

现在使用Python处理表格类数据(excel/csv)已经成为工作不可或缺的技能,尤其大数据量的分析筛选转换,Python更可以提供无与伦比的优势,使用Python处理数据,那Pandas就肯定绕不开,这篇就是Pandas的简单应用。
Pandas 数据分析包
使用只需引入即可
import pandas as pd
处理表格
- 获取表格数据
我们日常大部分情况都会使用excel,所以这次使用Pandas来处理excel作为例子
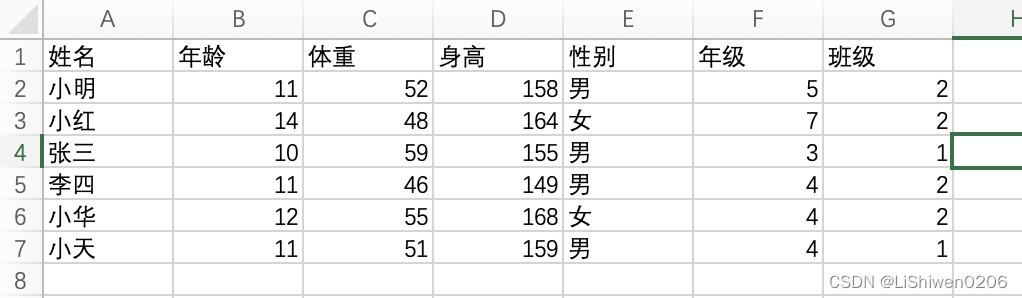

path = '/Users/lishiwen/Downloads/'
fileName = 'Person'
excel = pd.read_excel(path + fileName + '.xlsx')
df = pd.DataFrame(excel)
df
结果:
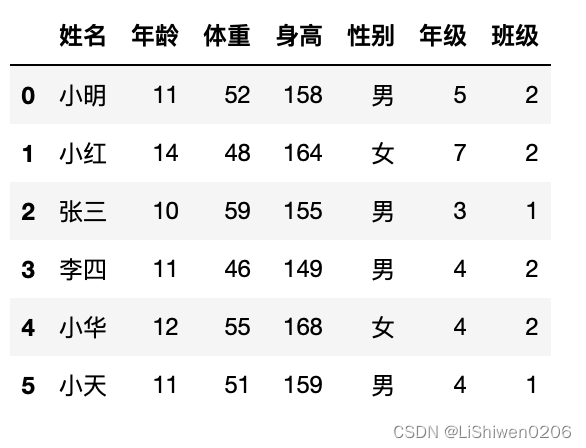
2. 一些查看表格的基本信息的方法:

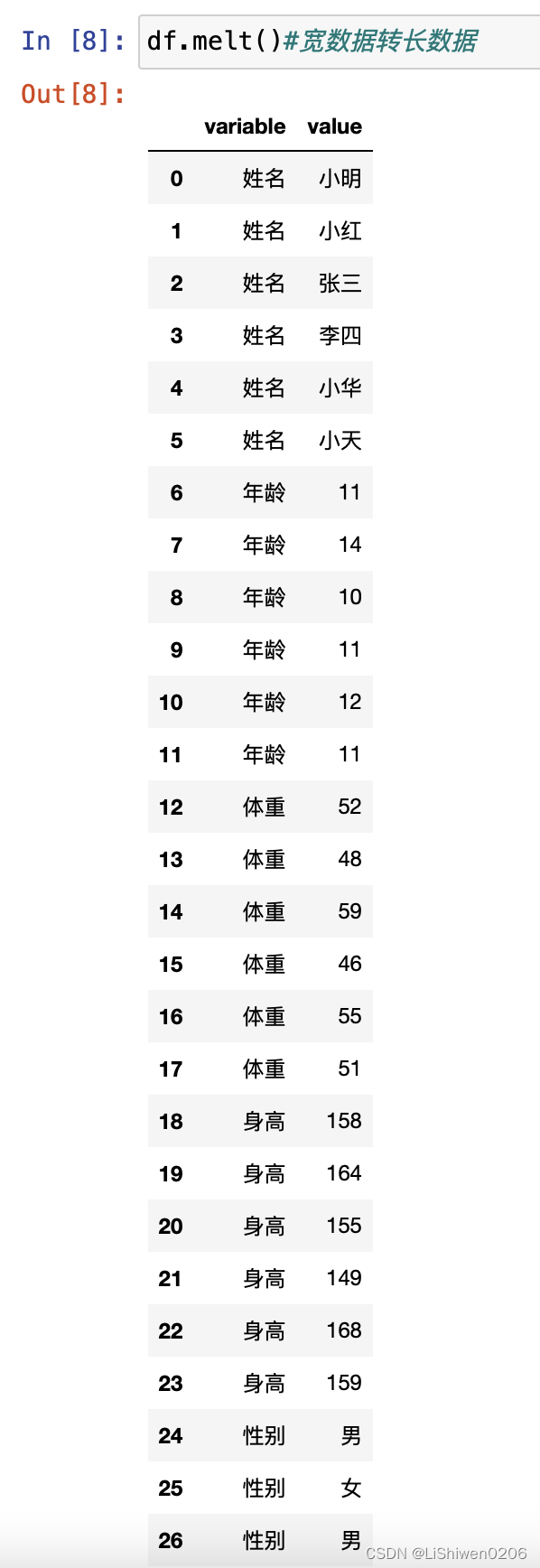
- dataframe有宽表转长表的方法,可以更好的展现数据维度与组合
df.melt()
结果:
df.melt(id_vars=["姓名","年龄","体重","性别","身高"])
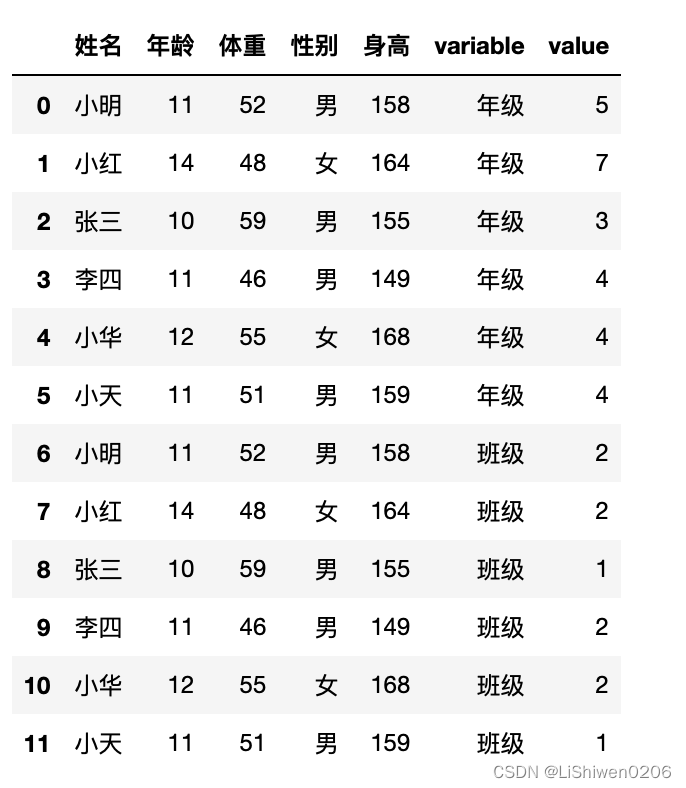
上面是一些pandas的dataframe的一些基础属性,日常数据处理需要一些对数据的处理,下面开始对表格进行基础操作
- 筛选数据
df[ df.性别 == "男" ]
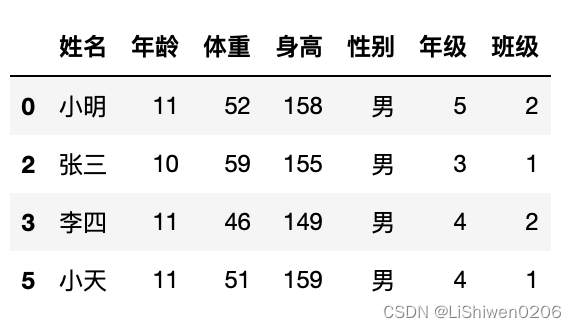
上面的数据筛选出我们需要的男性数据,但是可以看到索引还是之前的索引,可能不是我们希望展示的,所以需要重制索引
df2 = df[ df.性别 == "男" ]
df2.index = range(len(df2))
df2
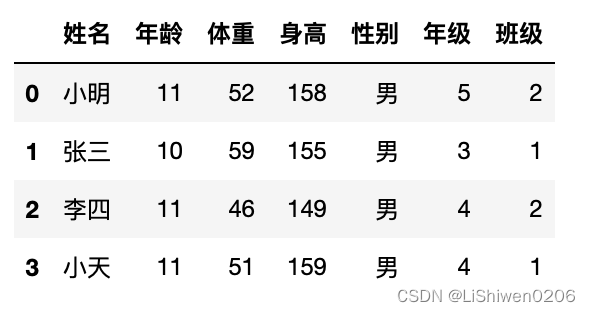
- 根据条件添加列数据
在处理表格时,会有根据某列的数据,新增一列新的数据,这时候可能就会需要用到判断或计算式
df['小,初,高'] = df.apply(lambda x: '小学' if x.年级 < 7 else '初中' if 6 <x.年级 < 10 else '高中', axis=1)
df
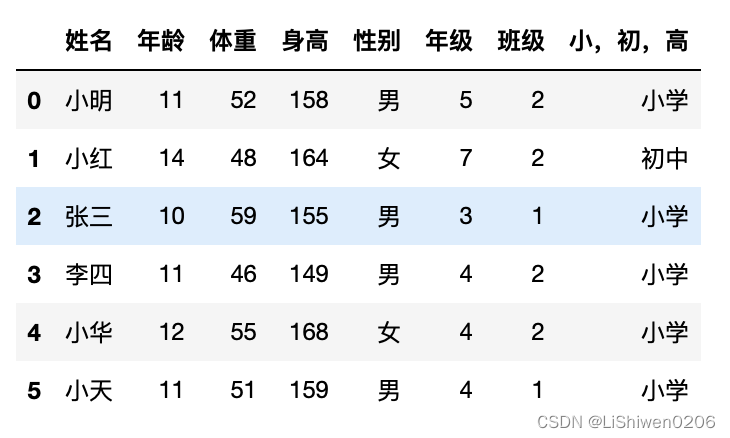
- 根据某列值修改其他列
df['学费']=0
df.loc[df['小,初,高'] == '小学', '学费'] = 100
df.loc[df['小,初,高'] == '初中', '学费'] = 200
df.loc[df['小,初,高'] == '高中', '学费'] = 300
df
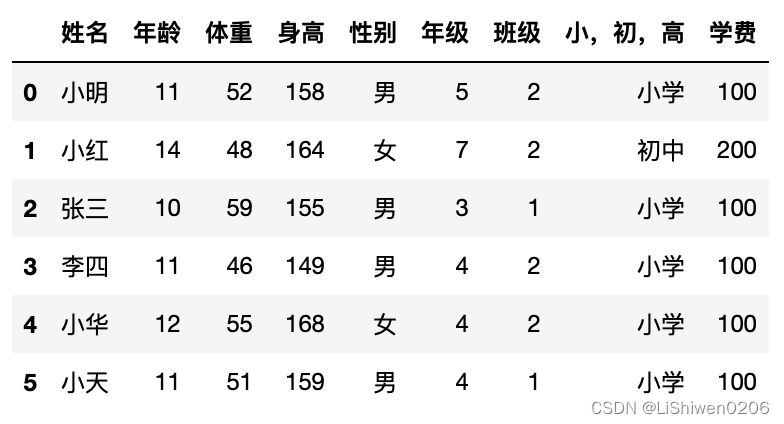
- 分组查看
表格处理中肯定会有希望通过某一维度聚合查看其他类型数据,这就用到了分组
df.groupby(['年级','班级','姓名']).mean()
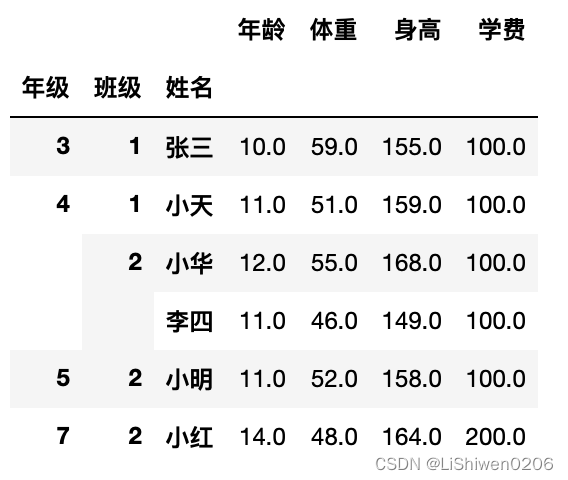
- 绘图
pandas处理数据的能力是毋庸置疑的,但是他更加强大是因为它还可以绘图,可以根据你的数据绘制出你想要的图表,可以更直观的分析数据
可以直接使用df.plot()进行绘图,但是表格数据内有中文,绘图时会做警告,并且展示不了中文,所以需要多一个引用import matplotlib.pyplot as plt因为pandas的plot调用的matplotlib绘图,通过plt设置文字编码即可。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus']=False
df3 = df.groupby(['年级','班级','姓名']).mean()
df3.rename(columns={'年龄':'age'},inplace=True)
df3.plot()
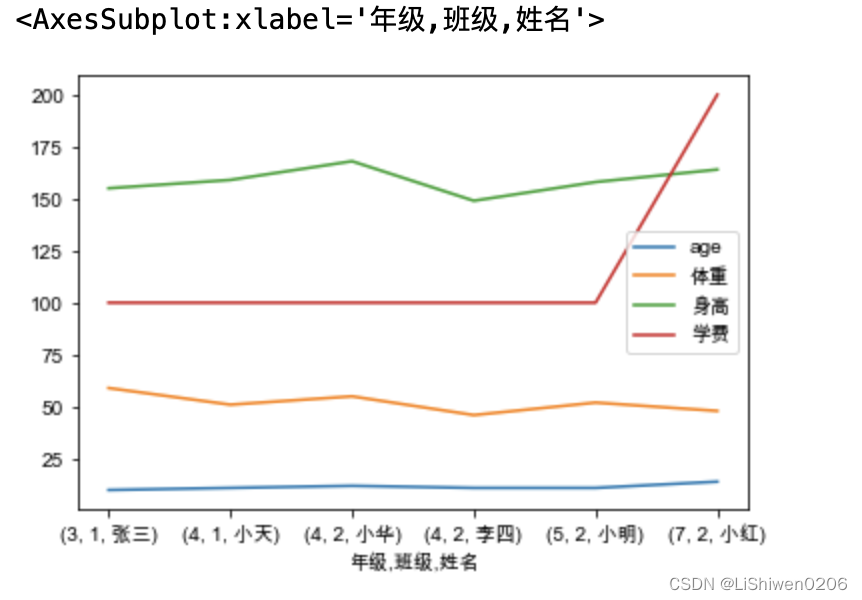
上面就是使用pandas处理表格数据的简单应用场景,pandas处理表格只有你想不到,没有它做不到的。更多使用参见它的 使用手册
Original: https://blog.csdn.net/VincentLee7/article/details/125954026
Author: LiShiwen0206
Title: Pandas处理表格基础
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/674087/
转载文章受原作者版权保护。转载请注明原作者出处!