

模型
sklearn.svm中的支持向量机:
Classify: SVC、 nuSVC、 LinearSVC
Regression: SVR、 nuSVR、 LinearSVR
OneClassSVM
本文采用 Classify系列,classify三个模型的区别;参数详解
预处理
import pandas as pd
path = "../Data/classify.csv"
rawdata = pd.read_csv(path)
X = rawdata.iloc[:,:13]
Y = rawdata.iloc[:,14]
Y = pd.Categorical(Y).codes
建模
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, recall_score
import sklearn.svm as svm
x_train, x_test, y_train, y_test = \
train_test_split(X, Y, test_size=0.3)
model = svm.SVC(kernel="linear", decision_function_shape="ovo")
训练
acu_train = model.score(x_train, y_train)
acu_test = model.score(x_test, y_test)
y_pred = model.predict(x_test)
recall = recall_score(y_test, y_pred, average="macro")
多种SVC、核函数对比
def svc(kernel):
return svm.SVC(kernel=kernel, decision_function_shape="ovo")
def nusvc():
return svm.NuSVC(decision_function_shape="ovo")
def linearsvc():
return svm.LinearSVC(multi_class="ovr")
def modelist():
modelist = []
kernalist = {"linear", "poly", "rbf", "sigmoid"}
for each in kernalist:
modelist.append(svc(each))
modelist.append(nusvc())
modelist.append(linearsvc())
return modelist
def svc_model(model):
model.fit(x_train, y_train)
acu_train = model.score(x_train, y_train)
acu_test = model.score(x_test, y_test)
y_pred = model.predict(x_test)
recall = recall_score(y_test, y_pred, average="macro")
return acu_train, acu_test, recall
def run_svc_model(modelist):
result = {"kernel": [],
"acu_train": [],
"acu_test": [],
"recall": []
}
for model in modelist:
acu_train, acu_test, recall = svc_model(model)
try:
result["kernel"].append(model.kernel)
except:
result["kernel"].append(None)
result["acu_train"].append(acu_train)
result["acu_test"].append(acu_test)
result["recall"].append(recall)
return pd.DataFrame(result)
run_svc_model(modelist())
对比的结果:


优化linear核函数的SVC的惩罚系数
惩罚系数(C=)越高,对错误分类的惩罚越大,模型训练时的准确率就会提高。但若惩罚系数过高,不仅增加了计算资源的消耗,还可能导致模型过拟合,泛化能力减弱。
def test_c():
result = {"C": [],
"acu_train": [],
"acu_test": [],
"recall": []
}
for c in range(10, 101, 10):
model = svm.SVC(kernel="linear", C=c, decision_function_shape="ovo")
acu_train, acu_test, recall = svc_model(model)
result["C"].append(c)
result["acu_train"].append(acu_train)
result["acu_test"].append(acu_test)
result["recall"].append(recall)
df = pd.DataFrame(result)
return df
test_c()
结果
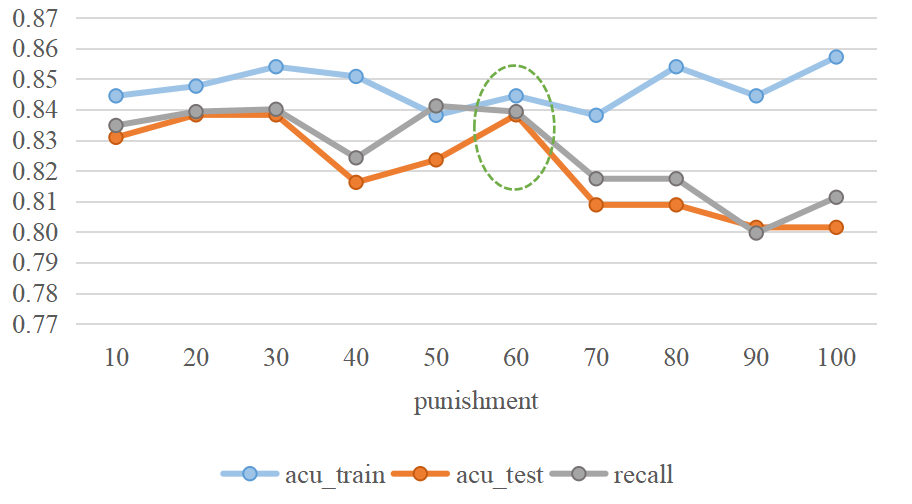
大概60的时候是最优的。
其他模型的优化
其他模型也可以通过调节其他参数优化,比如poly为核函数的SVC模型,可以调节多项式的次数进行优化:
def test_degree():
result = {"degree": [],
"acu_train": [],
"acu_test": [],
"recall": []
}
for d in range(1, 11, 1):
model = svm.SVC(kernel="poly", degree=d, decision_function_shape="ovo")
acu_train, acu_test, recall = svc_model(model)
result["degree"].append(d)
result["acu_train"].append(acu_train)
result["acu_test"].append(acu_test)
result["recall"].append(recall)
df = pd.DataFrame(result)
return df
test_degree()
结果(纵轴是测试集上的准确率)

一般是多项式的次数越高,准确率就越高。但是还是没有达到linear的80%。而且消耗计算资源。
Original: https://blog.csdn.net/Yvesx/article/details/111201301
Author: Yvesx
Title: sklearn支持向量机(SVM)多分类问题
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/667327/
转载文章受原作者版权保护。转载请注明原作者出处!