

ERNIE: Enhanced Language Representation with Informative Entities(ERNIE)
前记: 【预训练语言模型】系列文章是对近几年经典的预训练语言模型论文进行整理概述,帮助大家对预训练模型进行全局的理解。本系列文章将不断更新,敬请关注博主。本文分享一个对BERT进行改进的预训练模型,其认为传统的预训练模型都只考虑了文本自身,而没有考虑到外部知识,因此作者在原有的预训练任务基础上,增加了一个结合知识图谱的预训练。
简称 : Enhanced Language Representatio N with Informative Entities
会议: 2019ACL
开源:https://github.com/thunlp/ERNIE
一、摘要:
神经自然语言表征模型(例如在大规模语料上预训练的bert)可以很好的捕捉原始文本中的语义模式,并根据不同的NLP任务进行微调。然后,现有的预训练语言模型很少有考虑到结合知识图谱(Knowledge Graph,KG),而知识图谱则可以提供丰富的结构化知识用于更好地进行语言理解。我们认为在KG中富含信息的实体和外部知识可以增强语言表征。本文,我们同时利用大规模的文本语料和知识图谱来训练一个增强的语言表征模型(ERNIE),其可以同时充分利用词法、语法和知识的优势。实验结果表明,ERNIE在许多知识驱动的任务上获得了重要的提升,同时超过了其他以BERT以及其他有关的任务上。
二、动机:
- 现如今一些预训练模型可以通过微调以达到最好效果,例如实体识别、问答系统、自然语言推理和文本分类等任务。但 这些模型均忽略了使用外部的知识信息辅助增强语言理解。尤其是对于实体分类或者关系分类等任务上。
注释:对于现有的预训练模型来说,不考虑实体知识信息,模型无法知道每个实体具体的含义,例如对于句子”Bob Dylan wrote Blowin’ in the Wind in 1962, and wrote Chronicles: Volume One in 2004.”,如果不知道”Bob Dylan”是一个人,”Blowin’ in the Wind”是一本书,1962代表时间,那模型只知道”UNK wrote UNK in UNK”,很显然这会带来语法句法和语义上的模糊问题
- 将外部知识引入到自然语言表征模型上,存在两个主要挑战:
(1)如何对结构化知识进行表征(Structured Knowledge Encoding):给定一个文本,如何有效地抽取并编码相关联的信息;
(2)如何处理异构信息融合(Heterogeneous Information Fusion):预训练的文本信息和结构化知识表征信息属于两个不同的结构,语义层面上则分属不同的向量空间,因此如何将异构信息进行融合;
(3)如何设计一个预训练的目标以充分利用词法、语法和结构知识 - 为了解决上述的问题, 我们提出一种利用富含信息的实体来增强的语言表征模型(ERNIE),该模型可以同时在大规模的文本和知识图谱上进行预训练。
三、方法:
- 抽取与表征知识:首先使用实体识别将文本中的实体与知识图谱进行链接,并使用TransE模型将知识图谱进行嵌入式表征作为ERNIE模型的输入。最后ERNIE将知识模块中的实体表示集成到语义模块的底层;
- 与BERT类似,我们使用MLM(Masked Language Model)和NSP(Next Sentence Prediction)作为预训练的目标。为了充分的将知识结合文本,我们提出一种新的预训练目标,即随机mask一些命名实体,并让模型去知识图谱中选择相应的实体来进行补全。我们的方法需要模型同时利用上下文以及知识图谱的事实来预测token以及entity
四、模型:


模型架构如上图所示。
说明:原始文本对应的序列是token序列,知识图谱则对应的是实体entity序列,通过实体识别和链接将token与entity进行对齐,但并非所有的token都有与之对应的实体。若某个token能与某个实体对齐,则记做 e = f ( w ) e=f(w)e =f (w )。
ERNIE包含两个堆叠的模块:
- Underlying Textual Encoder(T-Encoder):用于捕捉词法和语法信息;
- Upper Knowledgeable Encoder(K-Encoder):用于将原始的token对齐的实体信息集成进来
; 4.1 Underlying Textual Encoder(T-Encoder)
输入input token表征,包括token embedding、segment embe以及position embedding三者之和;其次喂入到T-Encoder中获得词法和语法表征,T-Encoder即是一个多层的Transformer模型(BERT中的结构)。该部分的输出表征向量将喂入下一层T-Encoder,直到Underlying Textual Encoder结束(如图,T-Encoder包含N层)。T-Encoder的最终输出将喂入K-Encoder。
简单地来说,这一部分的架构完全与BERT一致
4.2 Upper Knowledgeable Encoder(K-Encoder)
这一部分也是包含多层堆叠的模块,记做aggreator,第i层的输入是第i-1层的输出。该模块包含原始的token表征(经过T-Encoder表征后的结果)以及实体表征(经过预训练TransE表征后的结果)。首先将其分别喂入两个多头注意力(参数不共享):

其次,使用Information Fusion对token和entity进行融合,这里需要分两种情况讨论:
(1)对于每个token w w w 以及其相应对齐的实体 e = f ( w ) e=f(w)e =f (w ) ,通过下面公式实现相互信息融合:

(2)对于每个token w w w ,如果其不含有对齐的实体,则通过下面的公式:

如上图可以看出,如果token有对齐的实体,则拼在一块去计算,计算完后再分离出来;如果token没有对齐的实体,则单独计算,第 i 个aggregator的输出包含token embedding以及对应的entity embedding。整个T-Encoder的输出也是如此。
; 4.3 Injecting Knowledge
我们定义了一个新的预训练任务dEA,即随机mask一些token-entity alignment,并让模型去预测token是对应哪个实体。因为知识图谱的规模庞大,因此我们只在给定的实体序列中去预测。预测某个token是否是与某个entity对齐,可以定义下面的相关度分布函数:
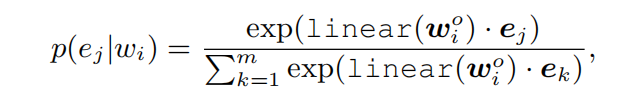
对于mask方法,其仿照BERT进行如下操作:
- 5%的概率,对于给定的token-entity alignment对,将entity替换为其他随机的entity,需要模型能够识别出那些token错误对齐的实体;
- 15%的概率则mask整个token-entity alignment,让模型能够识别出那些没有完全抽取所有的token-entity alignment;
- 80%的概率则保持不变,以让模型能够充分将实体信息集成到文本中以增强语言理解。
其次还使用MLM和NSP任务,三个任务的loss之和作为整个预训练任务的loss。
五、微调(Fine-tuning)
微调部分与BERT类似,定义了一些特殊的标记,例如 [CLS] 等,如下图,包含传统NLP任务、实体类型自己关系分类:

(1)关系分类:使用 [CLS] 标签对应的embedding,在输入部分则加入 [HD] 和 [TL](分别表示头实体和尾实体)等特殊标记用于显式明确实体的位置信息;
(2)实体类型:添加 [ENT] 标签,使用 [CLS] 对应的embedding进行分类;
; 六、ERNIE的实验细节:
(1)对于T-Encoder部分,其直接使用BERT,因此直接使用预训练的参数初始化这个模块;
(2)统计一共包含4500万个subwords,140万个实体,且每个句子保证至少有三个实体;
(3)使用TransE预训练实体表征,包含5040986个实体和24267796个事实(三元组),在ERNIE模型中这些实体表征固定不变
(4)T-Encoder和K-Encoder的层数均为6,token表征向量维度为768,entity维度为100,对于token表征的multi-head attention,其head数为12,对于entity部分则head数为4,参数总量为114M。
(4)作者在annotation和distant supervision两种类型的数据上进行实验,证明只需要很少次数的预训练即可以实现微调。
(5)消融实验验证了同时添加实体信息、以及dEA预训练任务,均可以在FewRel(一种小样本的关系抽取任务)上得以提升。
七、未来研究:
- 将knowledge注入到其他feature-based语言模型(例如ELMo);
- 引入多种结构知识表征,例如同时使用概念图谱(ConceptNet)和世界知识图谱(Wikidata);
- 启发式地标注更多真实语料用于构建预训练数据集,将有助于自然语言理解任务;
对于本文如若有疑难,错误或建议可至评论区或窗口私聊, 【预训练语言模型】 系列文章将不断更新中,帮助大家梳理现阶段预训练模型及其重点。
Original: https://blog.csdn.net/qq_36426650/article/details/112224304
Author: 华师数据学院·王嘉宁
Title: 【预训练语言模型】ERNIE: Enhanced Language Representation with Informative Entities(ERNIE)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/594846/
转载文章受原作者版权保护。转载请注明原作者出处!