

Table of contents
一、前言:
- 一开始很幸运在别人邀请下参加了比赛,后来很感谢自己参加了这次比赛,对我帮助很大。我觉得对于比赛要有一个认知:在大多数时候竞赛都更像是一种以赛促学的形式,且对数据挖掘,数学建模感兴趣的同学来说,参加泰迪杯是非常好的培养自身能力的比赛,而且泰迪杯的比赛周期长达两个月,对于小白来说时间非常充裕,有足够的时间学习,这几个月时间中你会学到在课堂上学不到东西,前提是你们不能摆烂,要实实在在当作一场比赛,在比赛过程中,
你会学习到:
python基础(这里以博主经历 来说),pandas数据处理,matplotlib、seaburn、poltly可视化工具,tensorflow,sklearn机器学习库实现建模过程,学习论文写作,团队协作能力,从竞赛你能更加了解机器学习的实际应用,这些都是从课本学习不到的,特别是比赛经历,对以后竞赛类都是一次很不错的经验。
当时参赛学习的资料


看了许多论文(感觉论文帮助挺大的)


0基础学Python,一天看完泰迪云视频的 😂(后面很容易忘,要复习)

特别补充:
泰迪杯报名参赛后,一定要利用好官网资源!泰迪云中对参赛选手基础给予了全免费的教程,可以学到对于需要用到知识的大部分基础,从python基础到数据集可视化,tensorflow sklearn建模,以及赛题分析,论文写作也有教程,在官网资源库中也有历年的特等奖论文进行参考,一定好利用好这部分资源。
以下只为个人学习总结,如果错误在所难免,请各位读者斧正。
✨完整源码获取!🎉
; 二、学习总结:
学习总结之mathplotlib篇
学习总结之tensorflow篇
学习总结之skleaen篇
学习总结之数据处理篇
学习总结之建模篇
学习总结之论文篇
三、B题:电力系统负荷预测分析—题目分析
3.1 选题
我们队伍在一开始选题,一名队员是想选择A题图象识别的或者C题的文字识别,但是我们两个男队员觉得B题是纯数据,而且我们都是数据科学与大数据专业的,就早早定下了B题。
3.2 原题查看
原题:
1.地区负荷的中短期预测分析根据附件中提供的某地区电网间隔 15 分钟的负荷数据, 建立中短期负荷预测模型:
(1) 给出该地区电网未来 10 天间隔 15 分钟的负荷预测结果,并分析其预测精度;
(2) 给出该地区电网未来 3 个月日负荷的最大值和最小值预测结果,以及相应达到负荷最大值和最小值的时间,并分析其预测精度。
2.行业负荷的中期预测分析对不同行业的用电负荷进行中期预测分析,能够为电网运营与调度决策提供重要依据。 特别是在新冠疫情、国家”双碳”目标等背景下, 通过对大工业、 非普工业、普通工业和商业等行业的用电负荷进行预测, 有助于掌握各行业的生产和经营状况、 复工复产和后续发展走势,进而指导和辅助行业的发展决策。请根据附件中提供的各行业每天用电负荷相关数据, 建立数学模型研究下面问题:(1)挖掘分析各行业用电负荷突变的时间、量级和可能的原因。
(2)给出该地区各行业未来 3 个月日负荷最大值和最小值的预测结果,并对其预测精度做出分析。
(3)根据各行业的实际情况,研究国家”双碳”目标对各行业未来用电负荷可能产生的影响,并对相关行业提出有针对性的建议。
3.3 解题历程
3.3.1 阶段一
对于该题我们一开始讨论就认为大概思路是
建立数学模型,使用机器学习,深度学习,人工智能实现预测模型。 (一开始真的什么都不懂)只是刚好上过一节人工智能神经网络的公开课,有一点点了解)。然后就开始自己找资料,但是找的部分资料都没有很好的对症下药,而且部分也不是很看得懂(当时得基础只有
上学期学完的C语言,还有基础比较好的高数(数学在计算机这方面很重要,机器学习原理都是由数学出发的),而且只自学了一部分python的用法),所以一开始真的没有什么信心。
3.3.2 阶段二
我们选的导师是一个很尽责的老师,也曾带队在泰迪杯获奖,老师在对我们的建议是 到官网上查找资料,还有利用学校的图书馆资源在知网畅游,也可以网上购买一些大牛的书查阅(这里的大牛的书指的是开办泰迪杯比赛的大牛,有一本好像叫《python数据挖掘》),其中对我来说最重要的指点是到 官网查找资料和知网使用。
3.3.3 阶段三
步入正轨,泰迪杯比赛有一个泰迪云学习网站,里面有一个竞赛指导,里面有各个需要用到方法的基础知识(sklearn,tensorflow,numpy和pandas两兄弟,matplotlib等)我一开始在里面看B题对应的LSTM时间序列示例预测视频(每道题都有一个案例视频对应,感觉官方是真不错!),看第一遍觉得没什么(主要是没太看懂里面的函数和各个用法)看第二遍才发现完全可以套用在第一题!然后我顺着视频思路往下,照炉画瓢写了一个一样的模型。这才对解题有了一个思路,后面求解也遵从这个思路。
3.4 题目分析
3.4.1 官方所给全部数据附件目录


附件2-行业日负荷数据.csv数据格式如下:
篇幅有限只放部分数据(各行业)



附件3-气象数据.csv数据格式如下
注意:这其中的是测试数据,是只有15天的,在到了大概交论文前15天才会给大数据集(三年的),后面再给对应时间数据最终预测的
各题思路如下
; 3.4.1 第一题:
1.地区负荷的中短期预测分析根据附件中提供的某地区电网间隔 15 分钟的负荷数据, 建立中短期负荷预测模型:
(1) 给出该地区电网未来 10 天间隔 15 分钟的负荷预测结果,并分析其预测精度;
3.4.1.1解题流程:
- 数据初步分析
- 数据预处理 (重要)
- 数据分析 (处理好数据后,对数据做回归分析,正态检验等)
- 建立模型
- 模型评价
在其他文章中都是将数据预处理作为第一步,但是在平时建模一般是对其数据先做一个初步分析,在选择对需要的数据预处理,因为有部分数据是有可能用不上的,这个时候就可以省去时间。
3.4.1.2 数据初步分析:
可以看出题目给了从
2018/1/1 0:00:00 到 2021/8/31 23:45:00的每十五分钟的数据 ,其中附件二是各行业数据与第一题无关,接着是附件2气象条件。
题目需要预测的是每十五分钟的,而所给气象则是每日的,突变性太大,对模型帮助不大,所以我们综上只能以 单变量预测,
使用 LSTM时间序列模型。
模型原理讲解文章传送门:(更新中)
; 3.4.1.3数据预处理:
- 查找缺失值:
使用pandas 引入数据 在函数有一个参数:
na_values=[‘?’, 0, ‘nan’], # 设置缺失值的表示值,因为系统默认缺失值表示是NAN在实际中可能会有?等表示,所以不要漏了。
import pandas as pd
data = pd.read_csv("./全部数据/全部数据/附件1-区域15分钟负荷数据.csv",
sep=',',
na_values=['?', 0, 'nan'],
parse_data= ['数据时间']
)
特别注意!!!
在对于时间序列的数据来说,官方还会挖一个坑,就是缺失值是日期,我们一般处理数据缺失值的都是所给数据,故会容易忽略时间,而对于时间序列模型,时间连续性是很重要的,这里的时间缺失比较特殊,我的解决办法是,形成对应的的时间时间序列data_range,然后对源数据重新设置索引(设置为data_range)对于没有的数据其会设置其为NAN。
data_range = pd.date_range(start=data['数据时间'].min(), end=data['数据时间'].max(),
freq='15T')
data = data.set_index('数据时间').reindex(index=data_range)
这里挖个坑,由于缺失的天数是一整天对于每十五分钟来说是96份数据,这么一大份数据连续缺失,由于才疏学浅,目前还未掌握解决方法,只能全部填充平均值(以后学了再回来填,各位读者可以上网搜相关方法)
接着使用pandas 的DataFrame数据结构查找并填充十分方便(只需一行代码):
data = data.fillna(data['power'].mode().mean())
我这里填充的是平均值,因为当时对缺失值处理没有一个更好的办法,现在应该使用KNN的 (KNN原理讲解文章传送门:更新中)
- 异常值处理:
箱线图四分位距(顾名思义:分成四份)判定异常值:
(箱线图原理传送门文章:更新中)
代码实现:
Dinfo = data.describe()
d1 = Dinfo.loc['25%']
d2 = Dinfo.loc['75%']
d = d2 - d1
dl1 = d1 - (1.5 * d)
dl2 = d2 + (1.5 * d)
datanew = datanew.values
for i in range(len(datanew)):
if ((datanew[i] > dl2) | (datanew[i] < dl1)).bool() is True:
datanew[i] = mean
处理异常值要填充的话我也是填充平均值( 异常值处理知识待填补)
- 数据归一化
数据归一化好处
- 数据存在不同的评价指标,其量纲或量纲单位不同,处于不同的数量级。解决特征指标之间的可比性,经过归一化处理后,各指标处于同一数量级,便于综合对比。
- 求最优解的过程会变得平缓,更容易正确收敛。即能提高梯度下降求最优解时的速度。
- 提高计算精度
我们这里只有一个变量,不用考虑量纲单位不同影响结果,但是由于数据值很大 每个值 都是十几万,那么在训练模型时,容易发生梯度爆炸或者是梯度消失,归一化数据后训练结果更加容易收敛,计算精度也可以很好提高
这里我们用最大值最小值来缩放(scale) 数据,
原理:
把数据缩放到一个设定区间中,默认为0~1,公式是
X/(XMAX-XMIN) * (设置区间差) + 设置好的区间最小值
其中X是数据 ,这样就可以实现缩放(由于缩放是根据最大最小值所以叫MaxMinsclar
我是用skleran(机器学习库)的preprocessing (预处理)库中引入 MaxMinScaler实现
(注:在我印象中sklearn主要用于机器学习 ,tensorflow主要用于深度学习)
代码实现:
from sklearn.preprocessing import MinMaxScaler
Scaler = MinMaxScaler()
Min_Max_Scaler = Scaler.fit(datanew)
data_nor = Min_Max_Scaler.transform(datanew)
- 构建滑动窗口数据集
自己粗略大概画了一个图:
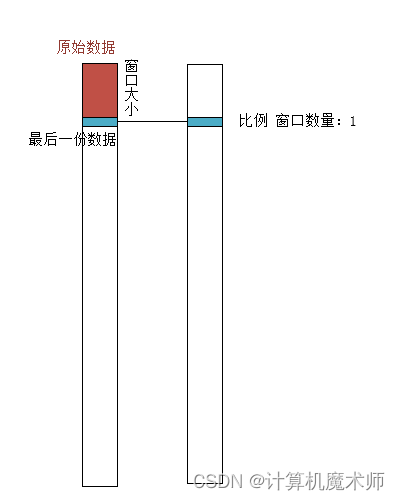
我们是单变量预测所以需要构建特征,这里思路就是是以五十个数据 作为 第五十个数据的特征,以这五十个数据来预测最后一个的数据(注:在LSTM多变量特征预测中在划分好数据集,也要再次这样构建滑动窗口数据集的,因为我们的模型建立是LSTM时间序列模型,是有一定的时序性的,这样做可以让模型更好的学习,但是本题是单变量,这里目的是为了构建特征,是不同于多变量做法的目的的)
代码实现:
构件滑动窗口数据集
def dataset(data, win_size=50):
x = []
y = []
for i in range(len(data) - win_size):
temp_x = data[i:i + win_size]
temp_y = data[i + win_size]
x.append(temp_x)
y.append(temp_y)
x = np.asarray(x)
y = np.asarray(y)
return x, y
data_x, data_y = dataset(data_nor)
data_x = data_x.reshape(-1, 1, 50)
- 划分训练集和测试集
采用的模型是LSTM(监督学习算法),在建模过程我们往往需要查看模型的实际拟合效果,常见的办法是通过划分数据集和测试集,通过测试集的feature预计结果和测试集的target可视化查看拟合度,
*实现:
- 一般是将数据的80%作为训练集,20%作为测试集(也可以根据需求调整)
- 用函数自定义实现
- 用sklearn库中train_test_split函数是实现(常用)
实现简单,快速,且有一些参数非常方便,
比如 shuffle=True,不打乱划分顺序,这点十分重要,因为我们的时间序列预测,所以要保证时间序列连续性,还有一些参数,分层抽样等。。。
代码实现:
from sklearn.model_selection import train_test_split
切分数据集和训练集 使用 train_test_split 必须不能打乱 shuffle = False
train_x, test_x, train_y, test_y = train_test_split(data_x, data_y, test_size=0.2, shuffle=False)
3.4.1.4模型建立
from tensorflow import keras
模型搭建
使用tensorflow2 实现LSTM, 连接层
model = keras.Sequential()
这里的shape 1, 表示的是一维 2 表示 五十个数据
model.add(keras.layers.LSTM(128,
return_sequences=True, # 多对多数据返回
# 输入维度 步长为train_x.shape[1],特征值数量为train_x.shape[2]
input_shape=(train_x.shape[1], train_x.shape[2])))
model.add(keras.layers.LSTM(32, return_sequences=False)) # 多对一数据返回
model.add(keras.layers.Dropout(0.2)) # 丢掉20%样本数据
model.add(keras.layers.Dense(1, activation='relu')) # 全连接层
编译 设置loss=mean square error 这里没有评价函数
model.compile(loss='mse', optimizer='adam')
模型与验证 # batch_size 每一批用多少样本来实现
history = model.fit(train_x, train_y, epochs=5, validation_split=0.2, shuffle=False, batch_size=43)
查看神经元个数
model.summary()
输出结果:
Epoch 1/5
1913/1913 [==============================] - 10s 4ms/step - loss: 0.0097 - val_loss: 0.0010
Epoch 2/5
1913/1913 [==============================] - 7s 4ms/step - loss: 0.0062 - val_loss: 0.0020
Epoch 3/5
1913/1913 [==============================] - 7s 4ms/step - loss: 0.0054 - val_loss: 0.0018
Epoch 4/5
1913/1913 [==============================] - 8s 4ms/step - loss: 0.0049 - val_loss: 0.0012
Epoch 5/5
1913/1913 [==============================] - 8s 4ms/step - loss: 0.0046 - val_loss: 7.9970e-04
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 1, 128) 91648
lstm_1 (LSTM) (None, 32) 20608
dropout (Dropout) (None, 32) 0
dense (Dense) (None, 1) 33
=================================================================
Total params: 112,289
Trainable params: 112,289
Non-trainable params: 0
_________________________________________________________________
其中两个指标
loss代表训练集的损失值,在网络中用于更新网络参数;val_loss代表验证集的损失值(有时也写成测试集损失test_loss)不对网络参数做修改,只做测试。
可以看到我们的代价函数 loss和 val_loss是在持续递减的,这说明我们的拟合效果不错。
- 对loss,val_loss可视化
模型在训练返回一个 <keras.callbacks.history at 0x1fff650f3d0></keras.callbacks.history> keras回调历史,改返回值的的history属性存贮了每一次训练的 loss和 val_loss变化值。
import matplotlib.pyplot as plt
# 绘制模型训练图
plt.figure(figsize=(5, 10), dpi=80)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.tight_layout()

3.4.1.6模型测试
根据此模型使用测试集 target 预测的结果与 测试集真实值 feature使用决定系数R 2 R^2 R 2查看拟合度,并对其前五百份数据可视化
- 代码实现:
from sklearn.metrics import r2_score
模型测试
y_pred = model.predict(test_x)
metrics 度量
y_pred = y_pred.reshape(-1, 1)
r2_score(test_y, y_pred)
可视化
plt.figure(figsize=(10, 10), dpi=80)
plt.plot(test_y[:1000], color='red')
plt.plot(y_pred[:1000], color='blue')
plt.legend(['test_y', 'y_pred'])
plt.title('测试结果', fontsize=16)
plt.tight_layout()
R 2 R^2 R 2系数(可以看到模型非常不错):

拟合效果也佳

3.4.1.7模型预测
由于我们是预测未来的十天电力负荷,也就是说我们是没有对应
target用于预测feature的,这个时候我们同样使用 滑动窗口的思想,训练集的target的特征是之前的50份数据电力负荷数据,预测的结果feature恰好是下一份电力负荷数据,那便可以将最后的50份数据作为特征的’target’预测出的一份featrue加到最后50份数据作为特征的target,并删除这51份数据时间最早的一份,剩下的一份target就是包含了所预测的最新数据替代时间最早的数据作为特征的,按照这个思路我们就可以预测出未来的数据
- 代码实现:
模型预测
预测未来十五分钟的趋势
def predict_all(model, last_x, num=96):
pred_y = []
for i in range(num):
temp_y = model.predict(last_x) # 所预测的数据
pred_y.append(temp_y[0][0])
temp_y = np.expand_dims(temp_y, axis=0) # 按target维度一样增加维度
last_x = np.concatenate([last_x[:, :, 1:], temp_y], axis=2) # 合并二者数据,丢掉第一份数据
return np.asarray(pred_y)
测试集最后一份数据
last_x = test_x[-1]
由于LSTM模型输入必须是三维的 (数据量,步长,特征),增加一维
last_x = np.expand_dims(last_x, axis=0)
Series = predict_all(model, last_x, num=960)
可视化结果
plt.plot(Series)
plt.title('预测结果', fontsize='16')
plt.tight_layout()

对于LSTM 及其不友好的便是中长期预测,可以看到在后面时期时候 预测结果失去鲁捧性,所以在当时LSTM预测并不是一个特别好的选择,可以使用其他模型,小组两外一个成员使用的是
ARIMA,对中长期更加不友好了,结果甚至趋于一条直线,后面改用auto ARIMA预测结果才看起来比较好. 但模型建议能用多一点就用多一点,毕竟论文是很重要的,可以几个差的模型突出最优的模型
3.4.1.8数据反归一化
由于我们的数据是经过 MaxMinsclar进行归一化,特征缩放的,此时需要反归一化,得到预测的原始数据,并将原始数据对于时间存贮至 excel表格中.
- 实现代码
数据反归一化
True_predicts = Scaler.inverse_transform(Series.reshape(-1, 1)) # 维度变回 二维进行反归一化
生成对应时间
data_range0 = pd.date_range(start='2021-09-01 00:00:00', end='2021-09-10 23:45:00', freq='15T')
生成dataframe进行存贮
a = pd.DataFrame(True_predicts, index=data_range0)
a.to_excel('finally data.xlsx')
3.4.2 第二题
关于第一大题的第二小问 需要用到 天气特征,同样按照
LSTM的方法,通过 相关性热力图确定相关性高的特征作为feature用于预测数据,但是不同于单变量预测,此时是多变量预测,所以在构建特征直接使用天气变量预测结果(且 预测未来是需要对应天气特征的,如果使用 滑动窗口精确度不是特别理想的结果,而官方也声明到29号会 给出天气数据)
所以这里提取天气特征,并构建数据集,构建好数据集后,在构建时序模型数据集(步长)进行预测结果,我们团队将 LSTM和 ARIMA模型作为叶子,衬托出 autoTS模型。
3.4.2 第三题
第三题我们处理的方式比较简单,突变量级我们已 一阶差分和二阶差分作为衡量的标准,即 diff()函数实现,使用 四分位距, 和 3σ 原则进行突变量级的分析。
3.4.3 第四题
- 我们需要预测各行业的电力负荷数据
同样作为单变量预测,我们还是以
LSTM和ARIMA模型作为叶子,衬托出autoTS模型。
本题最难的地方在于调超参,参数如果一样是不适配其他模型,而我们在验证数据评价好坏时将历年电力月份数据可视化进行对比调整参数(现在想想也是不错的方法🤭)
四、全国三等奖(附源码获取) 🎉

✨完整源码获取!
添加微信 D1928787583 在线联系博主有偿获取全套资源以及讲解(建议大家微信在线联系有偿获取哦🥳)
这里给大家看看之前作为付费资源的 好评率



🌹总共八次下载,但每次都是返回五星评价,且给予高质量的回答,这无疑是巨大的肯定,会持续输出更多优质文章的🙋♂️🙋♂️
更新时间— 2022.8.24 16:37

Original: https://blog.csdn.net/weixin_66526635/article/details/124501396
Author: 计算机魔术师
Title: 第十届“泰迪杯“感谢学习总结(国三附源码)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/668978/
转载文章受原作者版权保护。转载请注明原作者出处!