

1.dataframe的操作
1.1基本方法(后面记得加括号)
df.values # 查看所有元素
df[''].value_counts #统计某列中类的数量,参数:normalize(返回占比)、sort(排序)、
ascending (boolean, default False)(是否升序排列)。。
eg. df['company'].value_counts(normalize=True)
df.head # 查看前五行的数据
df.tail # 查看最后五行的数据
df.index # 查看索引
df.columns # 查看所有列名
df.dtype # 查看字段类型
df.size # 元素总数
df.ndim # 表的维度数
df.shape # 返回表的行数与列数
df.info # DataFrame的详细内容
df.describe # 生成描述性统计汇总,包括均值、max等
df.isna # 判断数据是否为缺失值,是的话返回true
df.isna().any() # 数据量较大时,使用any()查看某一列是否有缺失值
df.dropna # 删掉含有缺失值的数据
df.fillna # 填充数据,主要参数:value(填充的值)、 method(缺失值填充方法)
df.sort_values # 按照某列进行排序,eg.data.sort_values(by='salary') 也可用ascending
1.2 dataframe数据的查看方法
单列数据:df['col1']
单列多行:df['col1'][2:7]
多列多行:df[['col1','col2']][2:7]
多行数据:df[:][2:7] #这里使用df[2:7][:]也能得到同样的效果
1.3loc,iloc的查看方法
loc[行索引名称或条件,列索引名称]
iloc[行索引位置,列索引位置]
单列切片:df.loc[:,'col1']
df.iloc[:,3]
多列切片:df.loc[:,['col1','col2']]
df.iloc[:,[1,3]]
按需切片:df.loc[2:5,['col1','col2']]
df.iloc[2:5,[1,3]]
条件切片:df.loc[df['col1']=='245',['col1','col2']]
df.iloc[(df['col1']=='245').values,[1,5]]
1.4删除数据(及时更新)
删除某几行数据,inplace为True时在源数据上删除,False时需要新增数据集
df.drop(labels=range(1,11),axis=0,inplace=True)
删除某几列数据
df.drop(labels=['col1','col2'],axis=1,inplace=True)
1.5更新
df=df.reset_index(drop=True) #更新索引范围,不更新的话会导致报错keyerror
2.处理时间序列数据
2.1字符串时间转换为标准时间
df['time'] = pd.to_datetime(df['time'])
2.2加减时间
使用Timedelta,支持weeks,days,hours,minutes,seconds,但不支持月和年
df['time'] = df['time'] + pd.Timedelta(days=1)
df['time'] = df['time'] - pd.to_datetime('2016-1-1')
时间跨度计算:
df['time'].max() - df['time'].min()
3.分组聚合(groupby)
(1)基本方法
df.groupby(by='',axis=0,level=None,as_index=True,sort=True,group_keys=True
,squeeze=False).count()
by--分组的字段 level--标签所在级别,默认None as_index--聚合标签是否以df形式输出,
默认True,sort--是否对分组依据,分组标签进行排序,默认True group_keys--是否显示分组
标签名称,默认True squeeze--是否对返回数据进行降维,默认False
聚合函数有count,head,max,min,median,size,std,sum
(2)具体使用:如图包含三个字段,company、salary、age
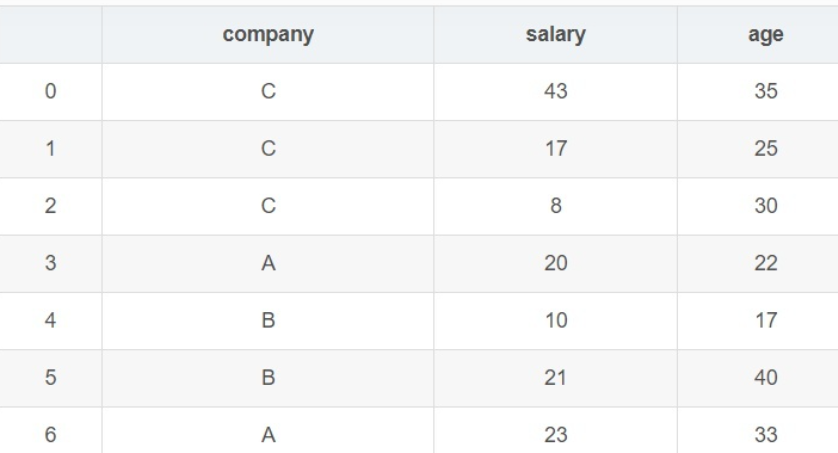

使用语句:
group = data.groupby("company")
结果:
In [8]: list(group)
Out[8]:
[('A', company salary age
3 A 20 22
6 A 23 33),
('B', company salary age
4 B 10 17
5 B 21 40
8 B 8 30),
('C', company salary age
0 C 43 35
1 C 17 25
2 C 8 30
7 C 49 19)]
可以清楚的看见,dataframe通过groupby(”company”),将df按company进行分组,得到了按company中不同的类别进行的分组,总的来说, groupby的过程就是将原有的 DataFrame按照 groupby的字段(这里是 company),划分为若干个 分组DataFrame,被分为多少个组就有多少个 分组DataFrame。
3.1agg、transform、apply方法的使用见下面的链接
参考链接:
groupby用法:Pandas教程 | 超好用的Groupby用法详解 – 知乎
pandas常见函数使用:Python笔记–Pandas常用函数汇总 – 知乎
Original: https://blog.csdn.net/xiaomingming99/article/details/122230443
Author: 独为我唱
Title: pandas使用方法汇总
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/675587/
转载文章受原作者版权保护。转载请注明原作者出处!