

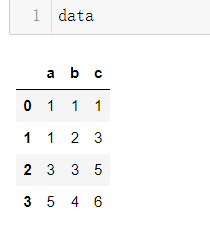
import pandas as pd # 导入包
data = pd.DataFrame({
'a':[1,1,3,5],
'b':[1,2,3,4],
'c':[1, 3, 5, 6]
}) #创建一个表

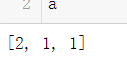
a = list(data["a"].value_counts()) # 获取a列不同数值出现的个数
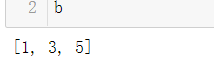
b = list(data["a"].value_counts().index) # 获取出现个数的具体数
y = []
for i,j in enumerate(a):
if j == 1:
index = data.loc[data.a==b[i]].index.to_list()
y.append(index[0])
sec_data = data.loc[y] # 找到表格中只出现过一行的数据,组成sec_data
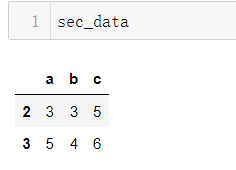
data – sec_data两个DataFrame进行相减,如下
data_1 = pd.concat([data, sec_data, sec_data]).drop_duplicates(keep=False)
data_1 # 两个dataframe进行求差
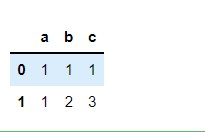
这样就可以把出现过一次记录的行全部删除了;下面内容是两个DataFrame求交集
data_2 = pd.merge(sec_data, data, how='inner')
data_2 # 两个dataframe求交集
本人水平有限,想到的思路目前是这样的,后续如有更好的方法会再进行改进,也希望读者批评指正!
Original: https://blog.csdn.net/m0_51099057/article/details/122342642
Author: 小杨的海洋
Title: 将DataFrame中出现过一次的行进行删除;两个DataFrame求交集、求差
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/674896/
转载文章受原作者版权保护。转载请注明原作者出处!