

Point cloud 是一种非常适合于3D场景理解的数据,原因是:
1、点云是非常接近原始传感器的数据集,激光雷达扫描之后的直接就是点云,原始的数据可以做端到端的深度学习,挖掘原始数据中的模式。
2、点云在表达形式上是比较简单的。相比较来说:Mesh需要选择面片类型和如何连接;网格需要选择多大的网格,分辨率;图像需要选择拍摄的角度,表达是不全面的。
之前的大部分工作都是集中在手工设计点云数据的,这些特征都是针对特定任务,有不同的假设,新的任务很难优化特征,最近才有一些方法研究直接在点云上进行特征学习,希望用深度学习特征学习去解决数据的问题。
点云数据是一种不规则的数据,输入网络需要规则化:
输入网络还需要解决这些问题:
- 无序性:maxpooling/sumpooling
- 旋转不变:transform学习角度
- 近密远疏:voxel、random-sample同样数目的点
- 非结构化如何CNN:voxel-base、projection-base、point-base
三种方法思路:
Projection-base:2D图像的处理思路,点云投影为2D图像,比如转为BEV,用2D检测的方法出3D框,输入点云投影图(多结合2D图像),网络使用传统的2D-CNN,典型为MV3D。数据压缩成二维本身会丢掉空间关系,有效地将点云转为图像是检测结果好坏的关键,但转化为图像操作,理解简单,工具现成。
Voxel-base:voxel对应pixel,体素对应像素,在空间内画固定大小的网格,形成体素,用3d卷积来做。体素是从CNN直接扩展而来的,非常暴力,理解简单。体素化之后,有很多体素中没有雷达点,通常的做法是将其特征置0,0参与卷积之后的结果还是0,相当于没有贡献,但这种体素稀疏的性质,使得大量的卷积是无用计算,另一个问题是,体素是三维的,卷积模板也是三维的,那么计算起来就比二维的慢,而且卷积核移动的方向也是三维的,随着空间的大小的增大,体素的数量是以立方的数量增长,使得体素这种表达方式,不仅使得计算缓慢,而且大量计算是无用的,当然,稀疏卷积spare convolution的研究可以部分解决这个问题。另外pointpillars将体素的z轴维度去掉,使用2D卷积解决了速度问题。点云体素化后提取手工的特征,再接FC,这么做有很大的局限性。
Point-base:直接对点云操作,由于点云的无序性,使得对点云直接操作的研究要从头进行,目前主流的就是PointNet系列和Graph convolution系列。
MVNet使用点云和图像作为输入。
点云的处理格式分为两种:第一种是构建俯视图(BV),构建方式是将点云栅格化,形成三维栅格,每一个栅格是该栅格内的雷达点最高的高度,每一层栅格作为一个channel,然后再加上反射率(intensity)和密度(density)的信息;第二种是构建前视图(FV),将雷达点云投影到柱坐标系内,也有文章叫做range view,然后栅格化,形成柱坐标系内的二维栅格,构建高度、反射率和密度的channel。
使用俯视图按照RPN的方式回归二维proposal,具有(x, y, w, l)信息,角度只分成0和90度两种,z和h的信息在这一步被设置为常量。然后将三维的proposal进行多个角度的ROI pooling,fusion过程可使用concatenation或summation。最后加上经典的分类头和回归头。
我们能否直接用一种在点云上学习的方法:统一的框架,end2end,multi-task(检测、分割)
基础分类和分割,无检测功能
设计思路:
- 输入顺序置换不变性
如何让点云输入顺序的不变呢?
点云是数据的表达点的集合,对点的顺序不敏感,N个点,D维特征,最简单的D=3(xyz),还可以有颜色、法向。
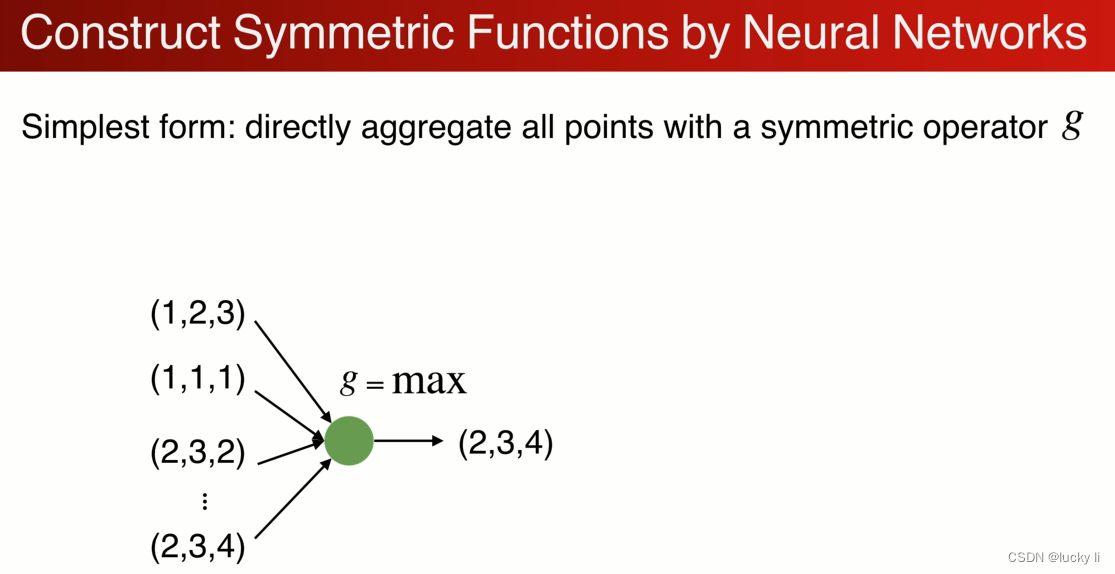
点集是无序的,可以做变化,背后的代表的是同一套点集,网络需要做到置换的不变性。解决方案是对称函数,具有置换不变性,神经网络本质也是一个函数。如何用神经网络构建对称函数,最简单的例子是取max:
虽然是置换不变的,但是这种方式只计算了最远点的边界,损失了很多有意义的几何信息,如何解决呢?
可以先把每个点映射到高维空间,在高维空间中做对称性的操作,高维空间可以是一个冗余的,在max操作中通过冗余可以避免信息的丢失,可以保留足够的点云信息。
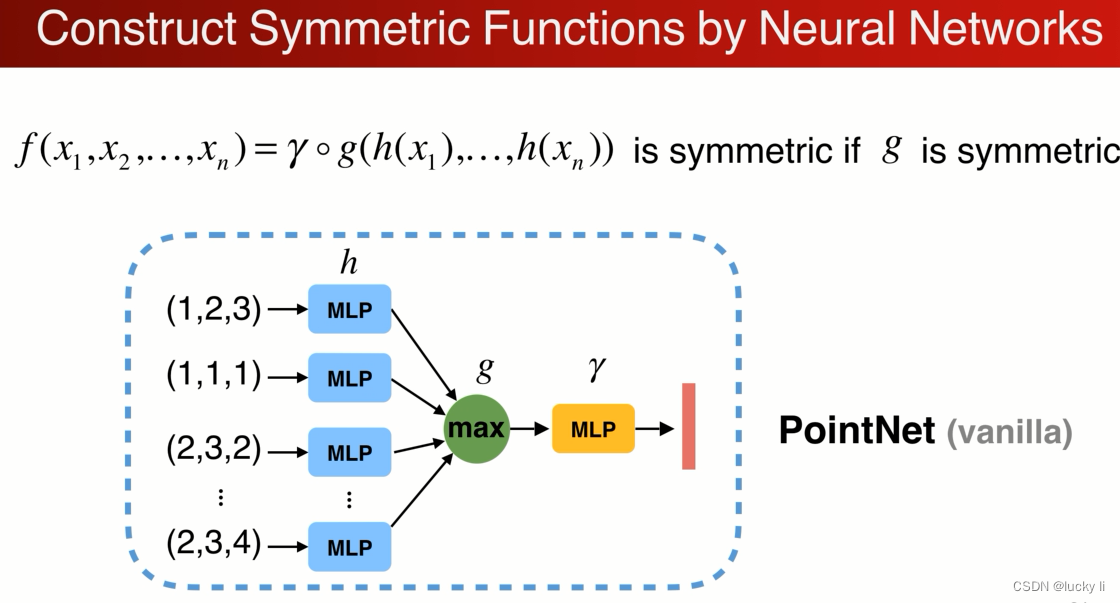
这就是函数hgγ(原始的point-net结构)的组合。
每个点都做h低位到高位的映射(可以用mlp数据升维),G是对称的(可以用maxpooling作对称还可以降采样),那么整个结构就都是对称的,再通过一个网络γ来进一步消化信息得到点云的特征得到最终结果。
mlp就是多个fc堆叠。
- 角度置换不变性(后续的pointnet版本证明没效果,废弃了)
如何来应对输入点云的几何(视角)变换,比如一辆车在不同的角度,点云的xyz都是不同的,但代表的都是车,我们希望网络也能应对视角的变换。
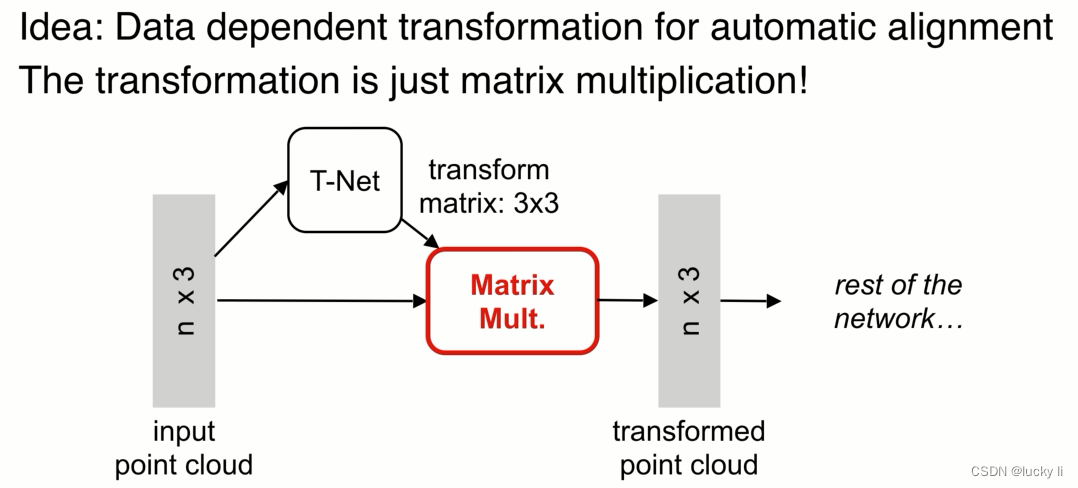
可以增加了一个基于数据本身的变换函数模块 T-net ,网络处理变换之后的点,通过优化变换网络和后面的网络使得变换函数对齐输入,如果对齐了,不同视角的问题就可以简化。
实际中点云的变化很简单,做矩阵乘法就可以。比如对于一个33的矩阵仅仅是一个正交变换,计算容易实现简单。
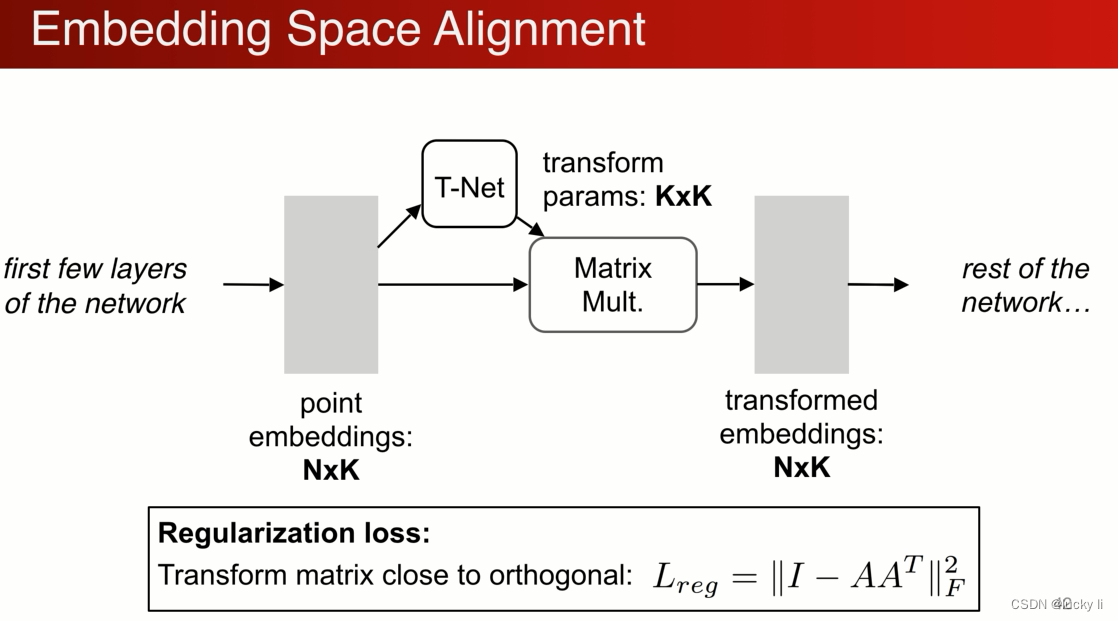
我们可以推广这个操作,不仅仅在输入作此变换,还可以在中间做 N个点 K维特征,用另外网络生成kk 来做特征空间的变化,生成另一组特征。高维优化难度高,需要加正则化,比如希望矩阵更加接近正交矩阵。
后续的pointnet版本证明T-net没效果,废弃了,我认为之所没效果是因为对于大空间的分割检测任务,整体变换角度对学习各个目标小部件作用不大,可能只对小型分类点云有用。
网络模型:
- 输入原始点云,一个n*3的矩阵,n代表点云数量,3对应xyz坐标;
- 先做一个输入的矩阵变换(Tnet),n3 x 33,还是n*3的矩阵;
- 然后通过mlp把每个点投射到64高维空间;
- 在做一个高维空间的变换(Tnet),形成一个更加归一化的64维矩阵;
- 继续做MLP将64维映射到1024维;
- 在1024中可以做对称性的操作,就是maxpooling,得到globle fearue(1*1024);
- head:
- 对分类任务,将全局特征通过mlp(多个fc层)来预测最后的分类分数(11024->1512->1256->1k),k代表样本集中点云类别的个数,输入的点云只有一个类别,这不是检测任务,有多个目标;
- 对分割任务,将全局特征复制n份,和之前学习到的局部特征即64维那层进行concat,n(1024+64),再通过mlp得到每个数据点的分类结果(n1088->n512->n256->n128->nm),m是分割类别数目。将局部单个点的特征和全局的坐标结合起来,实现分割的功能。
优点:
对比2D图片和3D栅格,pointnet是个非常轻量级的网络,适用于移动设备;
同时对数据的丢失也是非常的鲁棒,对比于voxelnet 的对比,在model net 40 的分类问题上,在丢失50%的点的情况下,pointnet仅仅受到2%的影响,与之想想比Voxnet3D精度相差了20%。
下图第一行是Original的,我们想知道哪些点对全局特征做出了贡献,maxpooling ,有些点embedded的特征非常小,在经过maxpooling之后对全局特征没有任何的贡献,哪些点是剩下来的Critial(Maxpooling 之后存活下来的大特征点),只要轮廓和骨骼得到保存,就能把形状分类正确。
缺点:
point-net一开始对每个点做MLP低维到高维的映射,把所有点映射到高维的特征通过Max pooling 结合到一起。本质上来说,要么对一个点做操作,要么对所有点做操作,实际上没有局部的概念(loal context) ,比较难对精细的特征做学习,在分割和检测上有局限性,适合小点云的分类 。
没有local context 在平移不变性上也有局限性,对点云数据做平移,所有的数据都不一样了,导致所有的特征,全局特征都不一样了,分类也不一样。对于单个的物体还好,可以将其平移到坐标系的中心,把他的大小归一化到一个球中,在一个场景中有多个物体不好办,对哪个物体做归一化呢。

为了解决这些问题诞生了PointNet++。
设计思路:
- 平移不变性多级的区域特征学习
pointnet++ 核心的想法在局部区域重复性的迭代使用pointnet ,在小区域使用pointnet 生成新的点,新的点定义新的小区域 ,多级的特征学习,因为是在区域中,我们可以用局部坐标系,可以实现平移的不变性,同时在小区域中还是使用pointnet,对点的顺序是无关的,保证置换不变性。
世界坐标系,先找到一个局部的区域,因为不想受整体平移的影响:
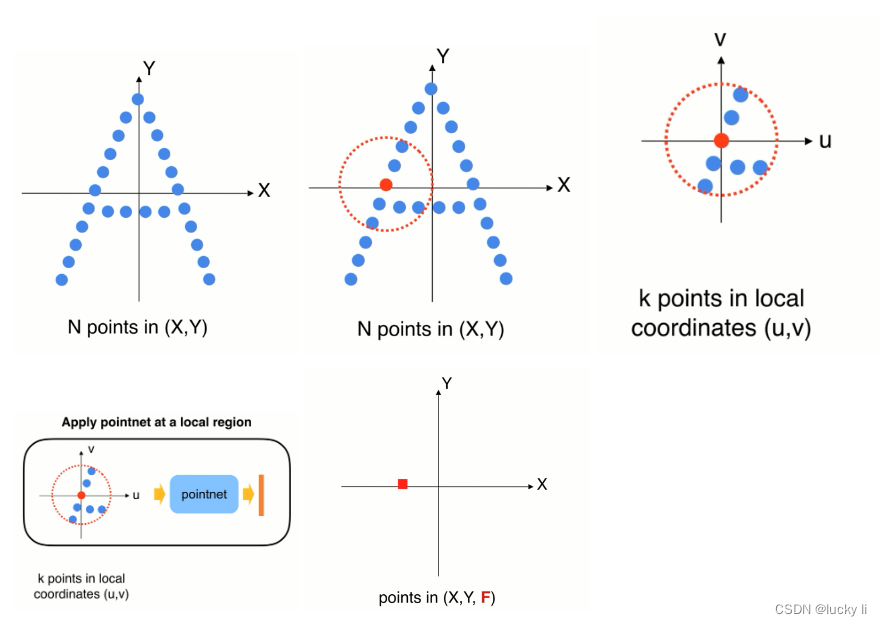
1、可以先把局部的点转换到一个局部坐标系中
2、在局部中使用pointnet 来提取特征
3、提取完特征以后会得到一个新的点F,F在整个点云中的位置
4、向量特征F(高纬的特征空间)代表小区域的几何形状,如果重复这个操作就会得到一组新的点,在数量上少于原先的点,但是新的每个点代表了它周围一个区域的几何特点。
网络模型:
- *单尺度网络
set abstraction:Sampling(FPS)、Grouping、PointNet构成了PointNet++的一组基础处理模块。
我们可以重复set abstraction的过程,实现一个多级(code是三级,图展示两级)的网络,使得点的数量越来越少,但是每个点代表的区域以及感受野越来越大,这个和cnn的概念很类似。
pointnet里已经废弃Tnet了,因为PN++ 已经学了局部特征,局部特征其实对旋转不太敏感,已经可以取得比较好效果。
单尺度 point++ 分类模型 pointnet2_cls_ssg.py
# Set abstraction layers
# 三组set abstraction,
# L0 为原始点云 (B,n,3) batch、点数、特征通道数、
l1_xyz, l1_points, l1_indices = pointnet_sa_module(l0_xyz, l0_points, npoint=512, radius=0.2, nsample=32, mlp=[64,64,128], mlp2=None, group_all=False, is_training=is_training, bn_decay=bn_decay, scope='layer1', use_nchw=True)
# L1 (B,512,128)
l2_xyz, l2_points, l2_indices = pointnet_sa_module(l1_xyz, l1_points, npoint=128, radius=0.4, nsample=64, mlp=[128,128,256], mlp2=None, group_all=False, is_training=is_training, bn_decay=bn_decay, scope='layer2')
# L2 (B,128,256)
l3_xyz, l3_points, l3_indices = pointnet_sa_module(l2_xyz, l2_points, npoint=None, radius=None, nsample=None, mlp=[256,512,1024], mlp2=None, group_all=True, is_training=is_training, bn_decay=bn_decay, scope='layer3')
# Fully connected layers
net = tf.reshape(l3_points, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training, scope='fc1', bn_decay=bn_decay)
net = tf_util.dropout(net, keep_prob=0.5, is_training=is_training, scope='dp1')
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training, scope='fc2', bn_decay=bn_decay)
net = tf_util.dropout(net, keep_prob=0.5, is_training=is_training, scope='dp2')
# 分40类
net = tf_util.fully_connected(net, 40, activation_fn=None, scope='fc3')
- Sampling :点云的数据量重多,如果对每一个点都提取局部特征,计算量是巨大。因此先对数据点进行采样,算法是FPS最远点采样(c++ cuda编程),相对于随机采样,这种采样算法能够更好地覆盖整个采样空间;第一次的set abstraction在原始点云上采样512个点,选中了512个特征中心;第二次的set abstraction是在特征图上采样128个特征中心;第三次的set abstraction特征图上所以点都是特征中心。 FPS希望达到尽可能采远处的点。
- Grouping :为了提取一个点(特征中心)的局部特征,首先需要定义这个点的”局部”是什么。点云数据中的一个点的局部由其周围给定半径划出的球形空间内的其他点构成(c++ cuda编程)。组合层的作用就是找出通过采样层后的每一个点的所有构成其局部的点,以方便后续对每个局部提取特征。第一次的set abstraction特征中心局部球体半径0.2,提取点数为32;第二次的set abstraction特征中心局部球体半径0.4,提取点数为64;第三次的则全部点就是局部。此外代码对于提取局部点除了这种query_ball_point策略还有第二种策略:knn search的方法。
- PointNet layer(feature extract):PointNet给出了一个基于点云数据的特征提取网络,因此用PointNet对组合层给出的各个局部进行特征提取来得到局部特征。虽然组合层给出的各个局部可能由不同数量的点构成,但是通过PointNet后都能得到维度一致的特征(由K值决定)。
单尺度网络模型:
input:(B n 3)
pointnet_sa_module1{
sample
(B 512 3) # sample output
group
(B 512 3 32 ) # group output
Point Feature Embedding
(B 512 3 32 ) # Fisrt conv2d output
(B 512 3 64 ) # Second conv2d output
(B 512 3 128) # Third conv2d output
MaxPooling
(B 512 128)
}
pointnet_sa_module2{
sample
(B 128 128)
group
(B 128 128 64)
Point Feature Embedding
(B 128 128 128)
(B 128 128 128)
(B 128 128 256)
MaxPooling
(B 128 256)
}
pointnet_sa_module3{
sample
(B 128 256)
group
(B 128 256 128)
Point Feature Embedding
(B 128 128 256)
(B 128 128 256)
(B 128 128 1024)
MaxPooling
(B 128 1024)
}
reshape
(B 128x1024)
fc1
(B 512)
fc2
(B 256)
fc3
(B 40) # 40 class output
分类:set abstraction的结果 得到globle feature,再经过mlp(多层fc),得到分类结果。
分割:对于分割,还需要将下采样后的特征进行上采样,使得原始点云中的每个点都有对应的特征,这个上采样的过程通过最近的k个临近点进行插值(3D的插值)计算得到,模型类似Unet,最终得到分割结果。
多尺度网络:
- 单尺度网络的局限性
在pointnet++中,piontnet就是卷积核,如何选择局部区域的大小,就是如何选择卷积核的大小宽度,如何选择pointnet 作用区域的球的半径?
在卷积神经网络中大量应用小的kernal(VGG 333),在pointcloud中是否一样呢?不一定。
因为pointnet 常见的采样率的不均匀,比如有个depth camera 采到的图像,近的点非常密集,远的点非常稀疏,在密的地方没有问题,在稀疏的会有问题,比如极端的情况,只有一个点,这样学到的特征会非常的不稳定,我们应该避免。
为了量化这个问题,有个控制变量的实验,在刚开始1024点的时候pointnet++ 更加强大,得到更高的精确度,随着密度的下降,性能受到了极大的影响,在小于500个点以后性能低于pointnet。
如果点云稀疏,局部的kernel(pointnet)太小的话,会影响性能,各处采样率不均匀。
针对于这个问题,我们希望设计一个神经网络来智能学习,如何综合不同区域大小的特征,得到一个鲁棒的学习网络,希望在密集的地方相信这个特征,稀疏的地方不相信这个特征,而去看更大的区域。
- MSG/MRG解决单尺度网络的局限性
比较简单的做法是设计一个Multi-scale :在这个2D的例子中 将不同半径的区域 ,联合在一起。
多尺度,多分辨率的Grouping的学习。MSG有点像金字塔网络,MRG有点像inception中的结构多种卷积核。
MSG,即把每种半径下的局部特征都提取出来,然后组合到一起,作者在如何组合的问题上提到了一种random dropping out input points的方法,存在两个参数p和q(原文中为theta),每个点以q的概率进行丢弃,而q为在[0,p]之间均匀采样,这样做,可以让整体数据集体现出不同的稠密性和均匀性。MSG有一个巨大的问题是运算的问题,然后作者经过思量,提出we can avoid the feature extraction in large scale neighborhoods at lowest levels,因为在低层级处理大规模数据,可能模板处理能力不够,感受野有些过大,基于此,作者提出了MRG。
MRG有两部分向量构成,分别为上一层即Li-1层的向量和直接从raw point上提取的特征构成,当点比较稀疏时,给从raw point提取的特征基于较高的权值,而若点比较稠密,则给Li-1层提取的向量给予较高的权值,因为此时raw point的抽象程度可能不够,而从Li-1层的向量也由底层抽取而得,代表着更大的感受野。它有个好处,可以节省计算,在下一级的特征已经计算好了,只需要把它池化拿来用就行了。 而在MSG中需要对不同尺度分别计算。
发现加了MRG和MSG中,丢失数据后鲁棒性能好很多。
多尺度 point++ 分类模型 pointnet2_cls_msg.py
# 三个尺度的特征中心的局部半径[0.1,0.2,0.4]
l1_xyz, l1_points = pointnet_sa_module_msg(l0_xyz, l0_points, 512, [0.1,0.2,0.4], [16,32,128], [[32,32,64], [64,64,128], [64,96,128]], is_training, bn_decay, scope='layer1', use_nchw=True)
l2_xyz, l2_points = pointnet_sa_module_msg(l1_xyz, l1_points, 128, [0.2,0.4,0.8], [32,64,128], [[64,64,128], [128,128,256], [128,128,256]], is_training, bn_decay, scope='layer2')
l3_xyz, l3_points, _ = pointnet_sa_module(l2_xyz, l2_points, npoint=None, radius=None, nsample=None, mlp=[256,512,1024], mlp2=None, group_all=True, is_training=is_training, bn_decay=bn_decay, scope='layer3')
# Fully connected layers
net = tf.reshape(l3_points, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training, scope='fc1', bn_decay=bn_decay)
net = tf_util.dropout(net, keep_prob=0.4, is_training=is_training, scope='dp1')
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training, scope='fc2', bn_decay=bn_decay)
net = tf_util.dropout(net, keep_prob=0.4, is_training=is_training, scope='dp2')
net = tf_util.fully_connected(net, 40, activation_fn=None, scope='fc3')
return net, end_points
pointnet++ 大幅提高了场景分割性能,因为多级的结构,使得他更鲁棒的对局部的特征更好的学习,同时还有平移不变性的特点。
pointnet++ 不局限于2D或者3D欧式空间,可以拓展到任意的测度空间,只要有个定义好的距离函数。
pointnet++开创了点云直接法的先河。pointnet++之前的方法是基于点云投影到图片上(鸟瞰图),在图片中做,缺点是丢失了三位的结构信息,在图片的表达形式下,2D的cnn受到了很大的局限,很难精确的估计物体的深度和大小;或者三维的box也可以是3D的cnn来做,propos完之后可以把2D和3D的feature结合,缺点是三维搜索空间非常大,计算量也非常大,而且在3D中proposal 点云的分辨率非常有限,很多时候很难发现比较小的物体。
好文: blog.csdn.net/qq_24505417/article/details/108987171 zhuanlan.zhihu.com/p/105433460
- 大场景点云分割的难点
PointNet, PointNet++等一系列方法在处理S3DIS这种大场景数据集时,都需要先将点云切成一个个1m×1m的小点云块,然后在每个点云块中采样得到4096个点输入网络。
这种预处理方式虽然说方便了后续的网络训练和测试,但同时也存在着一定的问题。
将整个场景切成非常小的点云块是否会损失整体的几何结构?用一个个小点云块训练出来的网络是否能够有效地学习到空间中的几何结构呢?Original: https://blog.csdn.net/weixin_41965898/article/details/119949613
Author: lucky li
Title: 点云算法(深度学习)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/624954/
转载文章受原作者版权保护。转载请注明原作者出处!