

一、《 AdaPrompt : Adaptive Prompt-based Finetuning for Relation Extraction 》

【摘要】
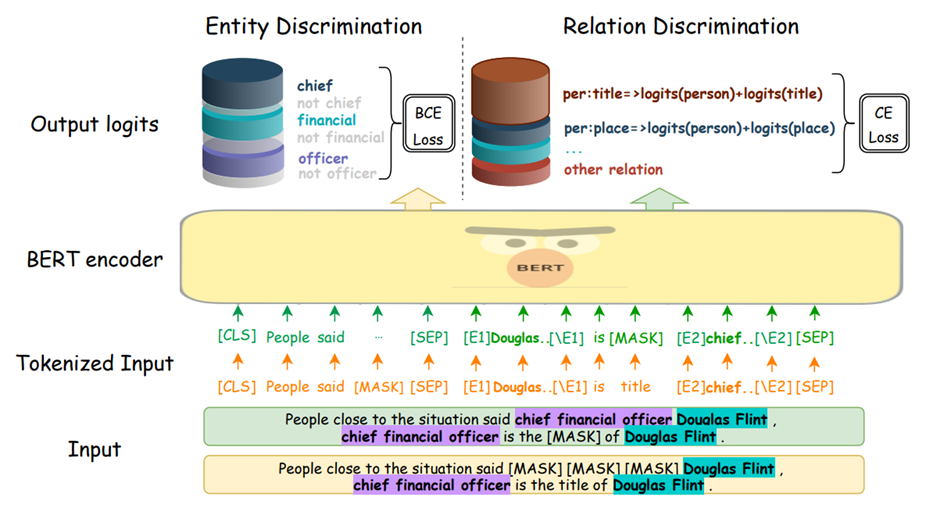
本文,我们将关系抽取任务作为掩码语言模型建模,并提出一个新的自适应基于prompt 的微调方法,我们提出一个自适应标签词选择机制,其可以把关系标签分散到可变数量的标签token 中,以处理复杂的多标签空间。我们进一步提出一个辅助实体辨别器,以增强模型对上下文信息的学习。
【引言】
最近,基于自监督的预训练语言模型,例如BERT ,其可以学习丰富的上下文信息,并在下游任务中取得良好的结果。然而,这些传统的微调模型严重依赖于标注数据,而标注数据是非常耗时耗力,导致扩展性不好。在最近几年发现,预训练语言模型通过预测被MASK 的词,可以获得两个实体之间的一个高置信度的关系知识,但是在预训练和微调之间存在的gap 导致这种知识在微调的时候不能很好的获得。因此,各种其他微调的方法开始出现,把预训练语言模型通过完成”完形填空”任务,直接将其作为一个预测器,这样就解决了预训练和微调之间的gap 。
受此启发,我们探索基于prompt 的微调方法在RE 上的应用。但是仍然存在一些困难,第一,RE 任务的标签空间非常大,并且很复杂,因此使用普通的标签搜索或者verbalization algorithm 是非常困难的。并且,关系标签拥有明确的语义含义,例如,对于关系标签”was_born_in “,其很难找到一个token 代表其意思。第二,RE 模型非常依赖于实体的信息,并且上下文信息是支撑其预测的主要来源。普通的基于prompt 的方法把所有token 都同等对待,因此不可避免的导致对上下文信息理解的不够全面。
为了解决这些限制,我们针对RE 提出一个新的自适应基于prompt 的微调方法。具体的,我们提出一个自适应标签词选择机制,可以把关系标签分散到可变数量的标签token 上。因此这个模型可以处理多关系标签以及它们之间更加复杂的语义含义。进一步的,我们提出一个辅助的实体辨别器,增强模型对上下文信息的学习。换句话说,在模型知道关系类型的时候要去预测起初的实体。我们的方法是与模型无关的,其可以用于任何预训练语言模型。
【模型】
1、输入
给定包含两个实体的一条句子:
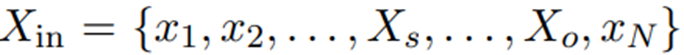
将其编码输入到预训练语言模型,在之前的基于预训练语言模型的方法,其编码为:
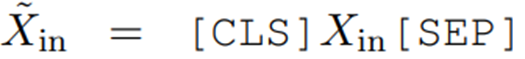
但基于prompt 的方法中,我们要用template T 将其编码为:
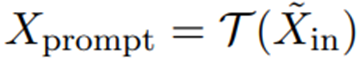
这种编码方法,里面包含[MASK]标记,那么将其输入掩码语言模型,我们要预测其属于类别y 的概率:
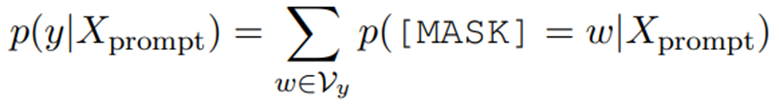
这里的w 是类别y 的标签词。这样就解决了预训练和微调之间的gap 。使其可以有效用于全监督和小样本的场景。
2、构建prompt
有其他的研究者使用T5 在训练集上生成template ,然后使用验证集选择最好的template 。但这样使用了生成模型生成template ,并对于每一个template 都微调并是非常耗时耗力的,特别是在全样本场景中。并且在一些研究中显示这种方法和基于手工模板的方法在结果上相当,很少超过。基于这种思想,我们使用领域知识去针对RE 任务生成统一的template 。原始BERT 模型用一些词预测[MASK],这些词是和原始关系非常相关的,并具有一定的语法和词性信息。这些证据清楚的表明了隐含在语言模型中的知识。受此启发,那么基于prompt 的方法的输入可以表示为:
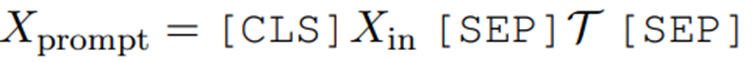
为了强调实体,我们在模板中的实体两侧也加入了标签,具体template T 可以表示为两种形式:”[E1] Douglas Flint [/E1]is [MASK] [E2] chief financial officer [/E2].”和”The relation between [E1]Xs [/E1] and [E2] Xo [/E2 ] is [MASK].”。
3、自适应词选择
在这一部分,我们的目标是构建M :Y->V 。其可以把标签词映射到词典空间V 。对于Y 中的每个类别标签,针对词典空间V 构建一个剪枝的集合,可以使用初始的语言模型基于最大似然选择概率最大的前k 个词最为当前类别的词集合。但这种方法有几个问题:实施上比较困难,对于RE 任务,类别数比较多,那么搜索空间就是指数级的。其次,因为验证集都非常大,这种方法非常耗时,并且计算复杂度非常高。因为考虑到类别本身就包含了丰富的语义信息,我们直接把标签词分解为多个词作为标签词集合。例如对于标签”per:city_of_death “,我们可以将其分解为:
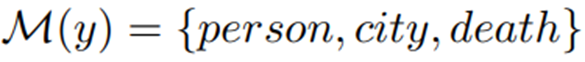
那么基于prompt 预测类别的概率公式就为:
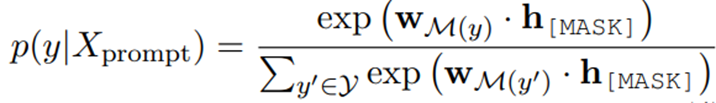 表示基于prompt 的输入进入模型后,对应的[MASK]位置的输出,表示在预训练中的softmax 之前的标签词的向量加和。其计算过程应该是对于每一个关系,先对其分解后的关系标签用预训练模型得到embedding表示,然后求和,乘以,得到当前关系的logits ,然后对所有关系进行归一化。
表示基于prompt 的输入进入模型后,对应的[MASK]位置的输出,表示在预训练中的softmax 之前的标签词的向量加和。其计算过程应该是对于每一个关系,先对其分解后的关系标签用预训练模型得到embedding表示,然后求和,乘以,得到当前关系的logits ,然后对所有关系进行归一化。
4、损失函数
其包含关系损失和实体损失。关系损失就是基于prompt 预测关系,具体为:
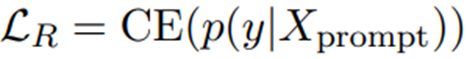
实体损失为知道关系和其中一个实体预测另一个实体:
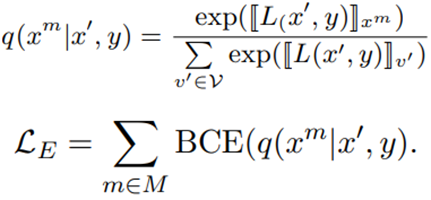
最后的损失为两者相加:
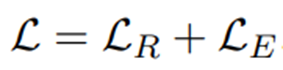
二、《 PTR: Prompt Tuning with Rules for Text Classification 》
【摘要】
微调预训练的语言模型在很多NLP 任务上都取得了很好的效果,通过使用另外的prompt 去微调预训练语言模型,我们可以进一步利用预训练语言模型中的知识用于下游任务。Prompt turning 在很多小样本分类任务上已经取得了很好的效果,例如情感分类和自然语言推理。然而,手动设计这些prompt 即麻烦又容易出错。对于那些自动生成的prompt ,在非小样本场景中验证其的有效性又很费时费力。因此,使用prompt turning 处理多类分类问题仍然是一个挑战。在本文中,我们提出了一个针对多类分类问题的prompt turning with rules (PTR )方法,其使用逻辑规则构建包含很多sub-prompt 的promps 。通过这种方式,PTR 可以把每一类的先验知识编码入prompt turning 。
【引言】
最近,各种预训练语言模型在NLU 和NLG 任务上取得了很好的效果。通过使用自监督学习,预训练语言模型可以从大型语料中捕获丰富的语言、语义、句法和词级别的知识,这是预训练语言模型取得成功的关键。通过在一些特定任务的数据上进行微调预训练语言模型,预训练语言模型中的丰富的知识可以被迁移到下游任务中。在过去的这几年,基于预训练模型进行微调已经在很多NLP 任务上展示了很好的效果。基于预训练模型进行微调而不是从头开始训练已经成为NLP 社区的一个共识。
尽管基于预训练模型进行微调已经取得了很好的效果,但是最近的研究发现其仍然存在一个很大的问题,就是预训练和微调之间存在一个gap ,其在微调的时候不能充分利用预训练语言模型的所有优势。例如,预训练的时候都是去预测目标词(序列语言模型和掩码语言模型),而下游任务是以另一个形式出现(分类,生成,序列标注)。这种gap 阻碍预训练语言模型将其知识迁移和应用到下游任务中。
为了解决这个问题,prompt turning 被提出,一个经典的prompt 包括一个模板(template )和一系列的标签词,这些标签词是预测template 中的[MASK]的候选词。通过把原始输入转化为带prompt template 的输入,然后预测[MASK],并将其映射到相应的标签上。Prompt turning 可以把二分类情感任务转化为一个cloze-style 任务。或者换句话说,通过查看预训练语言模型在[MASK]位置预测出的词,我们可以决定这条数据的情感是positive 还是negative 。除了情感分类任务,目前存在的prompt turning 方法在很多其他类别少的任务上都取得了很好的效果。
然而,对于多个类别的任务,找到合适的template 和合适的标签词去辨别不同的类别十分困难。例如,在关系分类中,需要模型预测两个实体在一个句子中的语义关系。给定关系”person:parent “和”organization:parent “,很难找到标签词去辨别他们。一个最直接的方法是自动生成prompt 。尽管自动生成prompt 可以避免人工,但是很多自动生成的prompt 不能比人们自己设计的prompt 效果好。并且,自动生成的prompt 需要额外的计算消耗。这种额外的计算消耗使得其更加适合小样本学习。
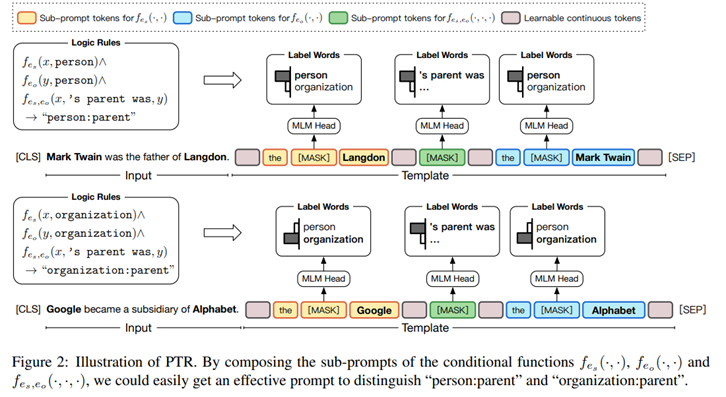
在这篇文章中,我们提出了针对多类分类问题的prompt turning with rules (PTR )。我们首先设计一些sub-prompt ,然后应用逻辑规则将这些sub-prompt 组合成特定任务的prompt 。我们通过这种方法,一方面可以加入先验知识,另一方面设计prompt 的效率更高。
【模型】
1、输入
在原始输入后面加入两个实体,其包含3 个[MASK],分别预测两个实体的类型,和两个实体之间的关系。
2、损失函数
其包括两部分:mlm损失,关系损失。
(1)预处理。首先对于设计的prompt 输入到bert 后,取[MASK]标记对应位置的输出(768 维,具体为batch_size,3,76 8 ),分别乘以,三种[MASK]的标签集合对应的embedding (BERT 中的),得到三种mask 分别对应各自标签集合的logits ,这里因为三种mask 分别是实体的类型、两个实体是否存在关系、实体类型,因此,得到logits 维度从768 变为,实体类型的个数,2 ,实体类型的个数。对应3 个list ,维度分别为[batch_size ,实体类型个数];[batch_size ,2 ];[batch_size ,实体类型个数]。
(2)mlm损失。针对正确的关系类别,分别对3 种mask 计算损失(交叉熵损失),然后求平均。
(3)关系损失。针对所有关系上正确的mlm 标签,使用上述logits 分别计算在每个关系上的logits ,其是三种mask 的加和,得到在所有关系上的logits ,再与正确标签求损失。
Original: https://blog.csdn.net/qq_42393368/article/details/122021536
Author: 爱工作的小小酥
Title: 基于prompt的关系抽取方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530929/
转载文章受原作者版权保护。转载请注明原作者出处!