

【SCRDet++论文解读】 模型部分
SCR Det++ 的模型结构是基于 Faster R-CNN 设计的,包括4部分,如下图所示:
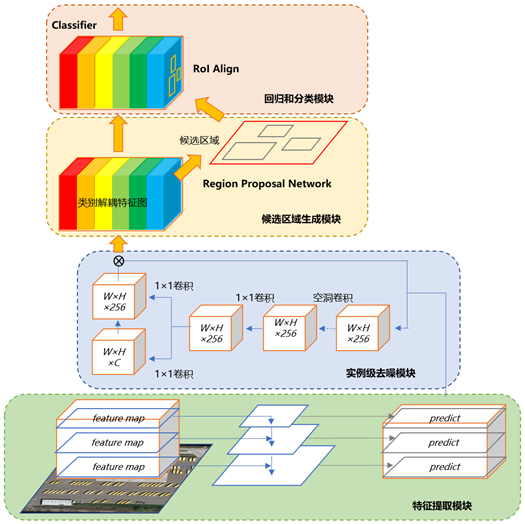

- 用于进行 特征提取的基础网络(basic embodiment for feature extraction)。以 ResNet为基础,添加了 特征金字塔(FPN) 以进行多尺度特征融合。
- 用于消除实例噪声的 实例级去噪网络(instance-level denoising module for suppressing instance noise)
- 用于生成五参数定义的旋转候选框的 候选区域生成网络(RPN)。
- 用于产生 类别分数和 预测边界框的部分(the ‘class+box’ branch for predicting classification score and bounding box position)
论文中的4部分分别是:特征提取、图像级去噪、实例级去噪以及回归分类,这里划分成这4部分的原因有3个:
- 为了更好的与 Faster R-CNN 模型结构进行对比;
- 因为图像级去噪的效果可以由实例级去噪达到,所以图像级去噪模块可省,就不需要体现在模型主要结构上;
- 代码中没有图像级去噪的部分。
; 一、实例去噪
模块结构如下图所示:
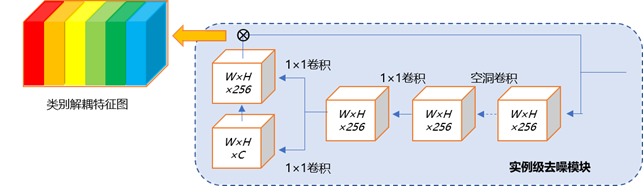
对 FPN的每一层,进行如下步骤:
- 首先采用 N个空洞卷积和一个 1×1卷积扩大感受野
- 通过两个并行的 1×1 卷积层得到两个输出, 其中一个输出是像素级标注,用以引导 另一个输出生成 用于去噪的权重特征图(denosing feature map)
- 将用于去噪的权重特征图与原特征图通过 矩阵的点运算进行融合,得到根据物体类别进行解耦后的 层次特征图
代码:
def enrich_semantics_supervised(net, channels, num_layer, scope):
with tf.variable_scope(scope):
for _ in range(num_layer-1):
net = slim.conv2d(net, num_outputs=channels, kernel_size=[3, 3], stride=1, rate=2, padding="SAME")
net = slim.conv2d(net, num_outputs=channels, kernel_size=[3, 3], stride=1, rate=4, padding="SAME")
net = slim.conv2d(net, num_outputs=channels, kernel_size=[1, 1], stride=1, padding="SAME")
return net
def generate_mask(net, num_layer, level_name):
G = enrich_semantics_supervised(net=net,
num_layer=num_layer,
channels=256, scope="enrich_%s" % level_name)
last_dim = 2 if cfgs.BINARY_MASK else cfgs.CLASS_NUM + 1
mask = slim.conv2d(G, num_outputs=last_dim, kernel_size=[1, 1], stride=1, padding="SAME",
activation_fn=None,
scope='gmask_%s' % level_name)
act_fn = tf.nn.sigmoid if cfgs.SIGMOID_ON_DOT else None
dot_layer = slim.conv2d(G, num_outputs=256, kernel_size=[1, 1], stride=1, padding="SAME",
activation_fn=act_fn,
scope='gdot_%s' % level_name)
return G, mask, dot_layer
mask_list = []
with tf.variable_scope("enrich_semantics"):
with slim.arg_scope([slim.conv2d], weights_regularizer=slim.l2_regularizer(cfgs.WEIGHT_DECAY),
normalizer_fn=None):
for i, l_name in enumerate(cfgs.GENERATE_MASK_LIST):
G, mask, dot_layer = generate_mask(net=pyramid_dict[l_name],
num_layer=cfgs.ADDITION_LAYERS[i],
level_name=l_name)
add_heatmap(G, name="MASK/G_%s" % l_name)
add_heatmap(mask, name="MASK/mask_%s" % l_name)
if cfgs.MASK_ACT_FET:
pyramid_dict[l_name] = pyramid_dict[l_name] * dot_layer
mask_list.append(mask)
二、候选区域生成网络
候选区域生成网络(RPN)结构如下图:
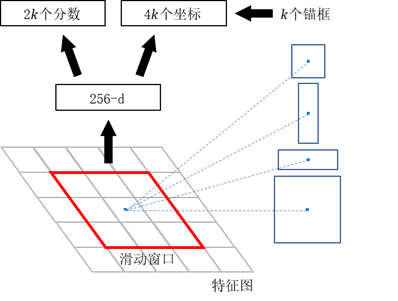
大体工作流程为: 针对一张特征图上的每个像素点,生成 k k k 个不同scale和ratio的锚框,然后将这些锚框堆叠成 256 − d 256-d 2 5 6 −d 的向量,接下来针对每个锚框,RPN完成两项任务:
- 判断锚框中是否有目标。仅需判定该锚框中是否含有需要检测的目标,因此进行简单的 二分类(正样本或负样本),针对k k k 个锚框生成2 k 2k 2 k 个分数
- 对锚框进行边界回归。针对k k k 个锚框产生4 k 4k 4 k 个坐标
之后,还需要进行一些后续操作:
- 将候选区域 映射回原图,并剔除超出原图边界的候选区域;
- 将”分数”从大到小进行 排序,选出前2000个候选区域;
- 采用 NMS 移除尺度过小以及所含目标相同的候选区域
最后,生成最终的候选区域。
边界框回归(Bounding Box Regression):
在这个过程中,RPN生成的 4 k 4k 4 k 个坐标 不是预测边界框的坐标, 而是变换参数(包括平移参数d x dx d x,d y dy d y和伸缩参数d w dw d w,d h dh d h)
“变换参数”是一种”映射关系”,能使得每个锚框通过这种映射关系都能够得到一个和真实边界框更接近的区域
详见:【边框回归(Bounding Box Regression)详解】
with tf.variable_scope('build_rpn', regularizer=slim.l2_regularizer(cfgs.WEIGHT_DECAY)):
fpn_cls_score = []
fpn_box_pred = []
for level_name, p in zip(cfgs.LEVLES, P_list):
if cfgs.SHARE_HEADS:
reuse_flag = None if level_name == cfgs.LEVLES[0] else True
scope_list = ['rpn_conv/3x3', 'rpn_cls_score', 'rpn_bbox_pred']
else:
reuse_flag = None
scope_list = ['rpn_conv/3x3_%s' % level_name, 'rpn_cls_score_%s' % level_name,
'rpn_bbox_pred_%s' % level_name]
rpn_conv3x3 = slim.conv2d(p, 512, [3, 3],
trainable=self.is_training, weights_initializer=cfgs.INITIALIZER,
activation_fn=tf.nn.relu, padding="SAME",
scope=scope_list[0],
reuse=reuse_flag)
rpn_cls_score = slim.conv2d(rpn_conv3x3, self.num_anchors_per_location * 2, [1, 1], stride=1,
trainable=self.is_training, weights_initializer=cfgs.INITIALIZER,
activation_fn=None, padding="VALID",
scope=scope_list[1],
reuse=reuse_flag)
rpn_box_pred = slim.conv2d(rpn_conv3x3, self.num_anchors_per_location * 4, [1, 1], stride=1,
trainable=self.is_training, weights_initializer=cfgs.BBOX_INITIALIZER,
activation_fn=None, padding="VALID",
scope=scope_list[2],
reuse=reuse_flag)
rpn_cls_score = tf.reshape(rpn_cls_score, [-1, 2])
rpn_box_pred = tf.reshape(rpn_box_pred, [-1, 4])
fpn_cls_score.append(rpn_cls_score)
fpn_box_pred.append(rpn_box_pred)
fpn_cls_score = tf.concat(fpn_cls_score, axis=0, name='fpn_cls_score')
fpn_cls_prob = slim.softmax(fpn_cls_score, scope='fpn_cls_prob')
fpn_box_pred = tf.concat(fpn_box_pred, axis=0, name='fpn_box_pred')
三、回归分类
def roi_pooling(self, feature_maps, rois, img_shape, scope):
'''
Here use roi warping as roi_pooling
:param featuremaps_dict: feature map to crop
:param rois: shape is [-1, 4]. [x1, y1, x2, y2]
:return:
'''
with tf.variable_scope('ROI_Warping_' + scope):
img_h, img_w = tf.cast(img_shape[1], tf.float32), tf.cast(img_shape[2], tf.float32)
N = tf.shape(rois)[0]
x1, y1, x2, y2 = tf.unstack(rois, axis=1)
normalized_x1 = x1 / img_w
normalized_x2 = x2 / img_w
normalized_y1 = y1 / img_h
normalized_y2 = y2 / img_h
normalized_rois = tf.transpose(
tf.stack([normalized_y1, normalized_x1, normalized_y2, normalized_x2]), name='get_normalized_rois')
normalized_rois = tf.stop_gradient(normalized_rois)
cropped_roi_features = tf.image.crop_and_resize(feature_maps, normalized_rois,
box_ind=tf.zeros(shape=[N, ],
dtype=tf.int32),
crop_size=[cfgs.ROI_SIZE, cfgs.ROI_SIZE],
name='CROP_AND_RESIZE')
roi_features = slim.max_pool2d(cropped_roi_features,
[cfgs.ROI_POOL_KERNEL_SIZE, cfgs.ROI_POOL_KERNEL_SIZE],
stride=cfgs.ROI_POOL_KERNEL_SIZE)
return roi_features
Original: https://blog.csdn.net/dear_jing/article/details/115285997
Author: dear_jing
Title: 【SCRDet++论文解读】 模型部分:特征提取 ResNet/FPN + 实例去噪 + 候选区域生成 RPN + 回归分类 RoI Warping
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/666775/
转载文章受原作者版权保护。转载请注明原作者出处!