

基于主成分分析与Fisher判别的DNA序列分类
【摘要】 :
特征提取:对于DNA序列,首先将其分为编码DNA特征与非编码DNA特征。对于非编码DNA,统计A,T,C,G各个碱基以及A+T在其中出现的频率,由此构建DNA序列所对应的5维向量空间。对于编码DNA,根据DNA转录与表达的中心法则,氨基酸与密码子的对应关系,统计21类氨基酸的出现频率,由此构建了DNA序列所对应的21维向量空间。最终,针对某一条DNA序列,根据其碱基和氨基酸的字频,拥有26个特征。
特征降维:由上得到了26维向量空间,再利用多元统计[1]的知识,利用”主成分分析”进行降维,提取特征。最终得到7个主成分,即得到了DNA序列对应的7维向量空间。
判别方法:利用Fisher判别方法,建立判别函数,求得判别函数值。并计算判别函数值与两类质心的绝对值距离,距离某一类近,则属于该类。
利用上述的判别规则对未知类别的DNA序列进行分类,对(21)~(40)的待判样本,最终的分类结果为:
A类 (23),(25),(29),(34),(35),(37);
B类 (21),(22),(24),(26),(27),(28),(30),(31),(32),(33),(36),(38),(39),(40)。
【关键词】 : 脱氧核糖核酸序列;向量空间;主成分分析;Fisher判别
1. 问题重述
题目给出了已分为两类的20组人工DNA序列,要求
1).利用已知信息,提取特征,
2).利用特征,构造分类方法
3).利用分类方法,对另外20个人工序列进行分类
2. 引言
2000年的数学建模[2]竞赛给出了DNA序列分析的题目,DNA全序列结构的研究是生物信息学的有关重要课题,而DNA序列分类是研究DNA全序列结构的基础。在《数据分析》的课程中,学习到了许多数据分类以及特征提取的方法,例如:主成分分析,因子分析,聚类分析,判别分析……因此,将该题作为本课程的论文研究题目。
生物学背景:
根据遗传信息传递的中心法则:遗传信息从DNA传递到mRNA,遵循碱基互补配对原则。mRNA的相邻三个碱基为一个密码子,64中密码子中的61种决定了20钟氨基酸,密码子序列决定了氨基酸排列合成蛋白质的序列,其他三种为合成的终止信号,由此可知,DNA的三个相邻碱基与一个氨基酸对应。
密码子特点(1)方向性:RNA中密码子的排列有一定方向
(2)无间隔性:两个相邻密码子之间没有间隔,即正确翻译密码 时,从某一特定起点开始,密码子一个接一个得翻译直到终止密码子
(3)非重叠性
根据以上特性,可将DNA序列片段进行有方向,连续的译码,将生物DNA转化为数学模型进行分析计算。
3. 模型假设
(1)假设给定的DNA序列均是从全序列中随机截取的一部分,无法确定序列的起始位。
(2)DNA,RNA在遗传信息及整个蛋白质合成过程中,遗传信息的传递严格遵循中心法则,也不考虑因其他因素而导致DNA,RNA的损坏和变异问题。
(3)较长的182个自然DNA序列与已知类别的20个样本序列具有共同的特征。
(4)为描述方便,根据碱基互补配对原则,将与RNA上密码子对应的DNA上的三个碱基称为DNA上的密码子。
4. 模型建立
4.1 指标的构建
由于所给的DNA序列是全序列中的片段,无法确定该段DNA是编码DNA,或是非编码DNA,又或是在该段区域上既有编码区域又有非编码区域。因此在假设的指标向量中,必须针对两种情况均有相对应的分量表示。
4.1.1 针对”非编码DNA”的情况
由题目[3]所提供的信息——”在不用于编码蛋白质的序列片段中,A和T的含量特别多些,于是以某些碱基特别丰富作为特征去研究DNA序列的结构也取得了一些结果”,可知针对非编码DNA的情况可以使用”A,T碱基丰富度”来衡量。为保证解释的全面性,对于一条DNA片段,我们以A,T,C,G各个碱基在其中出现的频率(某种碱基个数除以片段中的碱基总数),另外将A+T的频率和作为第五个因素引入。由此构成了5维向量空间。
4.1.2 针对 “编码DNA”的情况
由生物学[4]和生物化学知识[5],应用碱基互补配对原则,将RNA中64个密码子对应的20种氨基酸,按一一对应关系,对应到DNA的密码子,进行分组,编码(见表1).由表1可知:
(1)T,A,C,G共有(64种不同)不同组合,构成64种密码子。对于DNA序列片段,统计出不同密码子在其中出现频率(某种密码个数除以片段中的密码子总数),则对于每一个DNA片段就可以得到一个反应其每种密码子出现频率的64维向量。即对于每一个DNA片段,有一个64维向量与之一一对应。因此所有的DNA序列就构成了64维向量空间。
(2)64种密码子构成20种氨基酸和一个编号为21的终止码,从氨基酸种类数来分,DNA片段可以用一个21维向量来表示,向量种每一元素表示每种固定种类氨基酸的含量。此时,所有的DNA序列就构成了21维向量空间。
表1氨基酸与对应DNA密码子及其编号
氨基酸
对应的密码子及编号
苯丙氨酸(1)
亮氨酸(2)
丝氨酸(3)
酪氨酸(4)
半胱氨酸(5)
色氨酸(6)
脯氨酸(7)
组氨酸(8)
谷氨酰胺(9)
精氨酸(10)
异亮氨酸(11)
苏氨酸(12)
天冬酰胺(13)
赖氨酸(14)
缬氨酸(15)
丙氨酸(16)
天冬氨酸(17)
谷氨酸(18)
甘氨酸(19)
甲硫氨酸(20)
(终止信息)(21)
AAAAAG
AAT AAC GAA GAG GAT GAC
AGA AGG AGT AGC TCA TCG
ATA ATG
ACA ACG
ACC
GGA GGG GGT GGC
GAT GTG
GTT GTC
GCA GCG GCT GCC TCT TCC
TAA TAG TAT
TGA TGG TGT TGC
TTA TTG
TTT TTC
CAA CAG CAT CAC
CGA CGG CGT CGC
CTA CTG
CTT CTC
CCA CCG CCT CCC
TAC
ATT ATC ACT
4.2 DNA 序列对应向量的确定
由4.1.1与4.1.2,对于每一条DNA片段,都有26维的向量与之一一对应。因此所有的DNA序列构成了26维的向量空间。
对于氨基酸出现频率的求解,由于已知的DNA序列是由全序列种截取的一段,无法确定序列的起始密码子。因此对于一个给定的DNA序列,分别从开始的1,2,3号未知分别截取(从4号未知截取与1号重复,以此类推),产生3种不同的分法。
例如:aggcacggaaaa,可分为(agg)(cac) (gga)(aaa)或a(ggc)(acg)(gaa)aa或ag(gca)(cgg)(aaa)a。我们采用概率统计的思想,对DNA序列做出合理的解读:


4.3 特征的提取
上述指标构成了26维向量空间,即样本相对处在一个较高维度的空间中。特征的提取就是通过变换的方法用低维的空间来表示样本,使得样本中的大部分特性可由降维后的指标表示,使得类别内的差异尽量小。
我们用”主成分分析法”进行特征的提取,其基本原理是:

4.4 分类方法的选择
通过4.3主成分分析进行降维之后,我们可以得到两类DNA序列降维之后的特征指标。再使用Fisher判别分析,基于两类指标建立判别函数。Fisher判别分析的基本原理是:








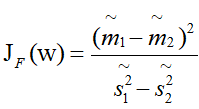


5.将训练集内所有样品进行投影








另一种是



根据决策规则就可以分类

4.5 整体模型的确定
1.根据已知样本,确定判别函数
1)构建指标
i 统计出每个DNA序列的A,T,C,G,A+T的字符频率,使用得到的5维向量反应非编码DNA部分的特征。
ii 统计三种截读方式下,21种DNA密码子(对应于氨基酸)的组合字符频率,并利用定理,选择最优的截读方式。并使用该种截读方式下得到的21维向量反应编码DNA的特征。
由此对于每一条DNA序列,都可以得到一一对应的26维向量。对于20个样本,最终构成了26维的向量空间。
2)特征降维

3)构建判别函数

2.利用判别函数,预测DNA序列类别


3)判别规则

5 模型求解
1.对20个样本数据进行指标提取后,所得结果见图5.1(DNA密码子以序号标识)

图5.1 已知样本的26维指标


图5.2 降维函数系数矩阵

图5.3 已知样本降维后的7维指标
3.利用Fisher判别进行分析后,得到的判别函数系数矩阵为:

两类质心处的值为:

4.将待判样本进行统计,获得26维向量后,将其代入4.5.1式得到判别函数值,再利用4.5.2式,得到最终的判别结果为:
A类 (23),(25),(29),(34),(35),(37);
B类 (21),(22),(24),(26),(27),(28),(30),(31),(32),(33),(36),(38),(39),(40)。
6 模型检验
在进行Fisher判别时,表6.1给出了典型判别分析的有效性检验。Wilks’Lambda统计量的值越小,表明相应的判别函数越显著。由表中可以看出判别函数的显著性检验的Sig值为0.000小于0.05,故该判别函数显著,能够用来判别样品的归属。
表6.1

Github源码地址:https://github.com/Jiangtao-Hao/DNA_seq
参考文献
[1]方开泰.实用多元统计分析[ M].上海:华东师范大学出版社 ,1989.262—297.
[2] 姜启源.2000网易杯全 国大学生数 学建模竞赛[J3.数学的实践与认识,2001,31(1):24.
[3]2000网易杯全国大学生数学建模竞赛题目,A题 DNA序列分类,2000年.
[4] Atiya h M. Mathematics:Frontiers and perspectives[M3].Providence:AMS,2000.
[5]卫生部,生物化学[M].北京:化学工业出版社,2000.120-165.
[6]周玉元,周铁军.DNA序列分类的Fisher判别法[J].湖南农业大学学报(自然科学版),2003(05):437-440.
Original: https://blog.csdn.net/qq_41168765/article/details/122265814
Author: 孤独的马铃薯
Title: 基于主成分分析与Fisher判别的DNA序列分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/666510/
转载文章受原作者版权保护。转载请注明原作者出处!