

目录 手敲敲代码才有用(#^.^#)
Pandas 是基于 Numpy的一种工具
Pandas 的 数据结构有 Series/ DataFrame/Time-Series /Panel /Panel4D PanelIND
我们主要用的就是Series和 DataFrame, 多个 Series 其实就是 DataFrame U·ェ·U
Series 的介绍与操作
1、介绍:是一维数组, 和Python中的list 很像,在图像上面就是 一列,但是多了一列索引
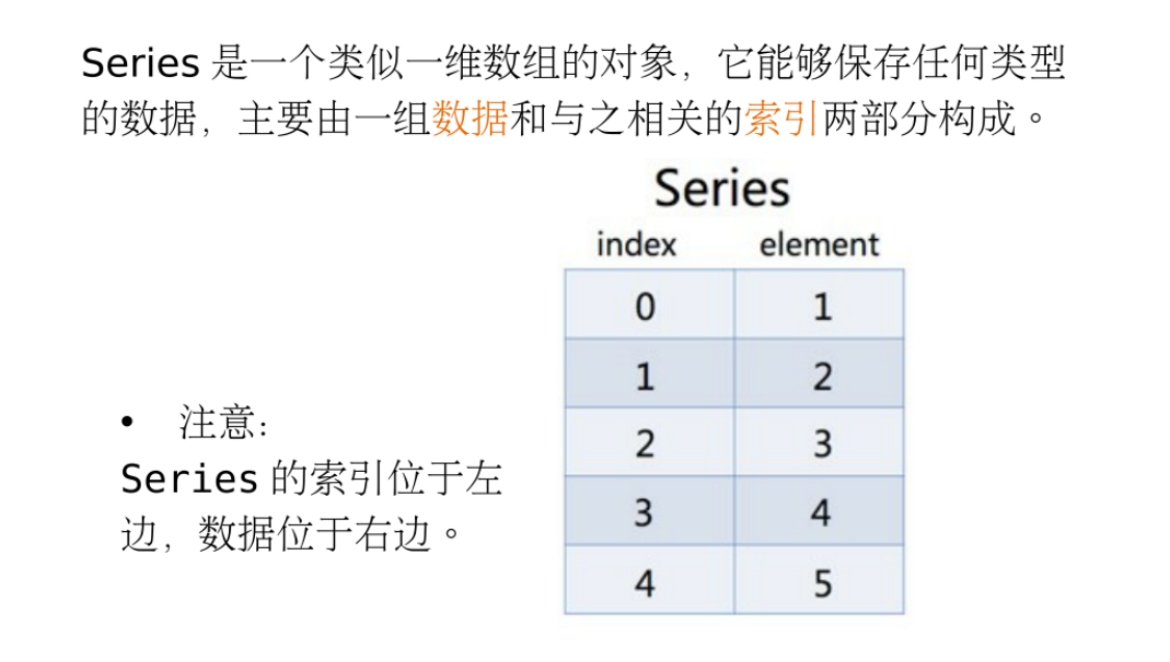

2、操作
*创建series 有两种方法,直接pd.Series /或者用字典,字典的key就直接是索引 ,参数是index。
*索引有两种:标签索引是自己定制的索引,参数中是loc; 位置索引是iloc,程序自动从0开始设置索引
创建series类 的对象
import pandas as pd
import numpy as np
创建Series 对象,并且添加索引
ser1 = pd.Series([1,2,3,4,5], index = ['a', 'b', 'c', 'd', 'e'])
print('ser1是:\n',ser1)
使用字典dict 来创建一个Series 类对象: 字典就直接是索引了
year_data = {2001: 17, 2002: 18, 2003: 20}
ser2 = pd.Series(year_data)
print('ser2是\n',ser2)
series的索引和值属性
1.用两个属性来索引:index, values
print('用index属性:\n',ser1.index)
print('用values属性\n',ser1.values)
2.直接用下标来直接获取
print('用默认数字下标',ser1[3])
print('用定制的下标',ser1['c'])
3.通过loc,iloc来访问。 loc 是通过自己定的标签索引,iloc默认的索引
print('通过loc\n',ser1.loc['b'])
#print('通过iloc\n',ser1.iloc[0])
loc,iloc切片
print(' loc 通过标签索引切片\n',ser1.loc['a', 'd']) #这里出来就应该是abcd和对应的values
print('iloc 通过位置(默认)标签索引切片\n',ser1.iloc[2:4])
print('双括号 应该出来的指定的这两行\n',ser1[['a', 'c']])
print('双括号 应该出来指定的这两行\n',ser1[[0,2]])
DataFrame 的介绍和操作:
1.介绍:DataFrame 就是许多个 Series 排在一起,成了一张二维的表格,想象一下 Excel / 或者数据库里面的table,这两样就是典型的DataFrame数据结构
2.操作
- 也有两种创建方法
*索引和Series类似
用np.array 的方式创建DataFrame
这是一个两行三列的表格
demo_arr = np.array([['a', 'b', 'c'],['d', 'e', 'f']])
df1 = pd.DataFrame(demo_arr, columns=['no1', 'no2', 'no3'], index=[1,2]) # 表【1.1】
print(df1)
用字典 创建DataFrame
这里的key是column(列)的标签,因为 dataframe相当于是 series 的一个列的扩延,主要关注列
demo_dic = {'site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
如果要加上index的标签,就在 DataFrame的参数中添加即可
df_obj = pd.DataFrame(demo_dic, index=['1', '2', '3']) # 默认的本来第0,1,2
print(df_obj)
索引使用
1.列索引
1.1可以像list一样的 列 索引
element1 = df1['no2']
print('element的数据是:\n',element1)
print(type(element1)) # 返回的是Series
1.2.也可以用调用属性的方式来 列索引
element2 = df1.no2
print('element2 是\n',element2)
print(type(element2))
1.3.使用列索引来获取多列数据, 返回的结果是一个DataFrame 对象
element3 = df1[['no2', 'no3']]
print('element 是',element3)
print(type(element3)) # 啊,运行出来真的是DataFrame
#2.行索引
2.1. 通过标签索引(loc) 和位置索引(iloc) 来访问行
demo2 = np.array([['a', 'b', 'c'],['d', 'e', 'f'],['g','h','i']])
指定行索引,创建DataFrame 的对象
df3 = pd.DataFrame(demo2, columns=['no1', 'no2', 'no3'], index= ['one', 'two', 'three'])
通过标签索引 loc
element4 = df3.loc['one':'two']
print("element4 is :",element4)
element5 = df3.iloc[0:1]
2.2如果双括号呢,会切指定的这两列
element6 = df3.loc[['one', 'three']]
element7 = df3.iloc[[0,2]]
print('element7 is :\n',element7)
Original: https://blog.csdn.net/Dorothy_tc/article/details/123378780
Author: Dorothy
Title: Pandas的基本应用,如何创建和索引Series/DataFrame(有代码,可以运行,手打上去,可能有失误┭┮﹏┭┮)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/674369/
转载文章受原作者版权保护。转载请注明原作者出处!