

🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 – 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】

🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
目录
预览 XGBoost
什么是机器学习?
数据整理
数据集 1 – 自行车租赁
访问数据
了解数据
.head()
.describe()
.info()
更正空值
查找空值的数量
显示空值
更正空值
删除非数字列
预测回归
预测自行车租赁
保存数据以备将来使用
声明预测变量和目标列
了解回归
访问 scikit-learn
静音警告
建模线性回归
XGBoost
XGB回归器
交叉验证
使用线性回归进行交叉验证
使用 XGBoost 进行交叉验证
预测分类
什么是分类?
数据集 2 – 人口普查
数据整理
数据加载
空值
非数值列
目标列和预测列
逻辑回归
交叉验证函数
XGBoost 分类器
概括
Bagging 和 Boosting
使用 scikit-learn 默认值的 XGBoost 模型在使用 pandas 预处理数据并构建标准回归和分类模型后打开本书。通过推进决策树(XGBoost 基础学习器)、随机森林(装袋)和梯度提升来比较分数和微调集成和基于树的超参数,探索了 XGBoost 背后的实用理论。
欢迎 阅读使用 XGBoost 和 Scikit-Learn 进行梯度提升的动手实践,这本书将教您 XGBoost 的基础、提示和技巧,这是用于从表格数据进行预测的最佳机器学习算法。
的重点;这本书就是 XGBoost,也称为 Extreme Gradient Boosting。XGBoost 的结构、功能和原始功能将在每一章中越来越详细地充实。这些章节展开讲述了一个令人难以置信的故事:XGBoost 的故事。在本书结束时,您将成为利用 XGBoost 从真实数据进行预测的专家。
在第一章中,XGBoost 在预览中进行了介绍。 它在机器学习回归和分类的更大背景下客串,为即将发生的事情奠定了基础。
本章重点关于为机器学习准备数据的过程,也称为 数据争论。除了构建机器学习模型,您还将学习使用高效的 Python代码加载数据、描述数据、处理空值、将数据转换为数值列、将数据拆分为训练集和测试集、构建机器学习模型以及实现 跨验证,以及将 线性回归和 逻辑回归模型与 XGBoost 进行比较。
本章介绍的概念和库在整本书中都会用到。
本章包含以下主题:
- 预览 XGBoost
- 整理数据
- 预测回归
- 预测分类
预览 XGBoost
机器学习1940 年代第一个神经网络获得了认可,随后在 1950 年代获得了第一个机器学习跳棋冠军。在沉寂了几十年之后,当 深蓝在 1990 年代击败世界象棋冠军加里·卡斯帕罗夫时,机器学习领域开始腾飞。随着计算能力的激增,1990 年代和 2000 年代初期产生了大量的学术论文,揭示了新机学习算法,例如 随机森林和 AdaBoost。
boosting 背后的总体思路是通过对错误进行迭代改进,将弱学习者转变为强学习者。 梯度提升背后的关键思想是使用梯度下降来最小化残差的误差。从标准机器学习算法到梯度提升,这一进化链是本书前四章的重点。
XGBoost 是 Extreme Gradient Boosting 的缩写。 _极限_部分是指推动计算的极限以实现准确性和速度的提高。XGBoost 的人气飙升很大程度上得益于其在 Kaggle 比赛中的空前成功。在 Kaggle 比赛中,参赛者构建机器学习模型,试图做出最好的预测并赢得丰厚的现金奖励。与其他型号相比,XGBoost 一直在竞争中脱颖而出。
了解 XGBoost 的细节需要了解梯度提升背景下的机器学习前景。为了描绘完整的画面,我们从机器学习的基础开始。
什么是机器学习?
机器学习是计算机从数据中学习的能力。2020 年,机器学习可以预测人类行为、推荐产品、识别面孔、超越扑克专业人士、发现系外行星、识别疾病、驾驶自动驾驶汽车、个性化互联网以及与人类直接交流。机器学习正在引领人工智能革命,影响着几乎所有大公司的底线。
在实践中,机器学习意味着实施计算机算法,其权重会在新数据出现时进行调整。机器学习算法从数据集中学习,以预测物种分类、股票市场、公司利润、人类决策、亚原子粒子、最佳交通路线和更多的。
机器学习是将大数据转化为准确、可操作的预测的最佳工具。然而,机器学习并不是凭空发生的。机器学习需要行和列的数据。
数据整理
数据整理是一个综合性术语,涵盖机器学习开始之前数据预处理的各个阶段。数据加载、数据清理、数据分析和数据操作都包含在数据整理的范围内。
第一章详细介绍了数据整理。这些示例旨在涵盖可由Python 处理数据分析的特殊库 pandas快速处理的标准数据争论挑战。虽然不需要熊猫的经验,但 熊猫 的基本知识将是有益的。所有代码都进行了解释,以便 Pandas 的新读者 可以跟进。
数据集 1 – 自行车租赁
自行车租金dataset 是我们的第一个数据集。数据源是 UCI 机器学习存储库 ( UCI Machine Learning Repository ),这是一个世界著名的免费向公众开放的数据仓库。我们的自行车租赁数据集已从原始数据集 ( UCI Machine Learning Repository: Bike Sharing Dataset Data Set ) 中调整,添加了空值,以便您可以练习纠正它们。
访问数据
数据的第一步争吵就是访问数据。这可以通过以下步骤来实现:

小费 如果您在打开 Jupyter Notebook 时遇到困难,请参阅 Jupyter 的官方故障排除指南: What to do when things go wrong — Jupyter Notebook 6.4.12 documentation.
- 在 Jupyter Notebook 的第一个单元格中输入以下代码:
import pandas as pd
按 Shift + _Enter_运行单元格。现在您可以在编写 pd时访问 pandas库。
4. 使用 pd.read_csv加载数据。加载数据需要 读取方法。 read方法将数据存储为 DataFrame,这是一个用于查看、分析和操作数据的pandas对象 。加载数据时,将文件名放在引号中,然后运行单元格:
df_bikes = pd.read_csv('bike_rentals.csv')
如果您的数据文件与 Jupyter Notebook 位于不同的位置,则必须提供文件目录,例如 Downloads/bike_rental.csv。 现在数据已正确存储在名为 df_bikes的 DataFrame 中。
小费 制表符完成 :何时在 Jupyter Notebooks 中编码,输入几个字符后,按 Tab 按钮。对于 CSV 文件,您应该会看到文件名出现。用光标突出显示名称并按 Enter 。如果文件名是唯一可用的选项,您可以按 Enter 。制表符补全将使您的编码体验更快、更可靠。
5. 使用 .head()显示数据。最后一步是查看数据以确保已正确加载。 .head() 是一个 DataFrame 方法,用于显示 DataFrame 的前五行。您可以将任何正整数放在括号中以查看任意数量的行。输入以下代码并按 Shift + Enter:
df_bikes.head()
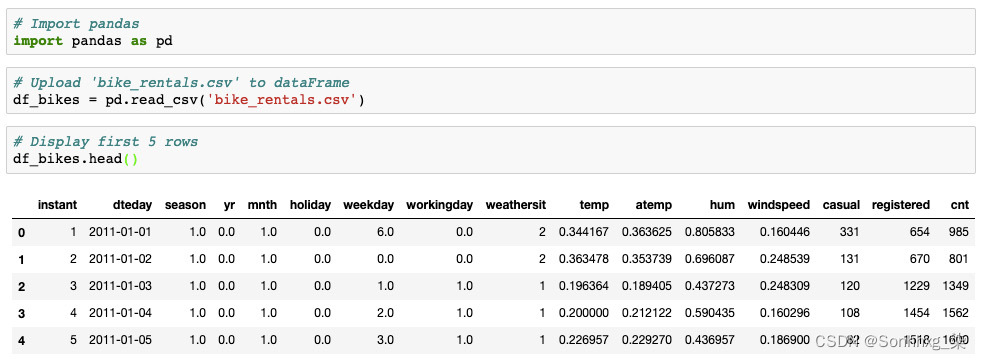
图 1.3 -bike_rental.csv 输出
现在我们有了获取数据,我们来看看了解数据的三种方法。
了解数据
既然数据已经加载,是时候理解数据了。了解数据对于在未来做出明智的决策至关重要。以下是理解数据的三种好方法。
.head()
你有已经见过 .head(),一种广泛使用的解释列名和数字的方法。正如前面的输出所示, dteday是一个日期,而 instant是一个有序索引。
.describe()
数字可以使用 .describe()查看统计信息,如下所示:
df_bikes.describe()
这是预期的输出:

图 1.4 – .describe() 输出
您可能需要向右滚动才能查看所有列。
比较平均值和中位数 (50%) 可以看出偏度。如您所见, 均值和 中位数彼此接近,因此数据大致对称。 最大值和 最小值 ;还显示了每列的值以及四分位数和标准差 ( std )。
.info()
另一个伟大的方法是 .info(),它显示有关列和行的一般信息:
df_bikes.info()
这是预期的输出:
<class 'pandas.core.frame.dataframe'>
RangeIndex: 731 entries, 0 to 730
Data columns (total 16 columns):
Column Non-Null Count Dtype
0 age 32561 non-null int64
1 workclass 32561 non-null object
2 fnlwgt 32561 non-null int64
3 education 32561 non-null object
4 education-num 32561 non-null int64
5 marital-status 32561 non-null object
6 occupation 32561 non-null object
7 relationship 32561 non-null object
8 race 32561 non-null object
9 sex 32561 non-null object
10 capital-gain 32561 non-null int64
11 capital-loss 32561 non-null int64
12 hours-per-week 32561 non-null int64
13 native-country 32561 non-null object
14 income 32561 non-null object
dtypes: int64(6), object(9)
memory usage: 3.7+ MB</class>
由于所有列都有相同数量的非空行,我们可以推断没有空值。
非数值列
dtype对象的所有列必须是转化成数值列。 pandas get_dummies方法 获取 每列的非数字唯一值并将它们转换为自己的列,其中 1表示存在, 0表示不存在。例如,如果名为”Book Types”的 DataFrame 的列值为”hardback”、”paperback”或”ebook”, 则 pd.get_dummies 将创建三个名为”hardback”、”paperback”和”ebook”的新列替换”书籍类型”列。
这是一个”书籍类型”数据框:

图 1.15 – 一个”书本类型”数据框
这是 pd.get_dummies 之后的相同 DataFrame:

图 1.16 – 新的 DataFrame
pd.get_dummies 将创建许多新列,因此值得检查是否可以消除任何列。 对df_census数据的快速查看会发现一个 “教育”列和一个 education_num列。 Education_num列是 ‘education’的数值转换。由于信息相同,可以删除 “教育”一栏:
df_census = df_census.drop(['education'], axis=1)
现在使用 pd.get_dummies 将非数字列转换为数字列:
df_census = pd.get_dummies(df_census)
df_census.head()
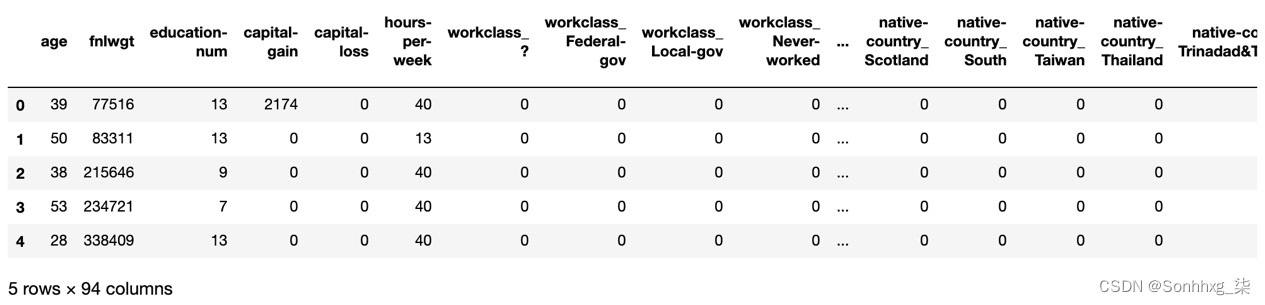
图 1.17 – pd.get_dummies – 非数字到数字列
如您所见,新列是使用引用原始列的 column_value语法创建的。例如, native-country是原始列,Taiwan 是众多值之一。如果此人来自台湾,则新的 native-country_Taiwan列的值为 1 ,否则为 0。
小费
使用 pd.get_dummies 可能会增加内存使用量,这可以使用相关 DataFrame 上的 .info() 方法并检查最后一行来验证。 稀疏矩阵 可用于节省内存,其中仅存储值 1 而不存储值 0 。 有关稀疏矩阵的更多信息,请参阅第 10 章 ,XGBoost 模型部署 ,或访问SciPy API — SciPy v1.9.1 Manual 上的 SciPy 官方文档。
目标列和预测列
由于所有列是数字,没有无效的值,是时候将数据拆分为目标列和预测列。
目标列是是否有人赚了 50K。在 pd.get_dummies之后,两列 df_census[‘income_
df_census = df_census.drop('income_ <=50k', axis="1)</code"></=50k',>
现在将数据拆分为 X(预测列)和 y(目标列)。请注意, -1用于索引,因为最后一列是目标列:
X = df_census.iloc[:,:-1]y = df_census.iloc[:,-1]
是时候构建机器学习分类器了!
逻辑回归
逻辑回归是最基本的分类算法。在数学上,逻辑回归的工作方式类似于线性回归。对于每一列,逻辑回归会找到一个适当的权重或系数,以最大限度地提高模型的准确性。主要区别在于,不是像线性回归那样对每个项求和,而是逻辑回归回归使用 sigmoid 函数。
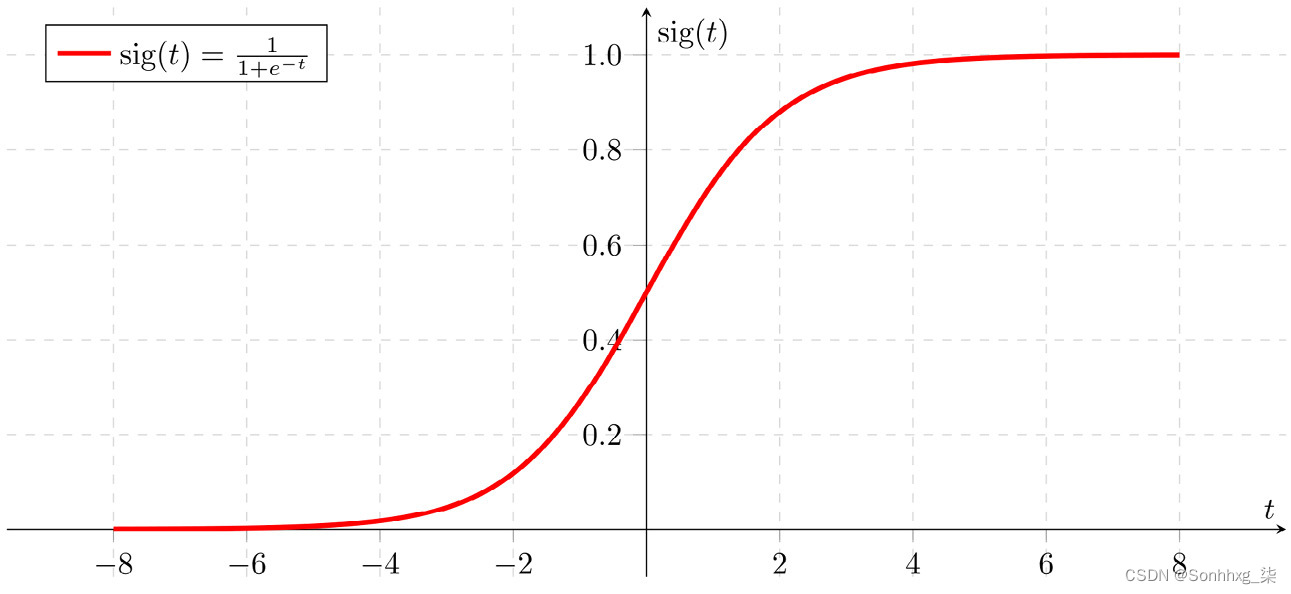
图 1.18 – Sigmoid 函数图
sigmoid 通常用于分类。所有大于 0.5 的值都匹配为 1,所有小于 0.5 的值都匹配为 0。
使用 scikit-learn 实现逻辑回归与实现线性回归几乎相同回归。主要区别在于预测变量列应适合类别,而误差应与准确性有关。作为奖励,默认情况下错误是在准确性方面,因此不需要明确的评分参数。
您可以按如下方式导入逻辑回归:
from sklearn.linear_model import LogisticRegression
交叉验证函数
让我们使用交叉验证在逻辑回归上预测某人是否超过 50K。
让我们构建一个交叉验证分类函数,而不是复制和粘贴,该函数将机器学习算法作为输入,并使用 cross_val_score将准确度得分作为输出:
def cross_val(classifier, num_splits=10):
model = classifier
scores = cross_val_score(model, X, y, cv=num_splits)
print('Accuracy:', np.round(scores, 2))
print('Accuracy mean: %0.2f' % (scores.mean()))
现在用逻辑回归调用函数:
cross_val(LogisticRegression())
输出如下:
Accuracy: [0.8 0.8 0.79 0.8 0.79 0.81 0.79 0.79 0.8 0.8 ]
Accuracy mean: 0.80
80% 的准确率是开箱即用的。
让我们来看看XGBoost 是否可以做得更好。
小费
每当您发现自己在复制和粘贴代码时,请寻找更好的方法!计算机科学的目标之一是避免重复。从长远来看,编写自己的数据分析和机器学习函数将使您的生活更轻松,工作效率更高。
XGBoost 分类器
XGBoost 有一个回归器和分类器。要使用分类器,请导入以下算法:
from xgboost import XGBClassifier
现在在 cross_val函数中运行分类器并添加一个重要内容。由于有 94 列,并且 XGBoost 是一种集成方法,这意味着它每次运行都会组合许多模型,每个模型都包含 10 个拆分,因此我们将 n_estimators(模型的数量)限制为 5 个。通常,XGBoost 非常快。事实上,它以最快的提升集成方法而闻名,我们将在本书中查看这一声誉!然而,对于我们最初的目的, 5 个估计量虽然不如默认的 100 个稳健,但就足够了。选择 n_estimators的细节将是 第 4 章的重点 ,从梯度提升到 XGBoost:
cross_val(XGBClassifier(n_estimators=5))
输出如下:
Accuracy: [0.85 0.86 0.87 0.85 0.86 0.86 0.86 0.87 0.86 0.86]
Accuracy mean: 0.86
如您所见,XGBoost得分高于开箱即用的逻辑回归。
概括
您的 XGBoost 之旅正式开始! 您从学习数据整理和pandas的基础知识开始本章,这是所有机器学习从业者的基本技能,重点是纠正空值。接下来,您通过比较线性回归和 XGBoost,了解了如何在 scikit-learn 中构建机器学习模型。然后,您准备了一个用于分类的数据集,并将逻辑回归与 XGBoost 进行了比较。在这两种情况下,XGBoost 都是明显的赢家。
恭喜您构建了您的第一个 XGBoost 模型!您开始使用 pandas、NumPy 和 scikit-learn 库进行数据整理和机器学习已经完成。
在第 2 章 “深度决策树”中,您将通过构建决策树、XGBoost 机器学习模型的基础学习器和微调超参数来提高您的机器学习技能以改善结果。
Original: https://blog.csdn.net/sikh_0529/article/details/127101230
Author: Sonhhxg_柒
Title: 【XGBoost】第 1 章:机器学习前景
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/622935/
转载文章受原作者版权保护。转载请注明原作者出处!