

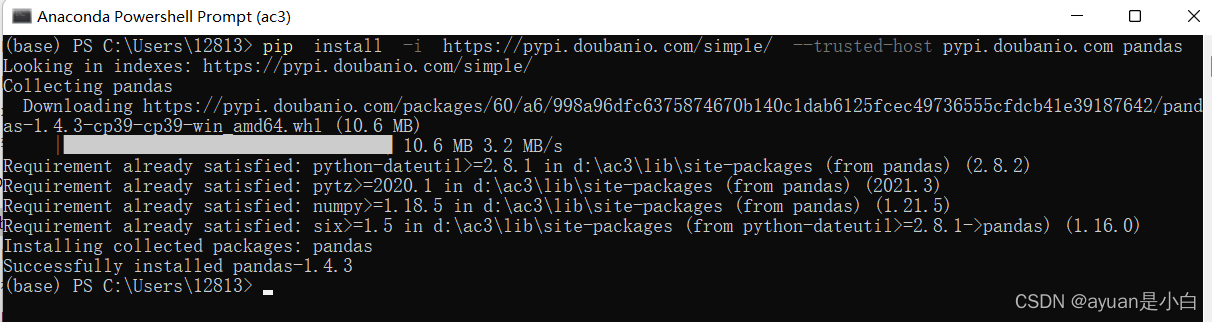
首先打开Anaconda Powershell Prompt,输入豆瓣镜像源相关包的下载地址
pip install -i https://pypi.doubanio.com/simple/ –trusted-host pypi.doubanio.com
com后面要有空格,空格后面加pandas,后面好识别pd(pandas是包名,也可以改成其他任意名字,但是尽量不要改,容易出错)


打开JuypterNotebook中需要的项目,输入读取三种文件的语句

1.大小。shape
import pandas as pd
data =pd.read_csv(‘beef.csv’)
print(data.shape)
2数据表.基本信息。info
import pandas as pd
data =pd.read_csv(‘beef.csv’)
print(data.info)
3.查看每一行的格.dtype
import pandas as pd
data =pd.read_csv(‘beef.csv’)
print(data.dtypes)
4.查看前2行数据、后2行数据
df.head() #默认前10行数据,注意:可以在head函数中填写参数,自定义要查看的行数
df.tail() #默认后10 行数据
import pandas as pd
data = pd.read_csv( 'beef.csv' )
print (data)
print (data.head( 2 ))
print (data.tail( 2 ))
豆瓣镜像地址:https://pypi.douban.com/simple/
Original: https://blog.csdn.net/m0_68465703/article/details/126653240
Author: ayuan是小白
Title: Jupyter:用python读取pandas的csv文件,txt文件和excel文件
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/670741/
转载文章受原作者版权保护。转载请注明原作者出处!