

文章目录
员工离职预测——逻辑回归的应用
开始这个案例之前,请先点击这里的数据集进行下载:HR_comma_sep.zip – 蓝奏云 (lanzout.com)
1 读取文件
我们使用pandas来读取输出并且进行预处理。首先是导入代码所需的包。
import numpy as np
import pandas as pd
接下来写一个函数用于读取CSV文件。
def load_data():
"""加载数据集"""
data = pd.read_csv("./HR_comma_sep.csv")
return data
data = load_data()
data
out:
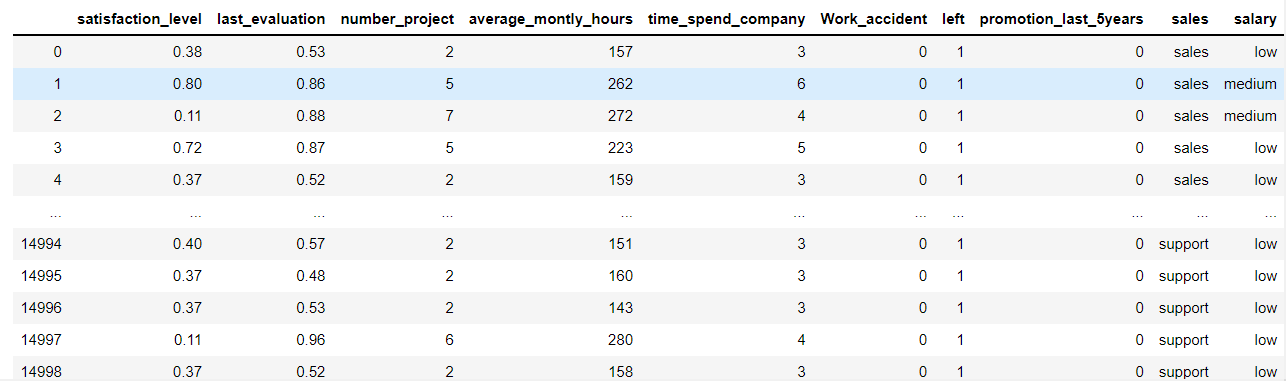

2 独热编码
从数据集中可以看到。有一些数据是非数值的,我们要将他转为数值型数据才能进行下面的工作。
from sklearn.preprocessing import OneHotEncoder
def one_hot(data):
"""将原数据中的非数值转为数值类型"""
oh = OneHotEncoder()
result = oh.fit_transform(data[["sales"]])
re = pd.DataFrame(result.toarray(),columns = oh.categories_[0],
index = data.index
)
result1 = oh.fit_transform(data[["salary"]])
re1 = pd.DataFrame(result1.toarray(),columns = oh.categories_[0] ,
index = data.index
)
data_final = pd.concat([data, re, re1],axis = 1)
data_final.drop('sales',inplace = True,axis = 1)
data_final.drop('salary',inplace = True,axis = 1)
return data_final
data = one_hot(data)
data
out:
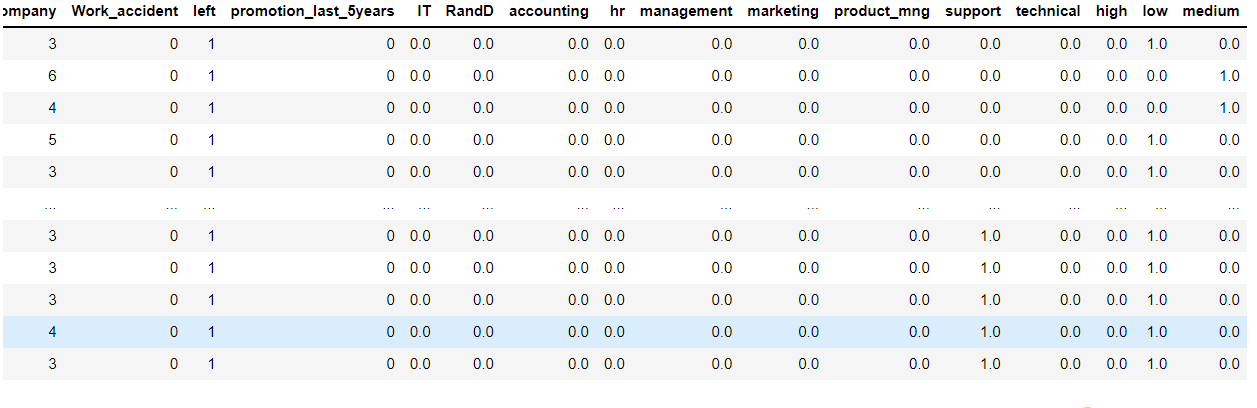
3 划分数据集
将数据集中的非数值数据转为独热编码后,下一步就是要将数据集划分为训练集和测试集了。
def split_data(data):
"""划分数据集"""
target = data.loc[:,'left']
data = data.drop(['left'],axis = 1)
x_train,x_test,y_train,y_test = train_test_split(data,target,random_state=88)
return x_train,x_test,y_train,y_test
x_train,x_test,y_train,y_test = split_data(data)
x_train
out:
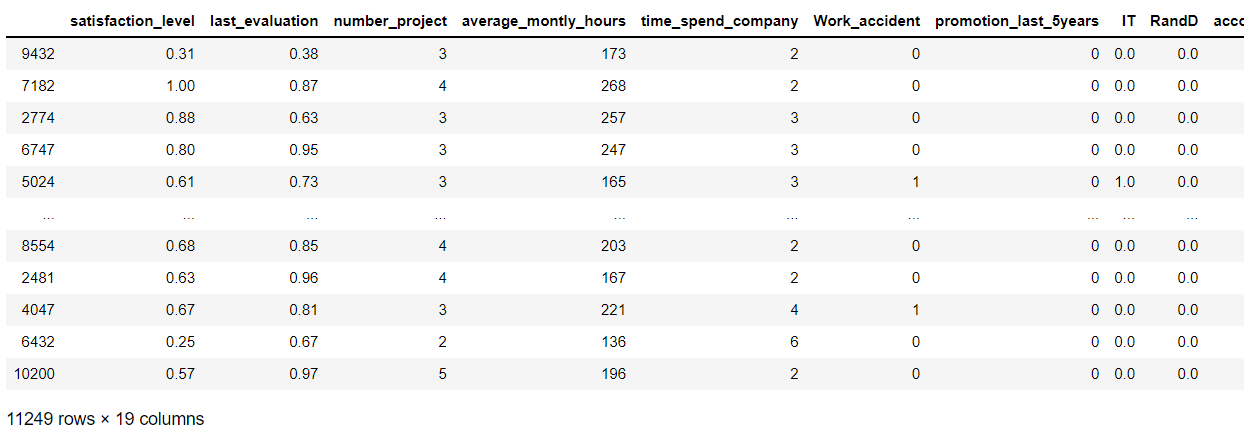
4 归一化
对于非标签数据来说,这些数据有些数值大,有些数值小,使得模型的收敛速度变慢,为此,我们需要进行归一化操作。
from sklearn.preprocessing import MinMaxScaler
def normalize(x_train,x_test):
"""归一化处理"""
transfer = MinMaxScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
return x_train,x_test
x_train,x_test = normalize(x_train,x_test)
x_train,x_test
out:
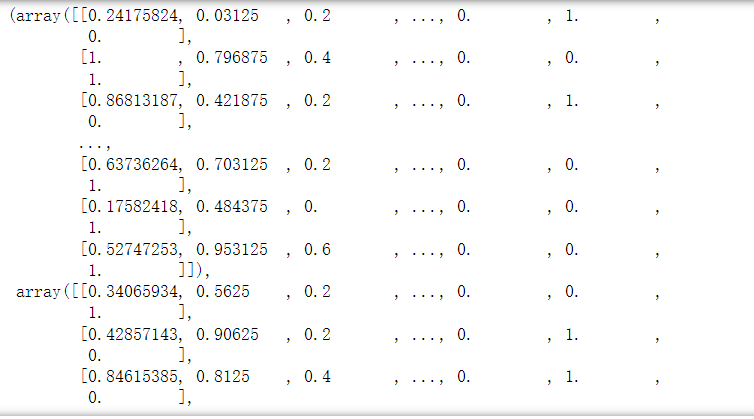
5 逻辑回归预测
当所有准备工作做完后,我们就要使用sklearn自带的包来训练模型了。
from sklearn.linear_model import LogisticRegression
"""利用逻辑回归来预测员工离职"""
estimitor = LogisticRegression()
estimitor.fit(x_train,y_train)
out:

6 模型预测及评估
当模型训练完成后,我们需要对模型进行预测和评估。
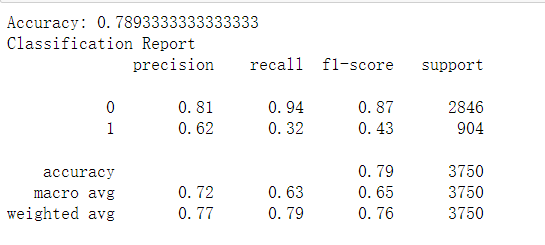
from sklearn.metrics import accuracy_score, classification_report
y_pred = estimitor.predict(x_test)
print('Accuracy:', accuracy_score(y_test,y_pred))
print('Classification Report')
print(classification_report(y_test, y_pred))
out:
Original: https://blog.csdn.net/chengyuhaomei520/article/details/124647266
Author: ArimaMisaki
Title: 机器学习实战(一)——员工离职预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/675227/
转载文章受原作者版权保护。转载请注明原作者出处!