

爬虫项目讲解
我做的是爬取汽车之家全部车型以及配置表的爬虫代码
我们要爬取的就是这个网站https://www.autohome.com.cn
这边我已经爬取完毕,但是有一些错误,后续说
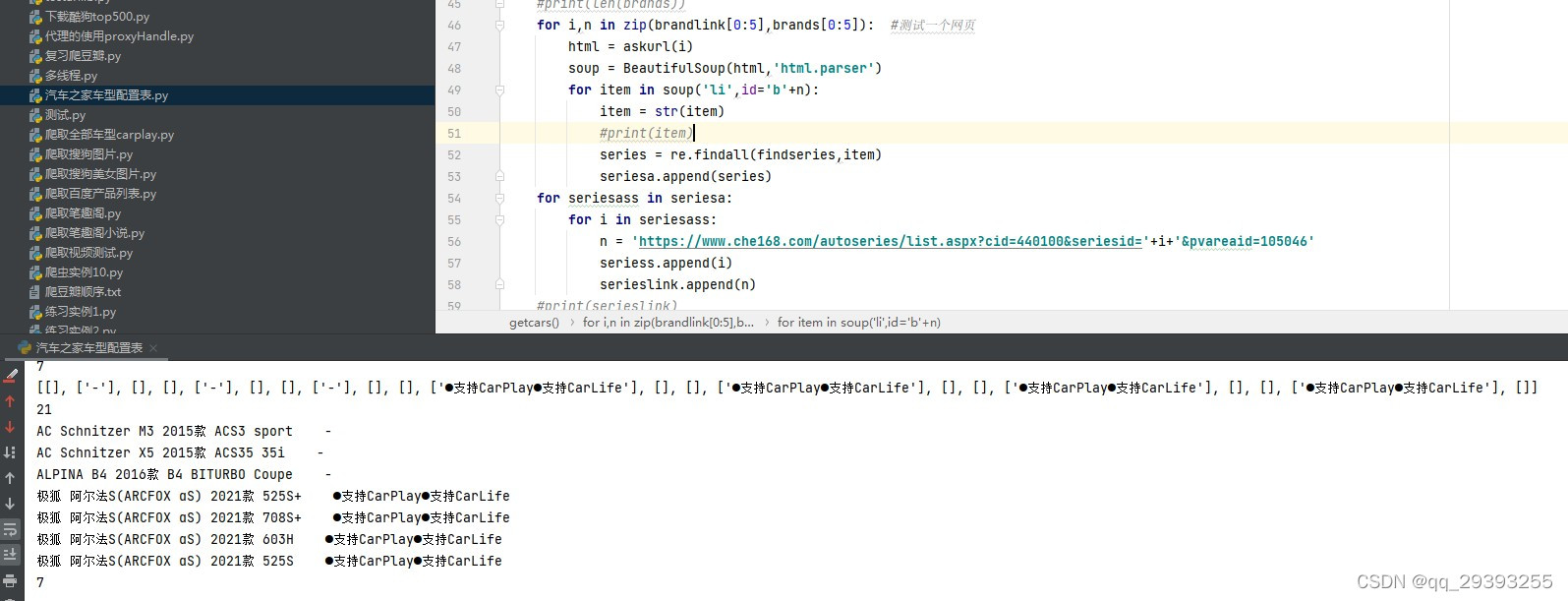

第一步先找到汽车之家全部的车型
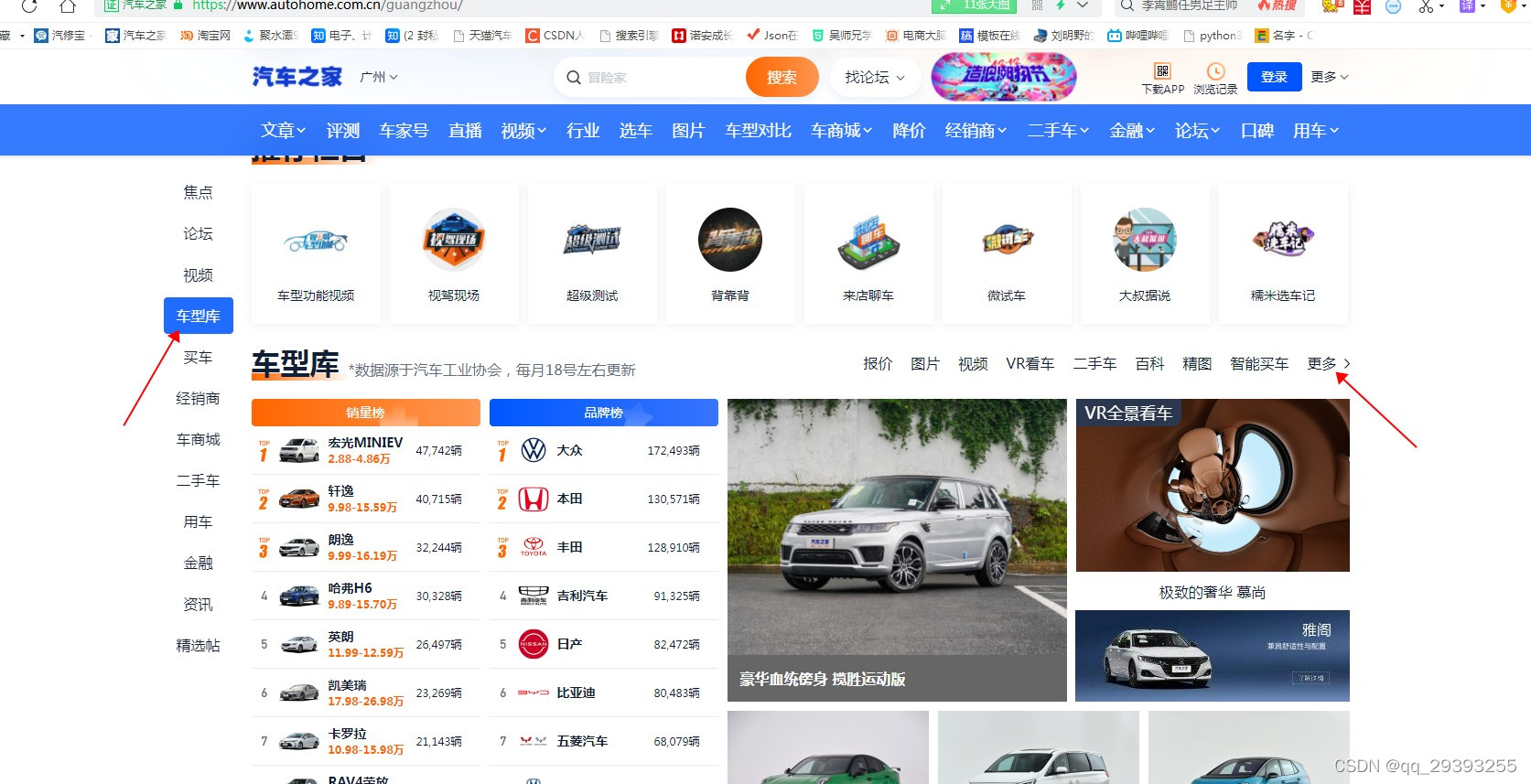
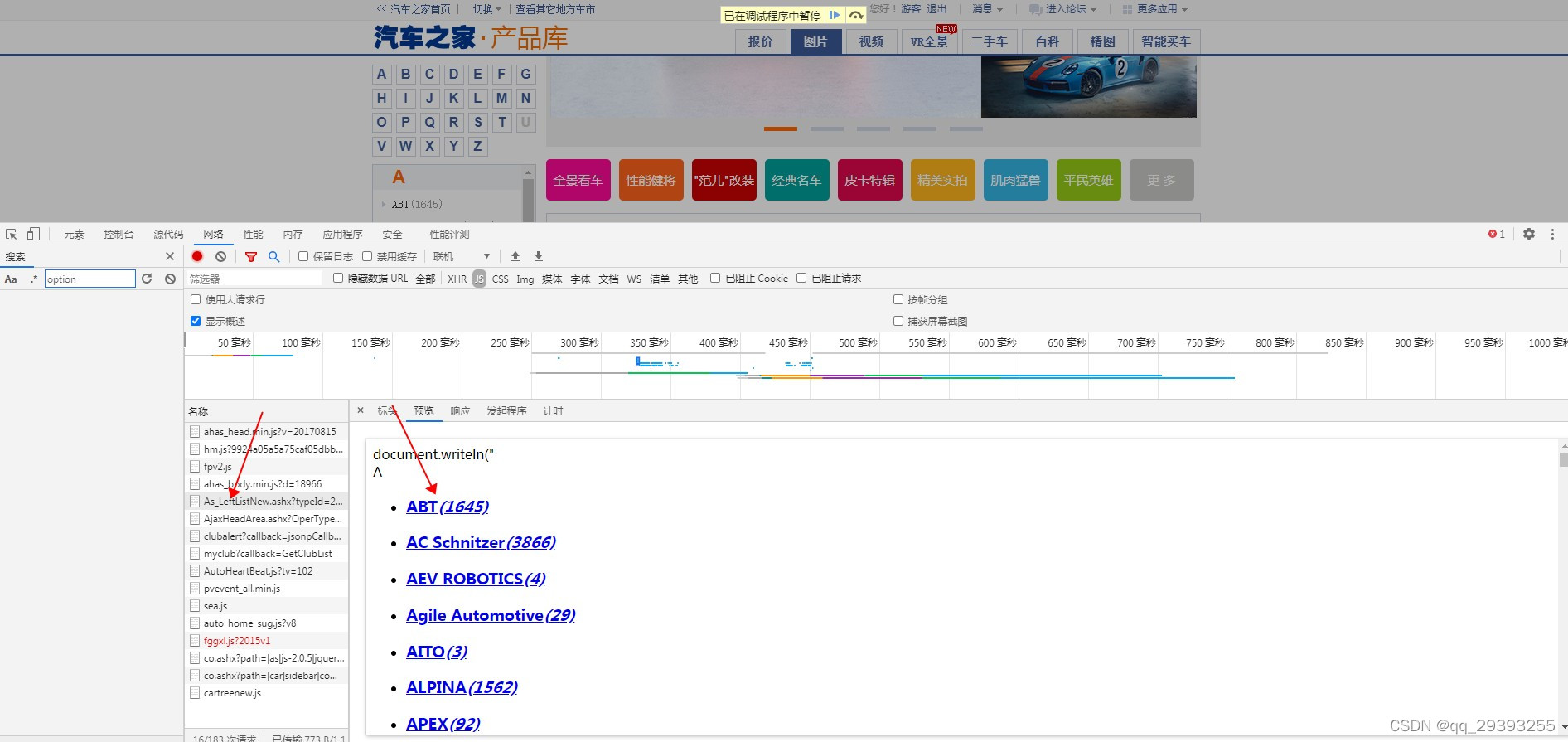
通过刷新网络然后就可以找到了车型库的链接了
原本的车型库地址是上面这个,但是后来搞糊涂了,typeid的值让我换成了1,就将错就错的一直写下去了,不过思路都是一样的(其实是原本的地址车型太多了,更容易出错)
我写的车型库地址是下面这个
找到了车型库的地址那我们就要把全部的车型都给爬出来先
第一步代码如下
#先引入几个爬虫常用的库,都是新手级别的,我也是刚学python几天,没事摸摸鱼练练手
import requests
import re
from bs4 import BeautifulSoup
#1.创建一个访问网页的函数
def askurl(url):
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36 QIHU 360SE"
}
html = requests.get(url,headers=headers)
return html.text
#2.先获取到车型库的车型
def getcars():
html = askurl('https://car.autohome.com.cn/AsLeftMenu/As_LeftListNew.ashx?typeId=1%20&brandId=134%20&fctId=0%20&seriesId=0')
print(html)
#3.运行代码
def main():
getcars()
#4.主程序
if __name__ == '__main__':
main()
运行得到以下的数据,通过观察,可以看到每个厂家都有固定的brand值,那这个brand值的作用就是可以从刚刚的车型库链接获取到车厂所有的车型,例如本田的可以获取到雅阁这个车型的某些值

我们把第一个brand的值替换掉车型库链接的brandid的值,就可以展开车厂所拥有的车型链接了
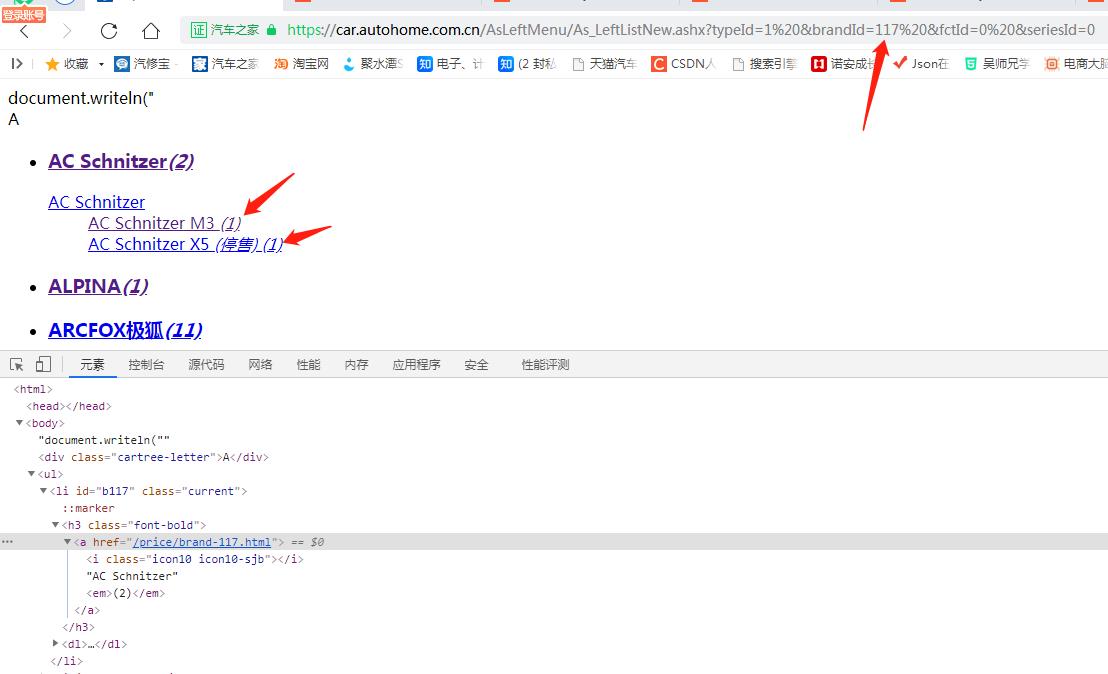
知道这个规律就可以继续往下走了,下一步就是获取全部的型号了
先写个正则找一下brand的值
findbrand = re.compile(r'<h3></h3>
然后准备爬取所有的brand的值了,代码如下
#先引入几个爬虫常用的库,都是新手级别的,我也是刚学python几天,没事摸摸鱼练练手
import requests
import re
from bs4 import BeautifulSoup
findbrand = re.compile(r'<h3></h3>
运行之后就发现问题了,解析完之后出现很多空列表(我也不知道是怎么产生的,有知道的希望可以给我评论一下)

所以我选择眼不见为净,空列表全部删除
brandlist = [] #清洗brand列表
brandlist = [ele for ele in brands if ele != []]#删除空数组
brandlist = list(chain.from_iterable(brandlist)) #合并小列表
然后开始爬取全部车厂的地址了
brandlink = [] #存放车厂链接地址
for i in brandlist:
u = 'https://car.autohome.com.cn/AsLeftMenu/As_LeftListNew.ashx?typeId=1%20&brandId='+str(i)+'%20&fctId=0%20&seriesId=0'
brandlinks.append(u)

获取到这些地址就可以查到全部的车型了,接下来继续往下走
for u in brandlinks[0:2]:#先测试两个车厂
html = askurl(u)
print(html)

通过获取到的车型来看,每个车型都是有对应的一个id,也就是series,所以接下来我们就先爬取全部的series值
for u,b in zip(brandlinks[0:2],brandlist[0:2]):
html = askurl(u)
#print(html)
soup = BeautifulSoup(html, 'html.parser')
for item in soup('li', id='b' + b):
item = str(item)
print(item)
serie = re.findall(findseries, item)
series.append(serie)
拿到车型的id之后就可以开始找到配置库了
按照正常的思路应该是直接到车型配置里面爬数据

但是试了一下发现取不到数据
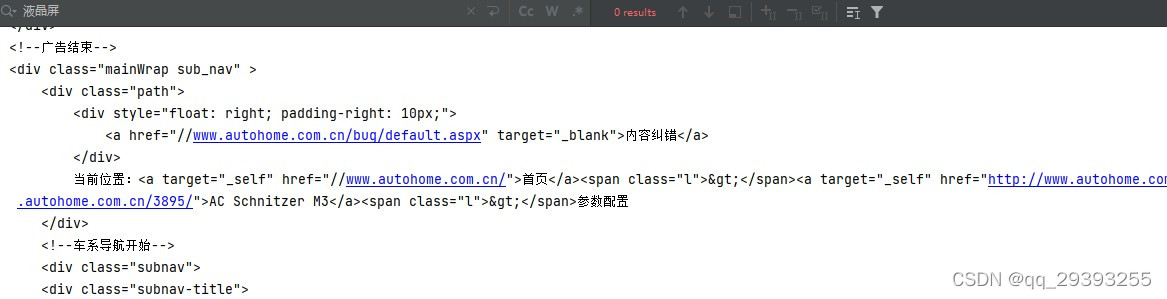
翻了好久的网络文件也没找到有用的,于是就打算换一种方式,去别的地方找找看
终于是从二手车那个板块也看到了配置表,但是我这个代码是前段时间写的,最近汽车之家二手车的板块已经改版了,图片已经截图不了了
就先按照我之前写的来讲,到了最后在讲一下现在的
以前的版本是直接在这个地址就可以查到了
https://dealer.autohome.com.cn/Price/_SpecConfig?SpecId=
现在新版的已经改成两个地址
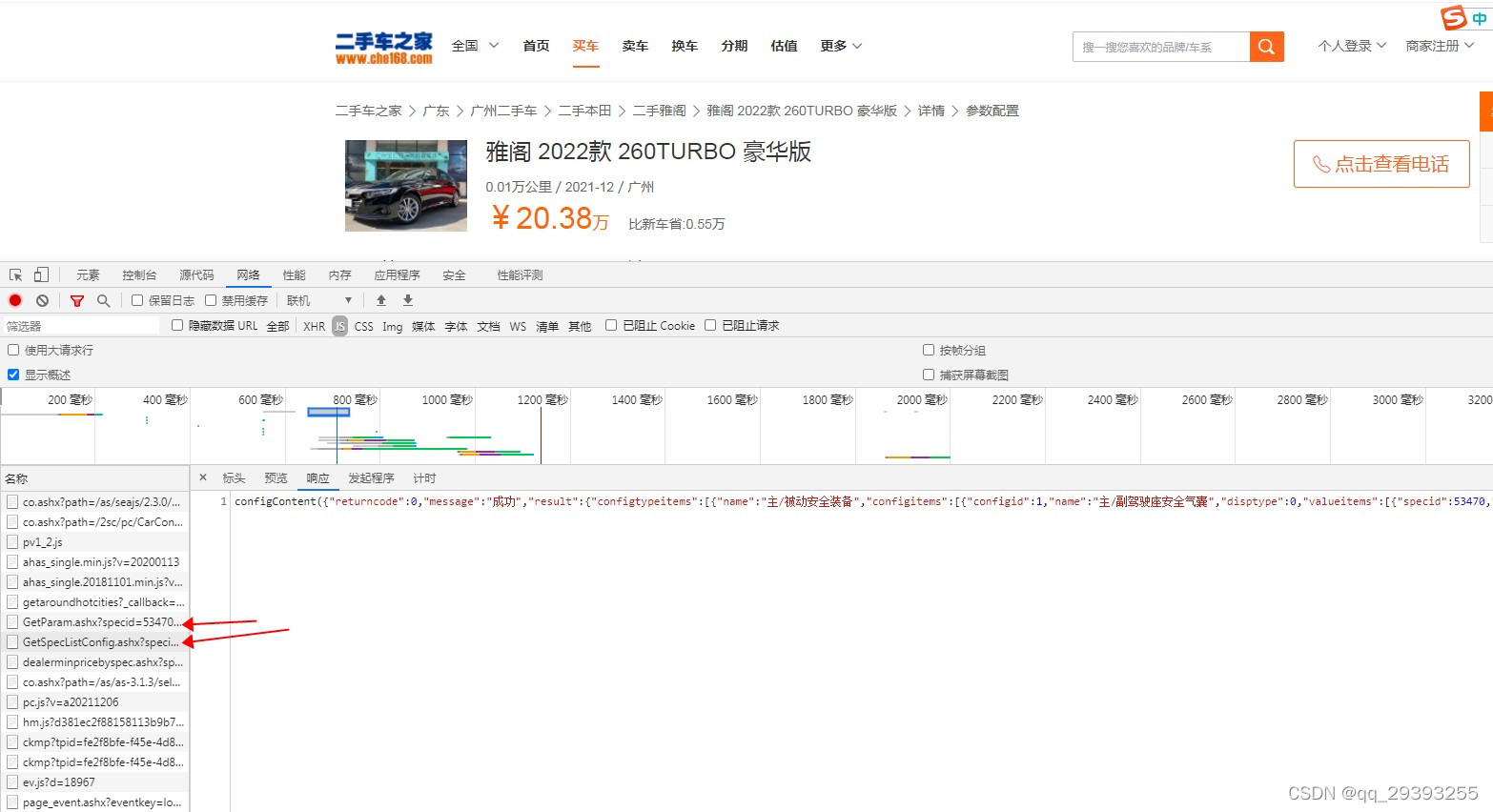
先对比一下老版的配置库和新版的区别吧

这个是老版的配置库,布局相当容易解析,而且只有一个库

这个是新版的,对于爬取难度相当麻烦,而且这只是其中一个库,配置总共分成了两个库,一个是存内饰数据,一个可以说是发动机型号动力之类的吧,这里就不深究了,继续老版的吧
从链接可以看出,两种配置库都是需要specid的值来查询,所以接下来我们就找specid的值吧
这里还是从汽车之家二手车里面看
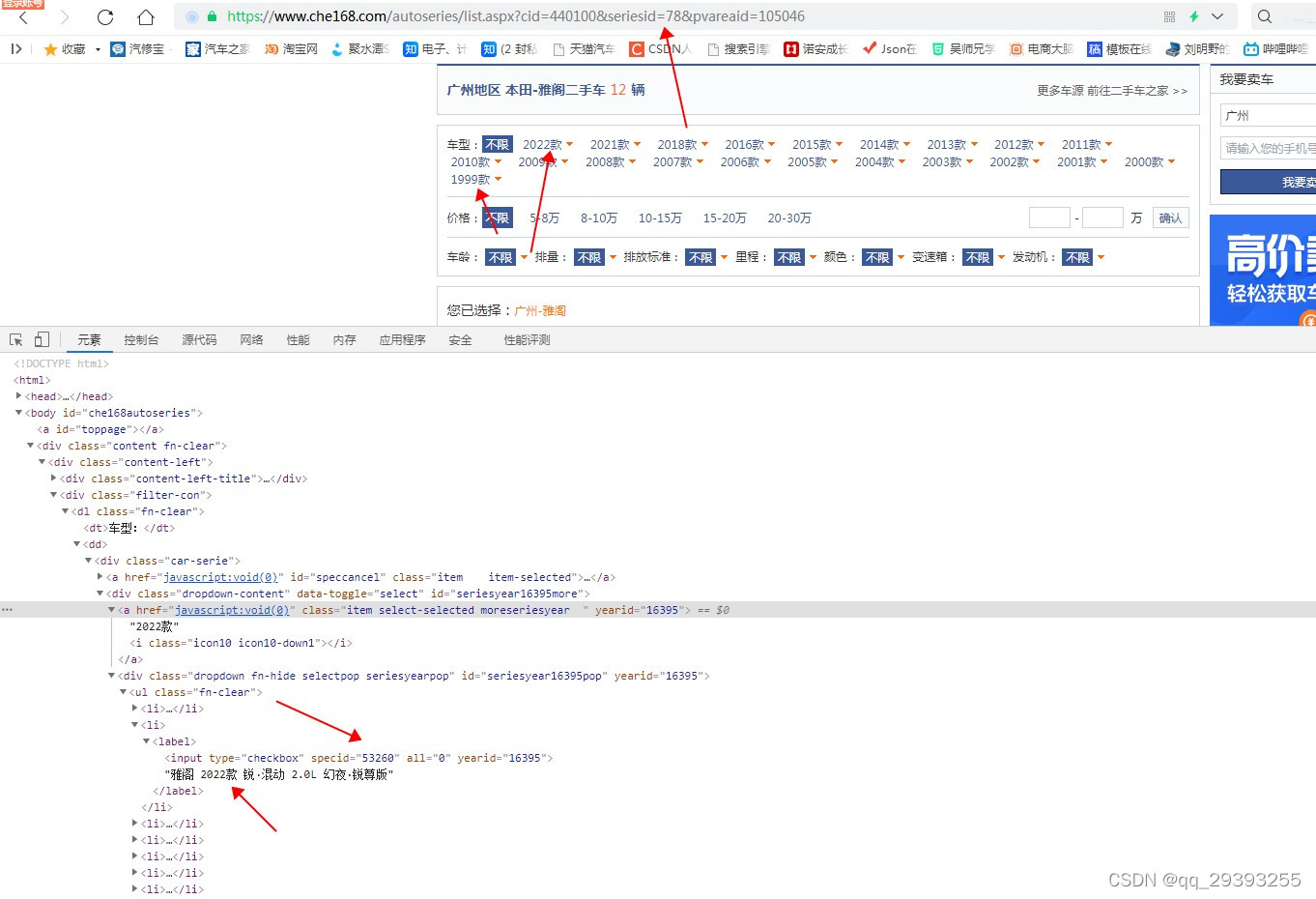
二手车的链接构成主要还是cid,seriesId,pvareaid。cid就是城市编号,seriesid就是之前我们拿到的车型id,最后一个我就没研究了,因为把最后一个删除了还是能拿到一样的页面
然后这个二手车的页面车型是真的很完善,年款配置版本全给写得清清楚楚,连1999年的雅阁都出来了
接下来就继续爬取specid吧
findcarname = re.compile(r'<input all=".*?specid=" \d{2,8}".*?>(.*?)<') findspecid="re.compile(r'<input" all=".*?specid=" (\d{2,8})".*?<') serieslink="[]" #存放二手车车型链接 carnames="[]" #存放车型年款版本 specids="[]" #存放specid for i in series: n="https://www.che168.com/autoseries/list.aspx?cid=440100&seriesid=" + serieslink.append(n) serieslink: print(i) html="askurl(i)" soup="BeautifulSoup(html,'html.parser')" #print(html) item soup: #print(item) carname="re.findall(findcarname,item)" carnames.append(carname) specid="re.findall(findspecid,item)" specids.append(specid) ele if !="[]]" # 合并小列表 print(carnames) print(specids)< code></')>
可以得到以下数据

得到了specid就可以直接查询配置库了
'https://dealer.autohome.com.cn/Price/_SpecConfig?SpecId='+specid
for i in specids:
url = 'https://dealer.autohome.com.cn/Price/_SpecConfig?SpecId=' + str(i)
html = askurl(url)
soup = BeautifulSoup(html, 'html.parser')
for item in soup:
item = str(item)
item = item.replace(' ', '').replace('\n', '').replace('\r', '')
print(item)
然后就能直接获取到配置啦

前面是功能名字,后面要么就是黑心圆点,代表的就是有这个功能,一个 – 号就是没有,需要爬取什么功能就写好re就好了
我这里就测试了一个车机互联功能,然后本文章说到的没解决的意外就来了
findcarplay = re.compile(r'手机互联/映射<td>(.*?)</td>')
carplays = []
carplay = re.findall(findcarplay, item)
# print(carplay)
carplays.append(carplay)
carplays = [ele for ele in carplays if ele != []]
carplays = list(chain.from_iterable(carplays)) # 合并小列表
for name, carplay in zip(carnames, carplays):
print(name + ' ' + carplay)
但是爬取出来的每次都会少两个配置,所以有懂的大佬也帮忙回复一下看看
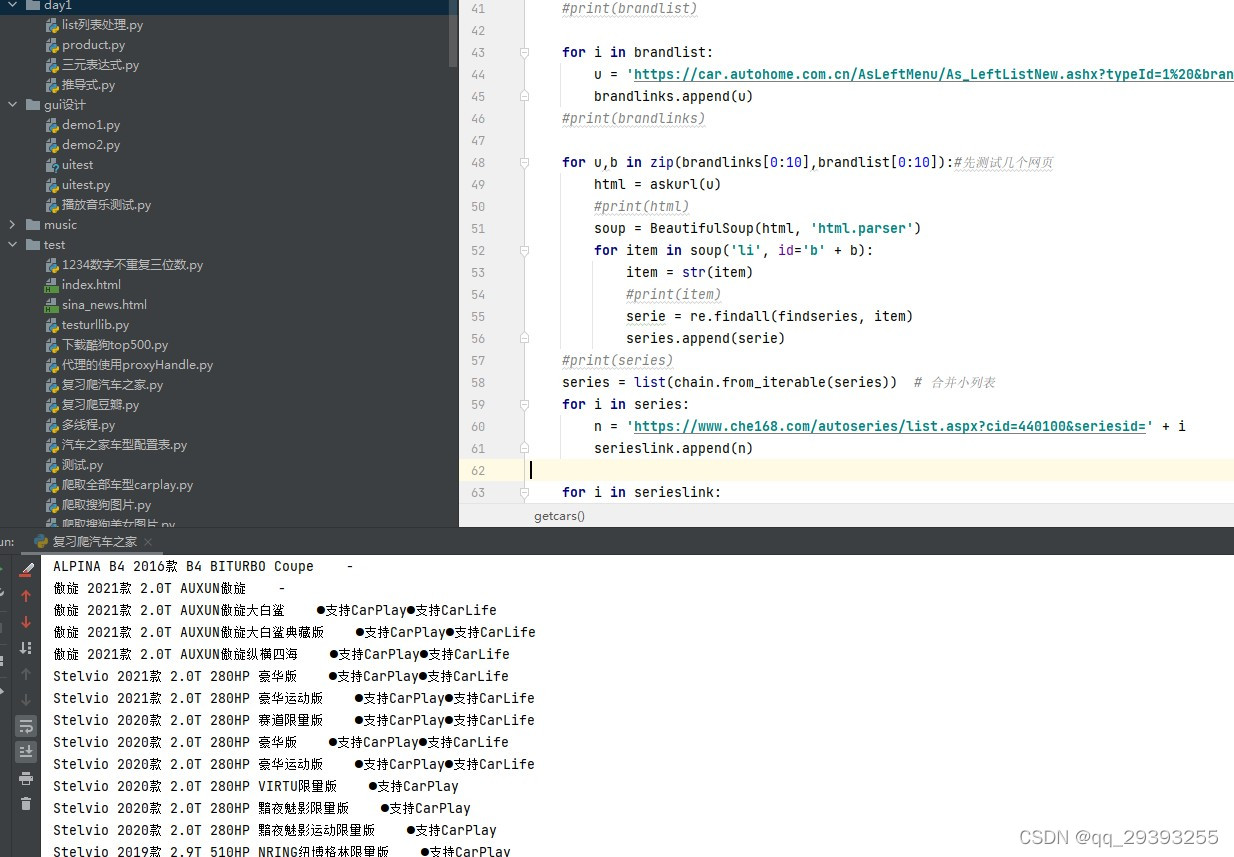
最后在附上全部代码
#先引入几个爬虫常用的库,都是新手级别的,我也是刚学python几天,没事摸摸鱼练练手
import requests
import re
from bs4 import BeautifulSoup
from itertools import chain
findbrand = re.compile(r'(.*?)(.*?)')
#1.创建一个访问网页的函数
def askurl(url):
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36 QIHU 360SE"
}
html = requests.get(url,headers=headers)
return html.text
#2.先获取到车型库的车型
def getcars():
brands = [] #存放获得的brand值
brandlist = [] #清洗brand列表
brandlinks = [] #存放车型链接地址
series = [] #存放车型id
serieslink = [] #存放二手车车型链接
carnames = [] #存放车型年款版本
specids = [] #存放specid
carplays = [] #存放需要的功能数据
html = askurl('https://car.autohome.com.cn/AsLeftMenu/As_LeftListNew.ashx?typeId=1%20&brandId=134%20&fctId=0%20&seriesId=0')
soup = BeautifulSoup(html, 'html.parser')
for item in soup:
item = str(item)
brand = re.findall(findbrand, item)
brands.append(brand)
#print(brands)
brandlist = [ele for ele in brands if ele != []] #删除空数组
brandlist = list(chain.from_iterable(brandlist)) #合并小列表
#print(brandlist)
for i in brandlist:
u = 'https://car.autohome.com.cn/AsLeftMenu/As_LeftListNew.ashx?typeId=1%20&brandId='+str(i)+'%20&fctId=0%20&seriesId=0'
brandlinks.append(u)
#print(brandlinks)
for u,b in zip(brandlinks[0:10],brandlist[0:10]):#先测试几个网页
html = askurl(u)
#print(html)
soup = BeautifulSoup(html, 'html.parser')
for item in soup('li', id='b' + b):
item = str(item)
#print(item)
serie = re.findall(findseries, item)
series.append(serie)
#print(series)
series = list(chain.from_iterable(series)) # 合并小列表
for i in series:
n = 'https://www.che168.com/autoseries/list.aspx?cid=440100&seriesid=' + i
serieslink.append(n)
for i in serieslink:
#print(i)
html = askurl(i)
soup = BeautifulSoup(html,'html.parser')
#print(html)
for item in soup:
item = str(item)
#print(item)
carname = re.findall(findcarname,item)
carnames.append(carname)
specid = re.findall(findspecid,item)
specids.append(specid)
specids = [ele for ele in specids if ele != []]
carnames = [ele for ele in carnames if ele != []]
specids = list(chain.from_iterable(specids)) # 合并小列表
carnames = list(chain.from_iterable(carnames)) # 合并小列表
#print(carnames)
#print(specids)
for i in specids:
url = 'https://dealer.autohome.com.cn/Price/_SpecConfig?SpecId=' + str(i)
html = askurl(url)
soup = BeautifulSoup(html, 'html.parser')
for item in soup:
item = str(item)
item = item.replace(' ', '').replace('\n', '').replace('\r', '')
#print(item)
carplay = re.findall(findcarplay, item)
# print(carplay)
carplays.append(carplay)
carplays = [ele for ele in carplays if ele != []]
carplays = list(chain.from_iterable(carplays)) # 合并小列表
for name, carplay in zip(carnames, carplays):
print(name + ' ' + carplay)
#3.运行代码
def main():
getcars()
#4.主程序
if __name__ == '__main__':
main()
Original: https://blog.csdn.net/qq_29393255/article/details/121731183
Author: qq_29393255
Title: python爬虫re+requests+bs4爬取汽车之家全部过程,附代码。支持互联网免费至上,看了全部关于汽车之家的文章都是收费的,我很看不过去
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/640344/
转载文章受原作者版权保护。转载请注明原作者出处!