

目录
第6章 数据载入、存储及文件格式
输入和输出通常有以下几种类型:
· 读取文本文件及硬盘上其他更高效的格式文件;
·从数据库载入数据;
·与网络资源进行交互(比如Web API)。
6.1 文本格式数据的读写
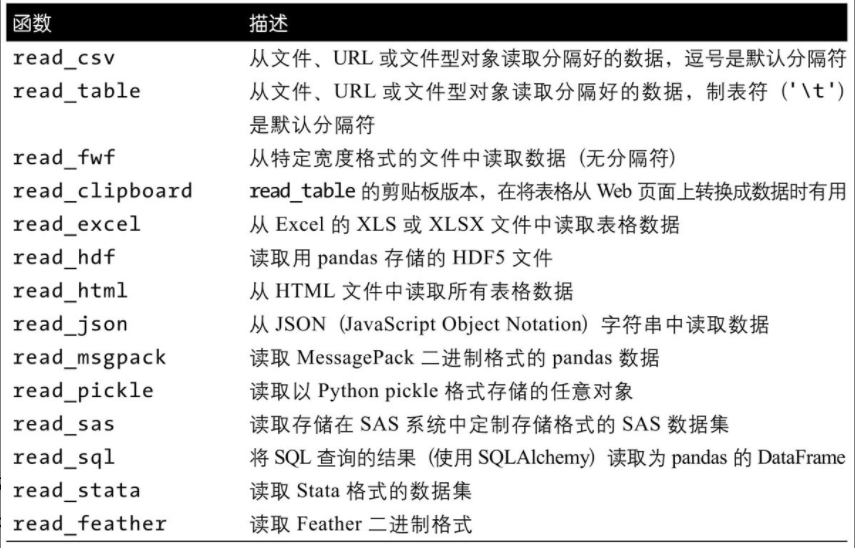
将表格型数据读取为DataFrame对象是pandas的重要特性。如下是pandas的解析函数:

使用read_csv将一个csv文件读入一个DataFrame:

如果原csv文件以逗号分隔,那么也可以使用read_table,并指定分隔符:
pd.read_table('D:\AHUT-STU\instacart-market-basket-analysis\products.csv',sep=',')
对于不包含表头行的文件,可以允许pandas自动分配默认列名,也可以自动指定列名:
pd.read_csv('D:\AHUT-STU\instacart-market-basket-analysis\products.csv',names=[0,1,2,3,4,5])
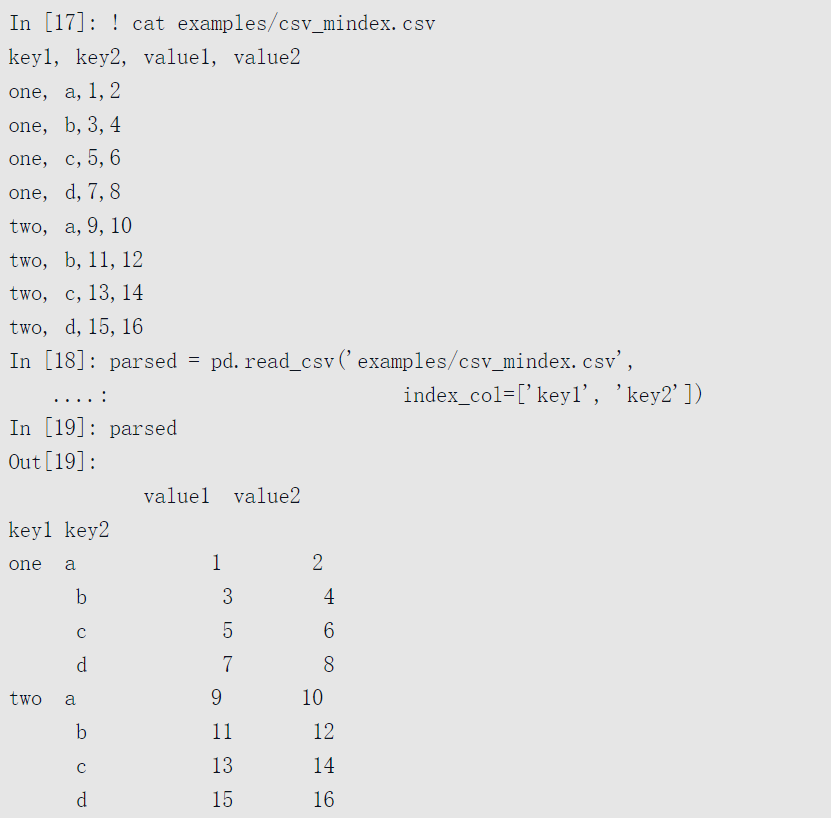
想要某一列的值成为返回DataFrame的索引,你可以指定列的位置为索引,或将’列名’传给参数index_col:
names=[0,1,2,3,4,5]
pd.read_csv('products.csv',names=names,index_col='列名或者列所在位置比如位置4')
当想要从多个列中形成一个分层索引,需要传入一个包含列序号或列名的列表:
在某些情况下,一张表的分隔符并不是固定的,使用空白或其他方式来分隔字段。考虑如下文本文件:

当字段是以多种不同数量的空格分开时,可以手工处理,但在这些情况下也可以向read_table传入一个正则表达式作为分隔符。在本例中,正则表达式为\s+,因此可以得到:

可以使用skiprows来跳过第一行、第三行和第四行:

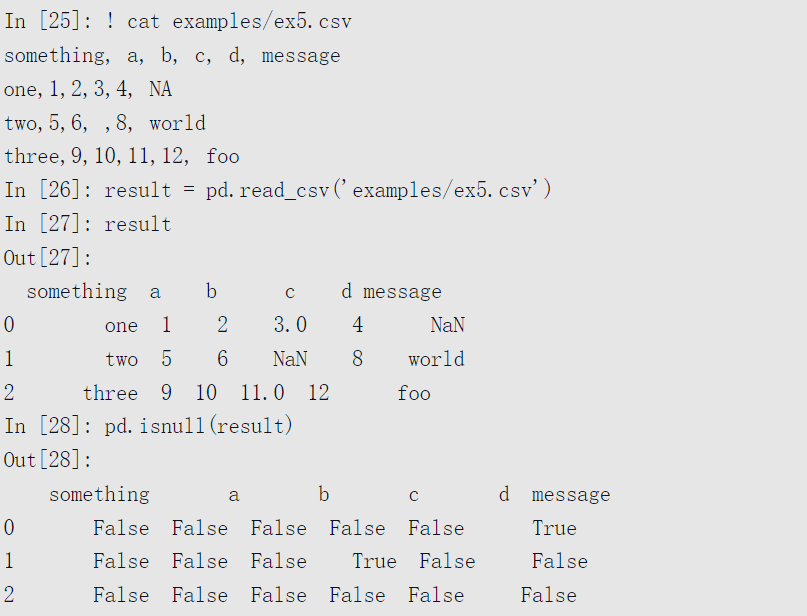
缺失值处理是文件解析过程中一个重要且常常微妙的部分。通常情况下,缺失值要么不显示(空字符串),要么用一些标识值。默认情况下,pandas使用一些常见的标识,例如NA和NULL:
na_values选项可以传入一个列表或一组字符串来处理缺失值:

在字典中,每列可以指定不同的缺失值标识:

pandas.read_csv和pandas.read_table中常用的选项如下:

6.1.1 分块读入文本文件
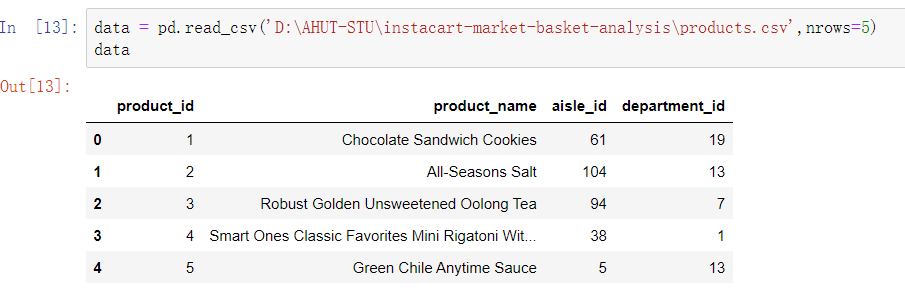
读取一小部分行(避免读取整个文件),可以指明nrows:
为了分块读入文件,可以指定chunksize作为每一块的行数:

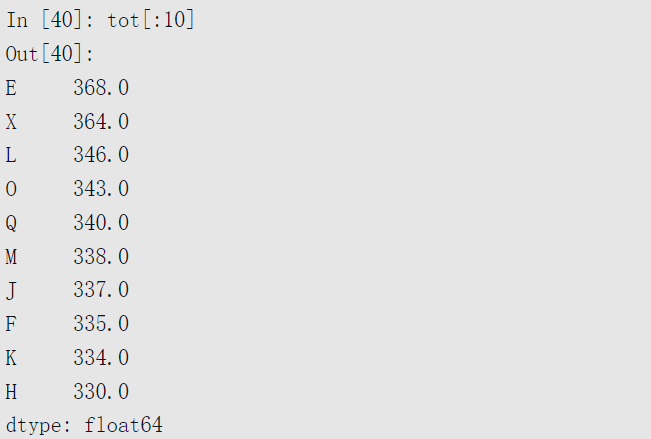
read_csv返回的TextParser对象允许根据chunksize遍历文件。例如,我们可以遍历ex6.csv,并对’key’列聚合获得计数值:

6.1.2 将数据写入文本格式
数据可以导出为分隔的形式。

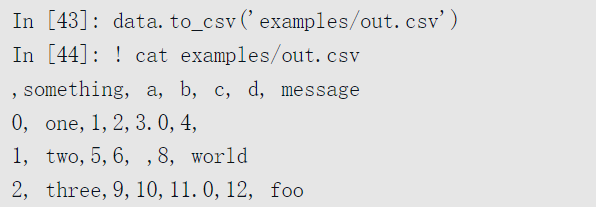
使用DataFrame的to_csv方法,可以将数据导出为逗号分隔的文件,其他分隔符也可以,指定sep参数即可:
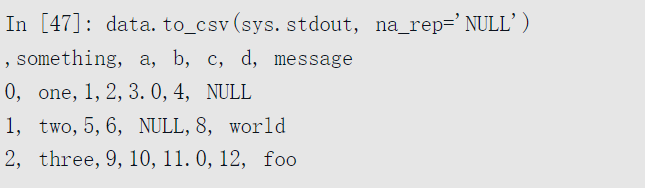
缺失值在输出时以空字符串出现。用其他标识值对缺失值进行标注:
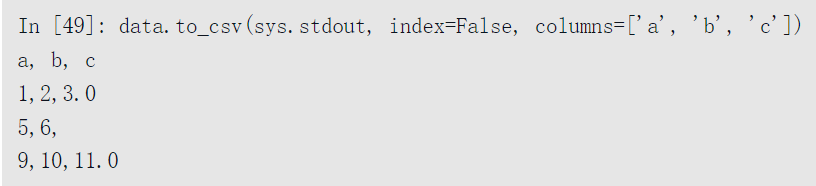
如果没有其他选项被指定的话,行和列的标签都会被写入。不过二者也都可以禁止写入:

也可以仅写入列的子集,并且按照你选择的顺序写入:
6.1.3 使用分隔格式
绝大多数的表型数据都可以使用函数pandas.read_table从硬盘中读取。然而,在某些情况下,一些手动操作可能是必不可少的。接收一个带有一行或多行错误的文件并不少见,read_table也无法解决这种情况。为了介绍一些基础工具,考虑如下的小型CSV文件:
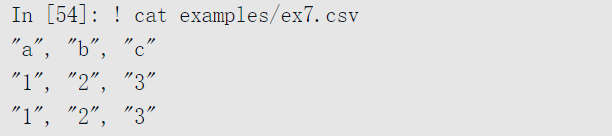
对于任何带有单字符分隔符的文件,可以使用Python的内建csv模块。要使用它,需要将任一打开的文件或文件型对象传给csv.reader:

像遍历文件那样遍历reader会产生元组,元组的值为删除了引号的字符:

将文件读取为行的列表:

将数据拆分为列名行和数据行:

使用字典推导式和表达式zip(*values)生成一个包含数据列的字典,字典中行转置成列:

CSV文件有多种不同风格。如需根据不同的分隔符、字符串引用约定或行终止符定义一种新的格式时,可以使用csv.Dialect定义一个简单的子类:
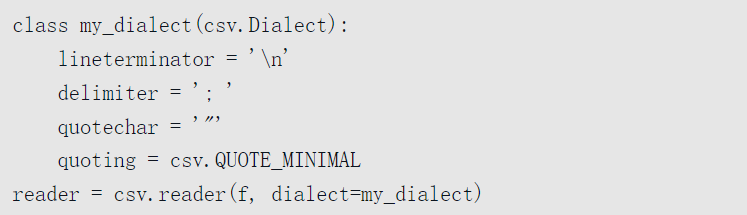
也可以不必定义子类,直接将CSV方言参数传入csv.reader的关键字参数:

csv.Dialect中的一些属性及其用途:

需要手动写入被分隔的文件时,可以使用csv.writer。这个函数接收一个已经打开的可写入文件对象以及和csv.reader相同的CSV方言、格式选项:

6.1.4 JSON数据
JSON(JavaScript Object Notation的简写)已经成为Web浏览器和其他应用间通过HTTP请求发送数据的标准格式。

JSON非常接近有效的Python代码,除了它的空值null和一些其他的细微差别(例如不允许列表末尾的逗号)之外。基本类型是对象(字典)、数组(列表)、字符串、数字、布尔值和空值。对象中的所有键都必须是字符串。有几个Python库用于读写JSON数据。在这里使用json,因为它是内置在Python标准库中的。将JSON字符串转换为Python形式时,使用json.loads方法:

json.dumps可以将Python对象转换回JSON:
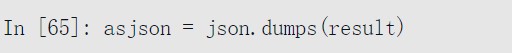
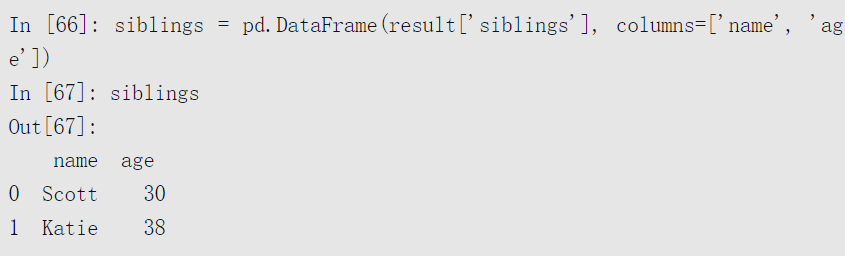
可以自行决定如何将JSON对象或对象列表转换为DataFrame或其他数据结构。比较方便的方式是将字典构成的列表(之前是JSON对象)传入DataFrame构造函数,并选出数据字段的子集:
pandas.read_json可以自动将JSON数据集按照指定次序转换为Series或DataFrame。例如:

pandas.read_json的默认选项是假设JSON数组中的每个对象是表里的一行:

如果需要从pandas中将数据导出为JSON,一种办法是对Series和DataFrame使用to_json方法:

6.2 二进制格式
使用Python内建的pickle序列化模块进行二进制格式操作是存储数据(也称为序列化)最高效、最方便的方式之一。pandas对象拥有一个to_pickle方法可以将数据以pickle格式写入硬盘:

可以直接使用内建的pickle读取文件中”pickle化”的对象,或更方便地使用pandas.read_pickle做上述操作:

pickle仅被推荐作为短期的存储格式。问题在于pickle很难确保格式的长期有效性;一个今天被pickle化的对象可能明天会因为库的新版本而无法反序列化。需要尽可能保持向后兼容性,但在将来的某个时候,可能有必要”打破”pickle格式。
6.2.1 使用HDF5格式
HDF5是一个备受好评的文件格式,用于存储大量的科学数组数据。它以C库的形式提供,并且具有许多其他语言的接口,包括Java、Julia、MATLAB和Python。HDF5中的”HDF”代表分层数据格式。每个HDF5文件可以存储多个数据集并且支持元数据。 与更简单的格式相比,HDF5支持多种压缩模式的即时压缩,使得重复模式的数据可以更高效地存储。HDF5适用于处理不适合在内存中存储的超大型数据,可以使你高效读写大型数组的一小块。
尽管可以通过使用PyTables或h5py等库直接访问HDF5文件,但pandas提供了一个高阶的接口,可以简化Series和DataFrame的存储。HDFStore类像字典一样工作并处理低级别细节:

包含在HDF5文件中的对象可以使用相同的字典型API进行检索:
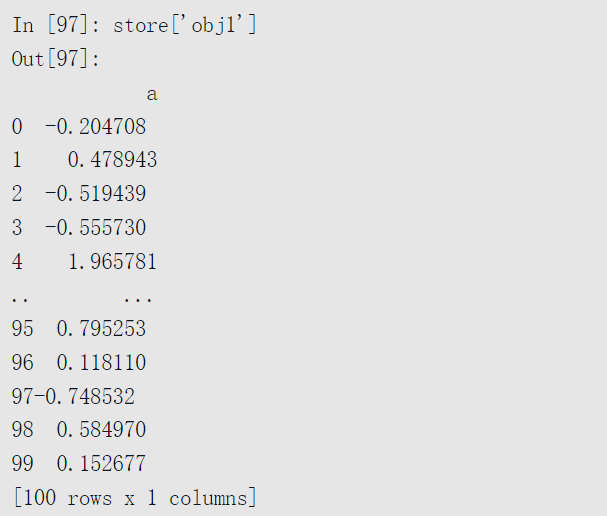
HDFStore支持两种存储模式,’fixed’和’table’。后者速度更慢,但支持一种特殊语法的查询操作:

put是store [‘obj2’]=frame方法的显式版本,但允许我们设置其他选项,如存储格式。
pandas.read_hdf函数是这些工具的快捷方法:

HDF5并不是数据库,它是一种适合一次写入多次读取的数据集。尽管数据可以在任何时间添加到文件中,但如果多个写入者持续写入,文件可能会损坏。
6.2.2 读取Microsoft Excel文件
pandas也支持通过ExcelFile类或pandas.read_excel函数来读取存储在Excel 2003(或更高版本)文件中的表格型数据。
使用ExcelFile时,通过将xls或xlsx的路径传入,生成一个实例:

存储在表中的数据可以通过pandas.read_excel读取到DataFrame中:

如果你读取的是含有多个表的文件,生成ExcelFile更快,但你也可以更简洁地将文件名传入pandas.read_excel:

如需将pandas数据写入到Excel格式中,你必须先生成一个ExcelWriter,然后使用pandas对象的to_excel方法将数据写入:

也可以将文件路径传给to_excel,避免直接调用ExcelWriter:

6.3 与WEB API交互
要获取GitHub上最新的30条关于pandas的问题,我们可以使用附加库requests发送一个HTTP GET请求:
Response(响应)对象的json方法将返回一个包含解析为本地Python对象的JSON的字典:

data中的每个元素都是一个包含GitHub问题页面上的所有数据的字典(注释除外)。
我们可以将data直接传给DataFrame,并提取感兴趣的字段:
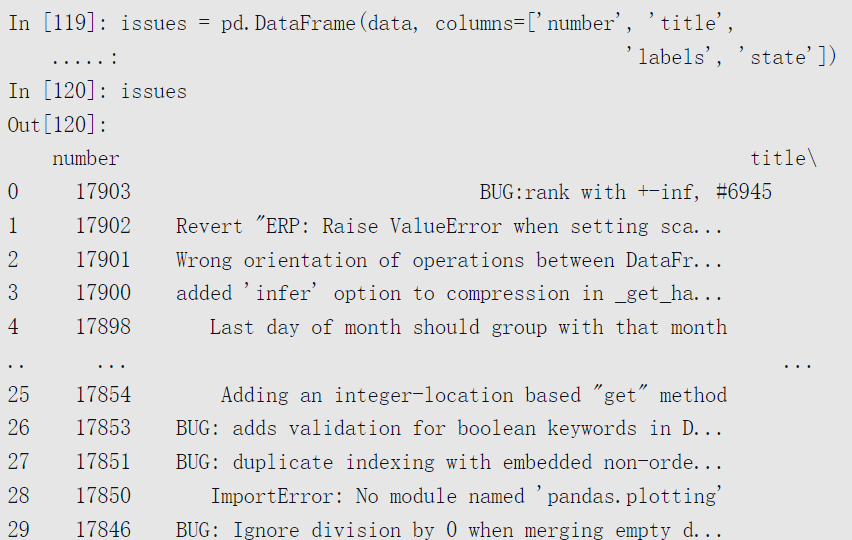
6.4 与数据库交互
在业务场景中,大部分数据并不是储存在文本或Excel文件中的。基于SQL的关系型数据库(例如SQL Server、PostgreSQL和MySQL)使用广泛,很多小众数据库也变得越发流行。数据库的选择通常取决于性能、数据完整性以及应用的可伸缩性需求。
使用Python内建的sqlite3驱动来生成一个SQLite数据库:
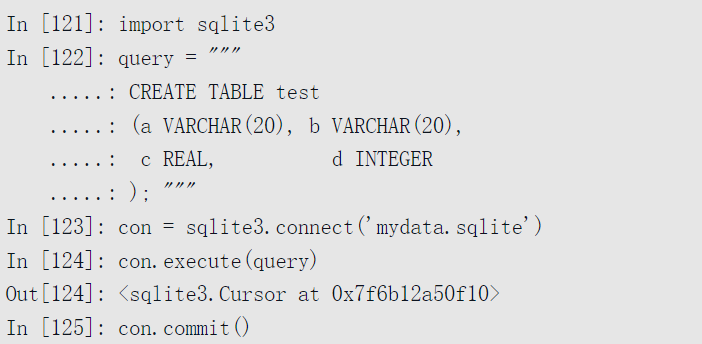
再插入几行数据:

当从数据库的表中选择数据时,大部分Python的SQL驱动(PyODBC、psycopg2、MySQLdb、pymssql等)返回的是元组的列表:

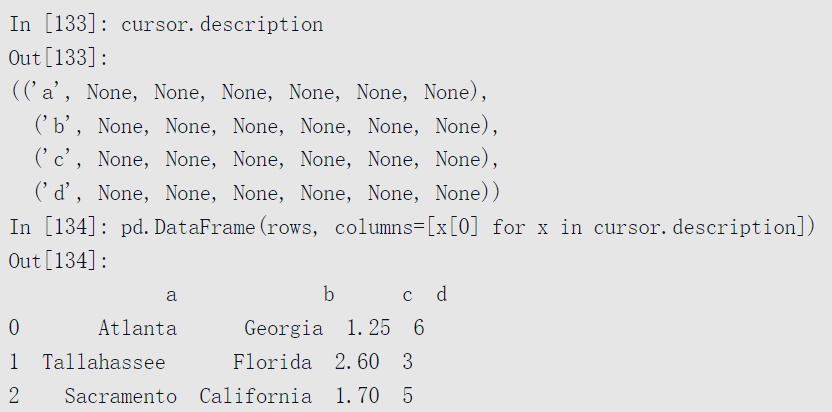
你可以将元组的列表传给DataFrame构造函数,但你还需要包含在游标的description属性中的列名:
使用SQLAlchemy连接到相同的SQLite数据库,并从之前创建的表中读取数据:

参考:《利用Python实现数据分析》
Original: https://blog.csdn.net/qq_42433311/article/details/123493131
Author: QYiRen
Title: 数据载入、存储及文件格式(数据分析)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/675894/
转载文章受原作者版权保护。转载请注明原作者出处!