

目录
前言
本文基于某招聘平台的数据分析师岗位招聘信息,首先利用pandas对数据进行处理与分析,然后利用pyecharts对各地区的招聘数量、平均工资、经验学历需求和招聘公司所在领域进行可视化的制图。
一、导入模块
import numpy as np
import pandas as pd
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
二、数据处理与分析
1.读取数据
df = pd.read_csv('xx直聘 数据分析师岗位 分析可视化/xx直聘数据分析师.csv')
df.head()


2.查看数据表格描述
df.info() #查看整体性描述

df.describe()
在这里发现count”福利”的后面几行是不满300的,说明数据缺失,要对缺失值进行处理。
3.处理重复值
df.duplicated().sum() #查看重复值

表面存在3处重复值。下面将重复值删除。
df.drop_duplicates(inplace = True) #删除重复值
4.处理缺失值
df.isnull().sum() #查看空值

df[df['福利'].isnull()] #查看"福利"空值所属信息
df['福利'].fillna('无', inplace=True) #用"无"填充福利列空值
“福利”列空值有26个,查看数值为空的列,用”无”将其填充。
df.rename(columns={'tags1':'涉及1','tags2':'涉及2','tags3':'涉及3','tags4':'涉及4','tags5':'涉及5','tags6':'涉及6'},inplace=True) #选择性重命名列名
df

df.fillna('未知',inplace=True) #用"未知"填充空值
df

5.提取地区信息
df['地区'] = df['标题'].apply(lambda x:x.split('·')[0]) #获取地区
df['地区'].unique()

6.提取经验信息
df['经验'].unique()

查看”经验”列,数据多且杂,对数据重命名分类,其中有一条异常数据,将其改为”经验不限”。
df['经验'].replace('在校/应届本科','经验不限本科', inplace=True) #重命名经验
df['经验'].replace('5天/周2个月本科','经验不限本科', inplace=True)
df['经验'].replace('经验不限学历不限','经验不限大专', inplace=True)
df['经验'].replace('5天/周6个月大专','经验不限大专', inplace=True)
df['经验'].replace('3天/周12个月本科','经验不限本科', inplace=True)
df['经验'].replace('3天/周3个月硕士','经验不限硕士', inplace=True)
df['经验'].replace('4天/周6个月硕士','经验不限硕士', inplace=True)
df['经验'].replace('3-5年学历不限','经验不限大专', inplace=True)
df['经验'].replace('5-10年大专','经验不限大专', inplace=True)
df['经验'].replace('3-5年大专','经验不限大专', inplace=True)
df['经验'].replace('5天/周6个月本科','经验不限本科', inplace=True)
df['经验'].replace('5天/周6个月本科','经验不限本科', inplace=True)
df['经验'].replace(' ','经验不限本科', inplace=True)
df['经验'].unique()

7.提取薪资信息
df['薪资'].unique()

df['m_max'] = df['薪资'].str.extract('(\d+)') #提取出最低薪资
df['m_min'] = df['薪资'].str.extract('(\d+)K') #提取出最高薪资
df['m_max'] = df['m_max'].apply('float64') #转换数据类型
df['m_min'] = df['m_min'].apply('float64')
df['平均薪资'] = (df['m_max']+df['m_min'])/2
df.head()
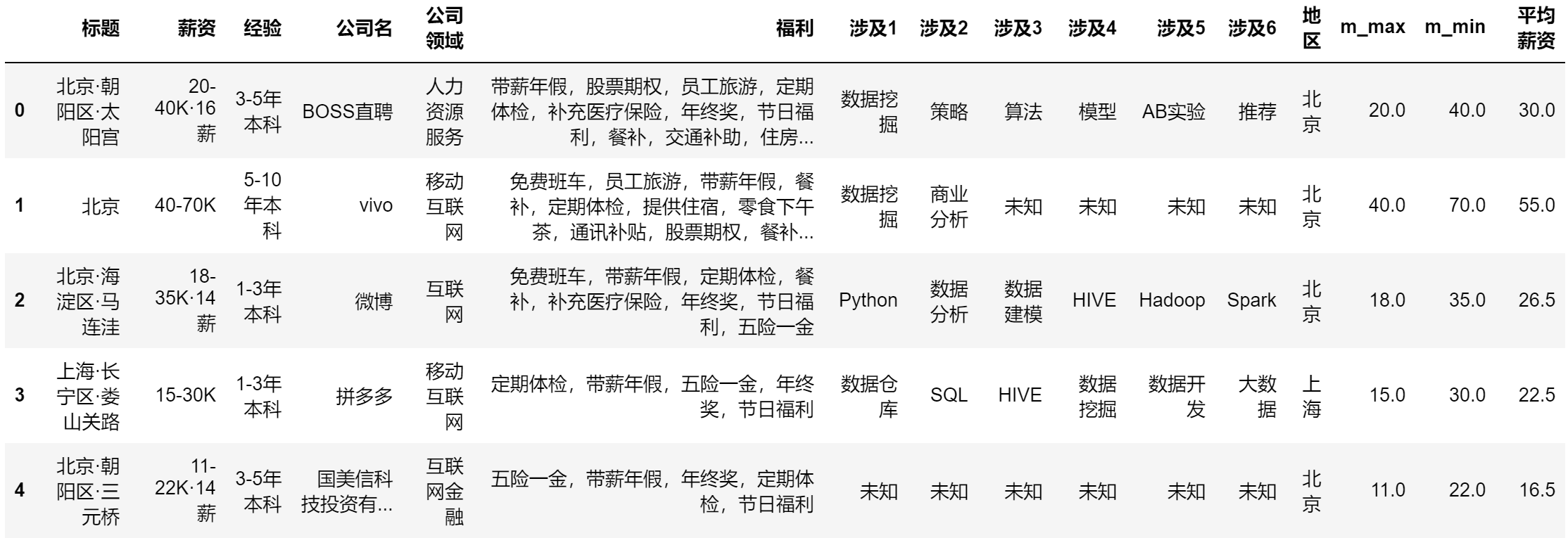
三、Pyecharts数据可视化
1.每个地区的招聘数量
#每个地区的招聘数量
dq = df.groupby('地区')['地区'].count()
dq_index = dq.index.tolist()
dq_value = dq.values.tolist()
bar1 = (
Bar(init_opts=opts.InitOpts(width='800px',height='400px',theme=ThemeType.MACARONS))
.add_xaxis(dq_index)
.add_yaxis('', dq_value, category_gap="50%")
.set_global_opts(
title_opts=opts.TitleOpts(title="每个地区的招聘数量"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-50)),
visualmap_opts=opts.VisualMapOpts(max_=80), #彩色块
datazoom_opts=opts.DataZoomOpts(), #拉动条形轴
)
)
bar1.render_notebook()

反映每个地区招聘数量的条形图绘制完成,颜色的深浅代表了照片数量的多少,同时可以通过拉动条形轴来选择地区的范围。
2.平均工资最高的地区
salary_average = df.groupby('地区')['平均薪资'].mean()
salary_average = salary_average.sort_values(ascending=False)[:10] #找出平均薪资最高的十个地区
salary_average

利用.sort_values()函数对各地区平均工资进行降序排列,找出平均工资最高的十个地区。
#平均薪资保留两位小数
s = []
for i in salary_average.values:
s.append(round(i, 2))
bar2 = (
Bar(init_opts=opts.InitOpts(width='800px', height='400px', theme=ThemeType.MACARONS))
.add_xaxis(salary_average.index.tolist())
.add_yaxis('', s, category_gap="50%")
.set_global_opts(
title_opts=opts.TitleOpts(title="平均工资最高的地区"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-40)),
yaxis_opts=opts.AxisOpts(name='K'),
visualmap_opts=opts.VisualMapOpts(max_=30)
)
)
bar2.render_notebook()
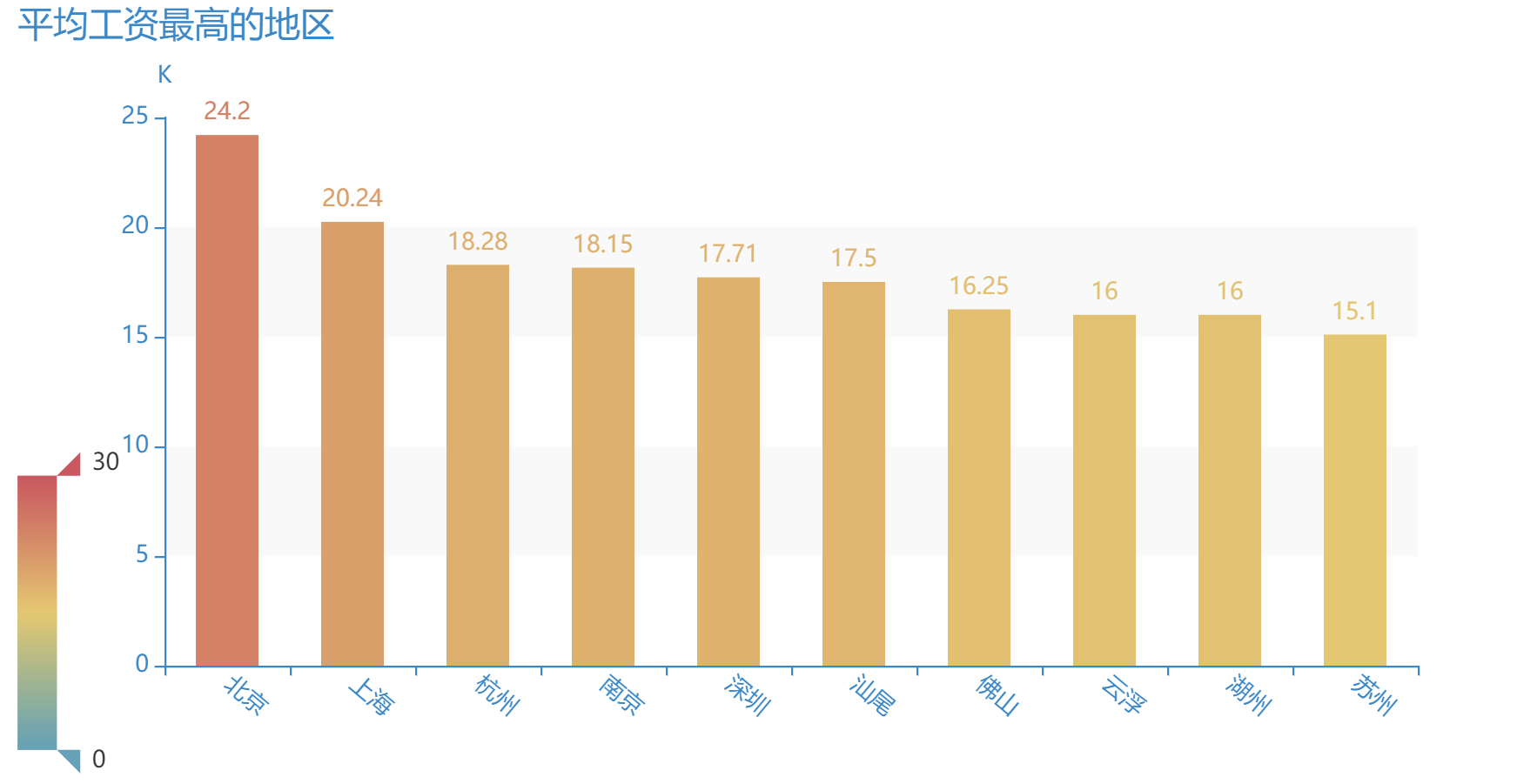
由图可知,数据分析师岗位平均工资最高的十个地区从高到低分别为北京、上海、杭州、南京、深圳、汕尾、佛山、云浮、湖州和苏州。
3.经验学历需求图
jingyan = df.groupby('经验')['标题'].count()
jingyan

首先对经验进行分组,获取数据分析师岗位对经验学历的需求信息。
#经验学历需求图
pair_1 = [(i, int(j)) for i, j in zip(jingyan.index,jingyan.values)]
pie = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS,width='1000px',height='600px'))
.add('', pair_1, radius=['40%', '70%'])
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
.set_global_opts(
title_opts=opts.TitleOpts(
title="经验学历需求图",
pos_left='center',
pos_top='center',
title_textstyle_opts=opts.TextStyleOpts(
color='black',
font_size=20,
font_weight='bold'
)
)
)
)
pie.render_notebook()

4.招聘公司所在领域
#招聘公司所在领域
gongsi = df.groupby('公司领域')['标题'].count()
pie1 = (
Pie(init_opts=opts.InitOpts(width='1000px',height='600px',theme=ThemeType.MACARONS))
.add(
"",
[list(z) for z in zip(gongsi.index.tolist(), gongsi.values.tolist())],
radius=["20%", "80%"],
center=["45%", "65%"],
rosetype="radius",
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(title_opts=opts.TitleOpts(title="招聘公司所在领域", pos_top="35%", pos_left="1%"))
)
pie1.render_notebook()

由图可知,数据分析师的岗位需求覆盖各个行业和领域,其中对数据分析师岗位需求最大的四个领域分别为互联网、电子商务、计算机软件和移动互联网。
Original: https://blog.csdn.net/JUV_7/article/details/121891956
Author: 黄金猎犬
Title: 数据分析师岗位 分析可视化
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/675151/
转载文章受原作者版权保护。转载请注明原作者出处!