

目录
一、决策树定义:
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。
结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
⚪:内部结点
正方形:叶结点


二、决策树特征选择
2.1 特征选择问题
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率。如果用一个特征去分类,得到的结果与随机的分类没有很大差别,那么这次分类是无意义的。因此,我们要选取有意义的特征进行分类。
举个例子吧~

如上述表格所示,决定买房子要不要贷款的因素有年龄、有无工作、有无房子、信贷情况四个因素。那么如何选取合适的特征因素呢?
特征选择就是决定用哪个特征来划分特征空间。
直观上来讲,如果一个特征具有更好的分类能力,或者说,按照各以特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就应该选择这一特征。
信息增益(information gain)就能够很好的表示这一直观准则。

2.2 信息增益
2.2.1 熵
在统计学中,熵是表示随机变量不确定性的度量。
设X是一个取有限个值的离散随机变量,其概率分布为

则随机变量X的熵定义为:

其中如果pi = 0,则0log0 = 0.
单位为bit或者nat。
上只依赖于X的分布,而与X的取值无关,所以也可将X的熵记作H(p)。
熵越大,随机变量的不确定性越大,从定义可以验证:




信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
2.2.2 信息增益

选择方法:

计算方法:
输入:训练数据集D和特征值A:
输出:特征A队训练数据集D的信息增益g(D,A),
step1:计算数据集D的经验熵H(D):

step2:计算特征A对数据集D的经验条件熵H(D|A):

step3:计算信息增益:
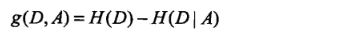
举个栗子吧~:
用上面的表,计算每个特征的信息增益!!!!


所以A3的信息增益值最大,选择A3做最优特征。
三、决策树的生成
3.1 ID3算法
ID3算法的核心是在决策树上各个结点上应用信息增益准则选择特征,递归地构建决策树。


3.1.1理论推导
对上表用ID3算法建立决策树:


3.1.2代码实现
https://blog.csdn.net/colourful_sky/article/details/82056125
3.2 C4.5 算法
C4.5算法与ID3类似,C4.5算法对ID3算法进行了改进,C4.5在生产的过程中,用信息增益比来选择特征。
3.2.1理论推导

https://www.cnblogs.com/wsine/p/5180315.html
四、决策树的剪枝
4.1 原理
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的结果容易出现过拟合现象。因为这样生成的决策树过于复杂,所以我们需要对决策树进行简化——剪枝。
剪枝:在决策树学习中将已生成的树进行简化的过程。
本次介绍 损失函数最小原则进行剪枝,即用 正则化的极大似然估计进行模型选择。
公式这里参考 李航老师的书:


4.2 算法思路:



五、CART算法
分类与回归树模型(CART, classification and regression tree)是应用广泛的决策树学习方法。
CART由特征选择、树的生成及剪枝组成,既可以用于 回归也可以用于 分类。
5.1 CART生成
step1:决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大。
step2:决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
5.1.1 回归树的生成
回归树用平方误差最小化准则,选择特征,生成二叉树。

5.1.2 分类树的生成
分类树用基尼指数最小化准则,选择特征,生成二叉树。

比较:

5.1.3 CART生成算法
原理:


例子:
还是用上面的的表格吧
step1:计算各个特征的基尼指数,选择最有特征以及其最优切分点。

step2:选择基尼指数最小的特征及其对应的切分点

5.2 CART剪枝

六、代码
sklearn中决策树都在’tree’这个模块中,这个模块总共包含五类:
tree.DecisionTreeClassifier 分类树
tree.DecisionTreeRegressor 回归树
tree.export_graphviz 画图专用
tree.ExtraTreeClassifier 高随机版本的分类树
tree.ExtraTreeRegressor 高随机版本的回归树
这里用分类树举例子
6.1 代码
#数据准备
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
#分离数据
breast_cancer
x=breast_cancer.data
y=breast_cancer.target
#训练数据
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=33,test_size=0.3)
#数据标准化
from sklearn.preprocessing import StandardScaler
breast_cancer_ss = StandardScaler()
x_train = breast_cancer_ss.fit_transform(x_train)
x_test = breast_cancer_ss.transform(x_test)
#分类树
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(x_train,y_train)
dtc_y_predict = dtc.predict(x_test)
from sklearn.metrics import classification_report
k=0
j=0
for i in y_test:
if i!=dtc_y_predict[j]:
k=k+1
j=j+1
print(k)
print('预测结果:\n:',dtc_y_predict)
print('真是结果:\n:',y_test)
print('Accuracy:',dtc.score(x_test,y_test))
print(classification_report(y_test,dtc_y_predict,target_names=['benign','malignant']))
6.2 结果

Original: https://blog.csdn.net/maggieyiyi/article/details/123774872
Author: maggieyiyi
Title: 机器学习——决策树
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/673237/
转载文章受原作者版权保护。转载请注明原作者出处!