

我有一个数据帧:import pandas as pd
df = pd.DataFrame([[‘A’, ‘G1’, ‘2019-01-01’, 11],
[‘A’, ‘G1’, ‘2019-01-02’, 12],
[‘A’, ‘G1’, ‘2019-01-04’, 14],
[‘B’, ‘G2’, ‘2019-01-01’, 11],
[‘B’, ‘G2’, ‘2019-01-03’, 13],
[‘B’, ‘G2’, ‘2019-01-06’, 16]],
columns=[‘cust’, ‘group’, ‘date’, ‘val’])
df


^{pr2}$

数据帧被分组,现在我想计算pct_change,但前提是有以前的日期。
如果我这样做:df[‘pct’] = df.groupby([‘cust’, ‘group’]).val.pct_change()
df
我将得到pct_change,但不考虑丢失的日期。
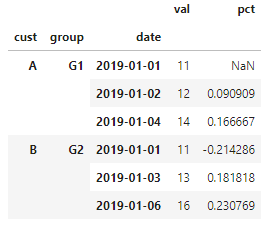
例如,在组(‘A’, ‘G1’)中,日期2019-01-04的pct应该是{},因为没有(上一个)日期2019-01-03。在
也许解决方案是按天重新采样,其中每个新行将np.nan作为val,然后再做{}。在
我试图使用df.resample(‘1D’, level=2),但是我得到一个错误:TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of ‘MultiIndex’
对于组(‘B’, ‘G2’),所有pct_change应该是np.nan,因为没有一行有上一个日期。在
预期结果为:

如何计算关于缺失日期的pct_change?在
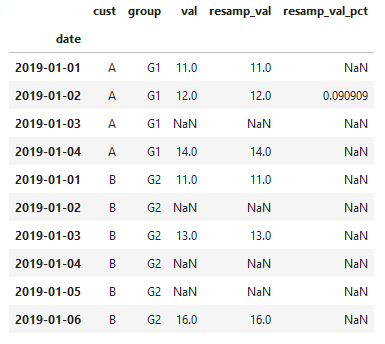
解决方案:new_df = pd.DataFrame()
for x, y in df.groupby([‘cust’, ‘group’]):
resampled=y.set_index(‘date’).resample(‘D’).val.mean().to_frame().rename({‘val’: ‘resamp_val’}, axis=1)
resampled = resampled.join(y.set_index(‘date’)).fillna({‘cust’:x[0],’group’:x[1]})
resampled[‘resamp_val_pct’] = resampled.resamp_val.pct_change(fill_method=None)
new_df = pd.concat([new_df, resampled])
new_df = new_df[[‘cust’, ‘group’, ‘val’, ‘resamp_val’, ‘resamp_val_pct’]]
new_df
Original: https://blog.csdn.net/weixin_29046035/article/details/114389630
Author: 许清风
Title: python pct_change_在pct_change()和缺失值之前重新采样
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/675876/
转载文章受原作者版权保护。转载请注明原作者出处!