

本章内容写pandas库里的表格dataframe的相关使用。
内容包括: 表格的建立(传入参数和设置index), 添加行/列(append),表格的 筛选, 删除行/列(drop), 表格排序, 数据透视(df.pivot), 表格划分( groupby)等。
1. 建立表格df=pd.DataFrame(data,columns,index)
一般创建形式如下:
df=pd.DataFrame(data,columns=columns,index=index)
三个参数, 参数1data为 建立表格所需数据,二维数组; 参数2column为列名,一维数组,当创建形式维字典创建时,不需要列名参数,同时参数1是字典; 参数3是索引,一位数组,可有可无,默认是0,1,2……
(1)建立一个空的框架:
df=pd.DataFrame()
输出:
Empty DataFrame
Columns: []
Index: []
此时没有传入参数,建立的是一个空表格。
(2)传入一个 二维列表:
data=[['zhang',10],['li',20],['wang',15]]
df=pd.DataFrame(data,columns=['Name','Age'])
同时在后面可以 设置数据类型dtype=float,可以将表格中的数字数据自动转换成浮点数。
注意,此处一定是二维列表,或者字典。
(3) 字典创建:
data= {'Name':['zhang','li','wang'],'Age':[10,20,30]}
df=pd.DataFrame(data)
字典创建列名自动带入了字典键,键值为表格元素。
(4)关于声明表头
可以在 创建表格时声明表头,当特定表头的元素不存在,填充为NaN。
data=[{'a':1,'b':2},{'a':3,'b':4,'c':5}]
df1=pd.DataFrame(data,columns=['a','b'])
df2=pd.DataFrame(data,columns=['a','d'])
输出:
a b
0 1 2
1 3 4
a d
0 1 NaN
1 3 NaN
2. 添加元素df[‘column_name’],df.loc,df.iloc,df.append
分为添加行和添加列。
关于添加列,只需要 df[‘column_name’]=[]即可,默认添加到最后一列;当想添加到指定的位置时,采用 df.insert()方法;
关于添加行,有三种方法。首先 df.iloc[]=[],参数为数字,会被覆盖;其次 df.loc[],参数为索引名Index,根据索引名添加;最后 df.append(),将两个表格合成一个。
添加列:
(1)添加到最后一列
df1['score']=[80,98,67,90]
(2)具体插入某一列到位置: df.insert(iloc,column,value)
三个参数,插入位置,列名,插入值列表:
df1.insert(2,'birth',['1995-07-01','1998-09-04','1993-11-03','1994-04-17'])
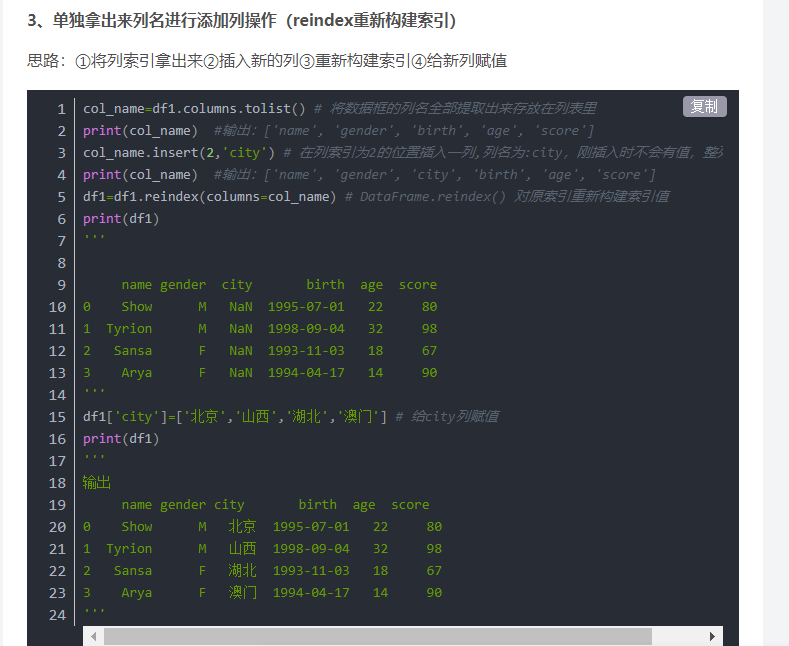

(3)添加一行: df.iloc[index]
index是整数,表示添加到第几行, 原数据会被覆盖,且不能超过len(dataframe);
data=[{'a':1,'b':2},{'a':3,'b':4}]
df1=pd.DataFrame(data,columns=['a','b'],index=['first','second'])
df1.iloc[0]=[6,7]
输出:
a b
first 6 7
second 3 4
(4) df.loc[]方法
根据索引添加,此时添加的数值使用给定的索引。
当添加的索引值 已经存在时, 更改; 不存在时, 添加到最后一行。
一般这种方法,表格的索引都是自定义的。
data=[{'a':1,'b':2},{'a':3,'b':4}]
df1=pd.DataFrame(data,columns=['a','b'],index=['first','second'])
df1.loc['third']=[9,10]
输出:
a b
first 1 2
second 3 4
third 9 10
data=[{'a':1,'b':2},{'a':3,'b':4}]
df1=pd.DataFrame(data,columns=['a','b'])
df1.loc[3]=[6,7]
输出:
a b
0 1 2
1 3 4
3 6 7
(5) df.append:添加到最后一行
这是需要创建两个表格,然后拼接成一个。需要注意参数ignore_index,默认保留原索引,改为True时表示重新排序索引。
一般插入一个新的一项时,采用简单方法构建一个新的表格,然后append到目标表格去。
data=[[1,2],[3,4]]
df1=pd.DataFrame(data,columns=['a','b'])
data=[[5,6],[7,8]]
df2=pd.DataFrame(data,columns=['a','b'])
df=df1.append(df2,ignore_index=True)
输出:
a b
0 1 2
1 3 4
2 5 6
3 7 8
3. 不同dataframe的拼接方法df1.merge(df2,on,how)
df=df1.merge(df2, on=’ 合并的列名 ‘, how=’ outer’)
how表示内连接(inner)或者外连接(outer):内连接表示保留共有元素,外连接表示保留所有元素,没有值的进行NaN填充;
同时,合并列名也可以选择多个。
df1=pd.DataFrame(data1,columns=['Name','Sex','Age'])
df2=pd.DataFrame(data2,columns=['Name','Weights','Heights'])
df_merge=df1.merge(df2,on='Name',how='outer')
df_merge2=df1.merge(df2,on='Name',how='inner')
输入:
3
zhao male 15
qian female 1
sun male 75
2
zhao 100 112
qian 147 256
输出:
Name Sex Age Weights Heights
0 zhao male 15 100.0 112.0
1 qian female 1 147.0 256.0
2 sun male 75 NaN NaN
Name Sex Age Weights Heights
0 zhao male 15 100 112
1 qian female 1 147 256
总结博客见:pandas dataframe的合并(append, merge, concat) – GUXH – 博客园 (cnblogs.com)
4. 更改dataframe中的值df.loc和df.iloc[index,column]
三种方法, df.iloc[],根据索引位置来查找,参数都为整数,表示几行几列,等价于 df.iat;
df.loc[],参数为index名和column名,等价于 df.at;

5. dataframe按照某列排序df.sort_values(by,inplace,ascending)
格式为:df.sort_values(by=’A’,inplace=True, ascending=True),参数1表示按哪个列进行排序,会在原dataframe上进行修改
df.sort_values(by='A',inplace=True, ascending=True)
输出:
A B
1 0 9
2 4 8
1 6 3
0 7 5
0 8 5
6. 取指定范围内的值df.loc[行1:行末,列1:列末],df.iloc
有loc方法和iloc方法。loc方法通过index和column来取,不能通过数字,iloc方法通过数字索引来去,不能使用索引名。
同时需要注意,iloc方法按照数字来取时,不包含最后一个元素。
print(df_merge1.loc[1:2,'Sex':'Heights'])
print(df_merge1.iloc[0:2,2:4])
输出:
Name Sex Age Weights Heights
0 zhao male 15 100.0 112.0
1 qian female 1 147.0 256.0
2 sun male 75 NaN NaN
Sex Age Weights Heights
1 female 1 147.0 256.0
2 male 75 NaN NaN
Age Weights
0 15 100.0
1 1 147.0
8.删除指定行
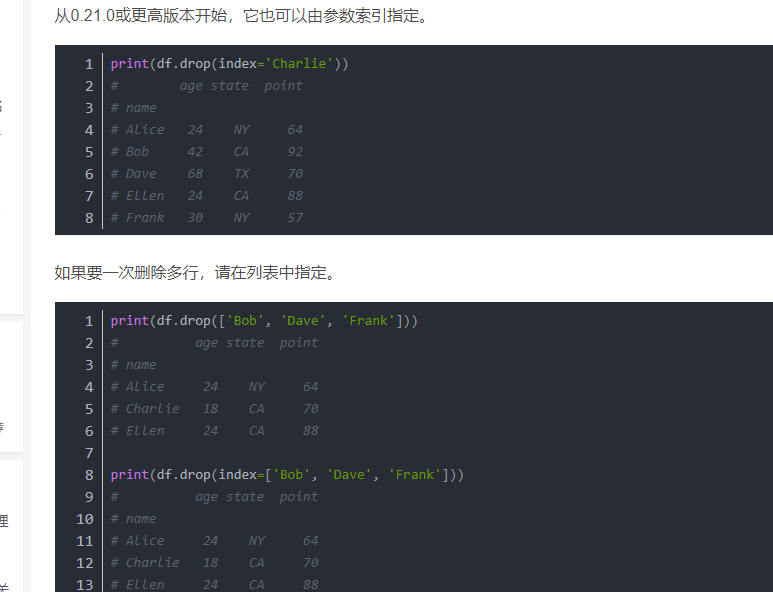
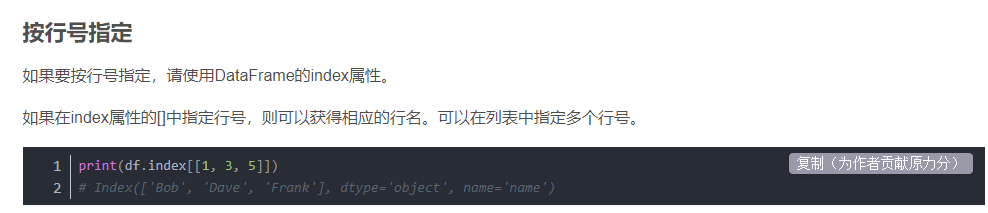
(133条消息) 12_Pandas.DataFrame删除指定行和列(drop)_饺子大人的博客-CSDN博客_dataframe删除指定行
- 使用groupby对表格进行划分
(1)
for i in df.groupby('Group'):
print(i)
df1=df['Sales'].groupby(df['Group']).sum()
print(df1)
df1=df['Sales'].groupby(df['Mon']).sum()
print(df1)
- 数据透视表格
df.pivot(index='Mon',columns='Part',values='Num')
df=pd.DataFrame(data,columns=['Mon','Part','Num','Price'])
print(df)
print(df.pivot(index='Mon',columns='Part',values='Num'))
print(df.pivot(index='Mon',columns='Part',values='Price'))
Mon Part Num Price
0 1 A 1 2
1 1 B 3 4
2 1 C 5 6
3 1 D 7 8
4 1 E 9 10
5 2 A 11 12
6 2 B 13 14
7 2 C 15 16
8 2 D 17 18
9 2 E 19 20
Part A B C D E
Mon
1 1 3 5 7 9
2 11 13 15 17 19
Part A B C D E
Mon
1 2 4 6 8 10
2 12 14 16 18 20
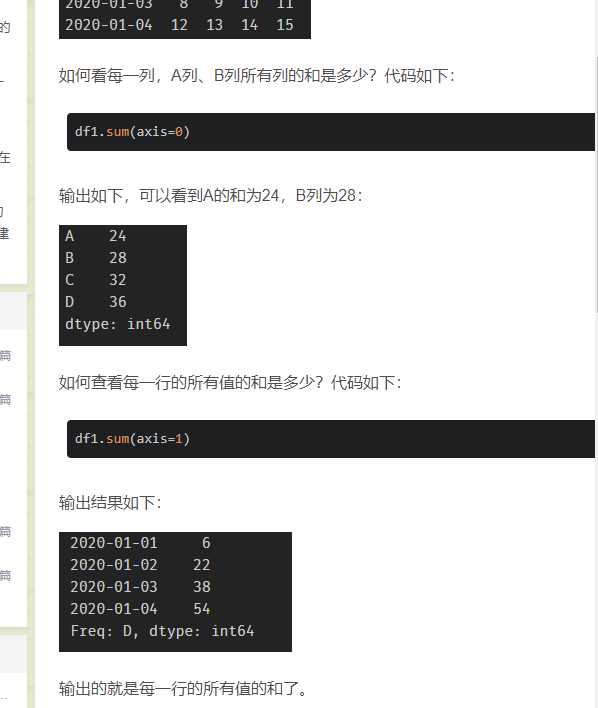
- 添加一行的平均值
df['Mean']=df.apply(lambda x:x.mean(),axis=1)
并添加一列进去
df.mean

- 筛选
如果想要筛选出 B列大于零 的 行:
df1 = df[df[‘B’]>0]
如果要根据B、C两列来筛选数据,但最终只显示A、D两列的数据:
df4 = df[[‘A’, ‘D’]][(df[‘B’]>0)&(df[‘C’]
Original: https://blog.csdn.net/zhuge2017302307/article/details/121294525
Author: 昔我往矣wood
Title: 【python-NOJ-季总结】—【第八季:Pandas库】—表格Dataframe的建立和使用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/674325/
转载文章受原作者版权保护。转载请注明原作者出处!