

pandas.read_excel(io, sheet_name…)
参数说明
- io: 文件路径
- sheet_name 列名,默认为0, 可以是数字/列名/list(数字、列名)
- header 标题行,默认第一行,可以是数字/list
- names 补充列名, names元素的个数必须和dataframe的列数一致,name=[0,1,2…]: 0,1,2将作为列名
- index_col 指定行索引, 默认None, 可以是数字/list
- usecols: 指定读取列,
usecols=[1,2,3] # 读取2-4列
usecols=None, #读取所有列 - squeeze: 如果源数据只有一列, squeeze=False为DataFrame,squeeze=True时为Series
- converters={
‘收入’ lambda x: x/100 # 收入除以100
} - skiprows: 省略指定行数据,第一行开始
- skipfooter: 省略指定行数据,最后一行开始
- dtype: dtype={
‘grade’: np.float32
} # 读取为类型数据
使用
创建一个Excel文件
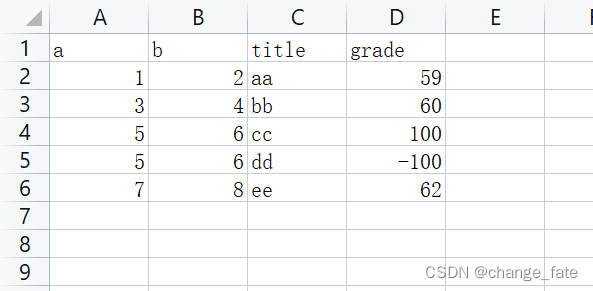

import pandas as pd
import numpy as np
pd.read_excel('./fakeExcel.xlsx', index_col=0)

pd.read_excel('fakeExcel.xlsx', header=0)

pd.read_excel('fakeExcel.xlsx', dtype={
'grade': np.float32
})
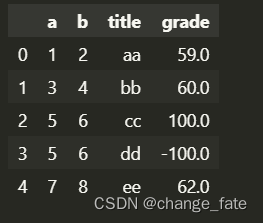
pd.read_excel('fakeExcel.xlsx', na_values={
'title': 'aa'
})
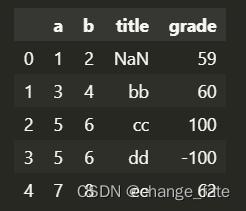
pd.read_excel('fakeExcel.xlsx', sheet_name=1, comment='#')
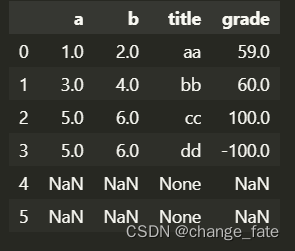
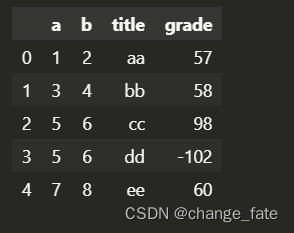
data['grade'] = data['grade'] - 2
data
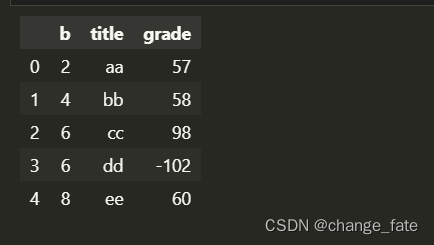
if True:
del data["a"]
else:
data = data.drop('a', axis=1)
data
data.rename(columns={ 'grade': 'grade2' })
data.columns = ['b', 'title', 'grade2']

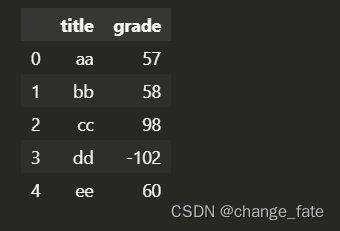
data[['title', 'grade']]
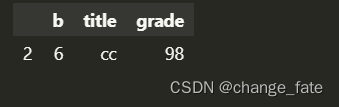
data[data['grade'] > 60]
data[data['title'] == 'bb']
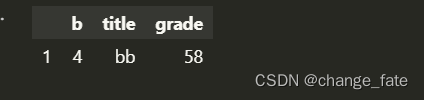
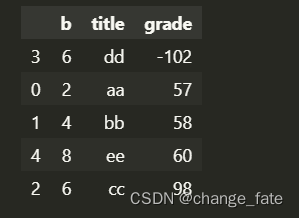
data.sort_values('grade', ascending = True)
pd.read_excel('fakeExcel.xlsx', header=0, names=[0,1,2])

data.drop(data.index[(newData['line3'] == '--')], inplace=True)
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns',None)
pd_data.head()
Original: https://blog.csdn.net/change_fate/article/details/126012860
Author: change_fate
Title: pandas read_excel 参数及使用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/675629/
转载文章受原作者版权保护。转载请注明原作者出处!