details/122019319
Author: IT娜娜
Title: 一道经典的Python数据分析笔试题
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/676077/
转载文章受原作者版权保护。转载请注明原作者出处!