

一、classification分类
1.介绍分类
- 分类(classification),即找一个函数判断输入数据所属的类别,可以是二类别问题(是/不是),也可以是多类别问题(在多个类别中判断输入数据具体属于哪一个类别)。
- 同回归问题(regression)相比,分类问题的输出不再是连续值,而是离散值,用来指定其属于哪个类别。
- 分类问题在现实中应用非常广泛,比如医疗诊断,手写数字识别,人脸识别,语音识别等。


; 2.Example Application
输入数值化:
对于宝可梦的分类问题来说,我们需要解决的第一个问题就是,怎么把某一只宝可梦当做function的input?

比如用一组数字表示它有多强(total strong)、它的生命值(HP)、它的攻击力(Attack)、它的防御力(Defense)、它的特殊攻击力(Special Attack)、它的特殊攻击的防御力(Special defend)、它的速度(Speed)。
2. 那我们又该如何去classifiction分类呢?
我们能不能把分类问题当成回归问题去解决?

首先以binary classification(二元分类)为例,我们在Training时让输入为class 1的输出为1,输入为class 2的输出为-1;那么在testing的时候,regression output是一个数值,它大于0接近1则说明它是class 1,它小于0接近-1则说明它是class 2。
这样做会出现的问题:
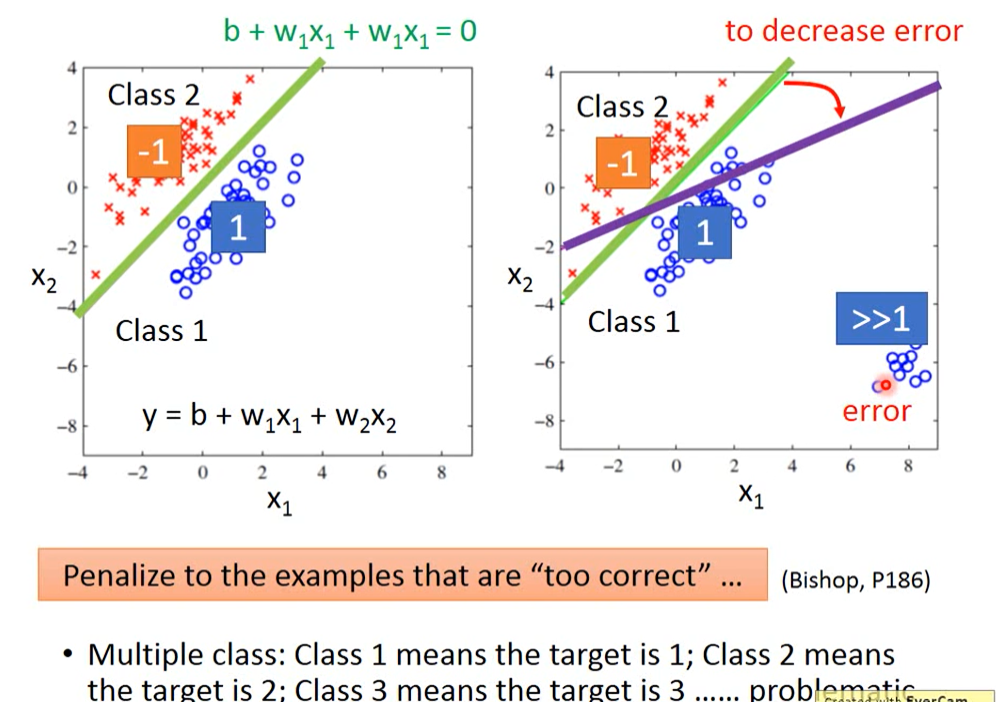
1.就比如此时,右侧class1中右下角的这些点,如果仍然采用绿色那条线所代表的函数进行预测,这些新加入进来的点的误差将特别的大,为了缓解由此带来的误差,绿色的线将往右下角偏移,以此减少误差。
2.Regression的output是连续性质的数值,而classification要求的output是离散性质的点,我们很难找到一个Regression的function使大部分样本点的output都集中在某几个离散的点附近因此,Regression定义model好坏的定义方式对classification来说是不适用的。
总结:regression会惩罚太正确的样本,得到不好的function。
; 3. Ideal Alternatives
首先引入离散函数g(x):
g(x)>0,output= class 1. else,output=class 2
同时重新定义了Loss function:
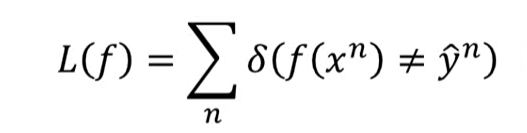
这个LOSS的意思,即是这个model在所有的training data上predict预测错误的次数,也就是说分类错误的次数越少,这个function表现得就越好。
又因为这个loss function没有办法微分,是无法用gradient descent的方法去解的。
当然有Perceptron、SVM这些方法可以用,但这里先用另外一个solution来解决这个问题。
4.Solution:Generative model (生成概率模型)
生成概率模型其实是先假设数据的概率分布(正态、伯努利、泊松),然后用概率公式去计算x所属于的类型p(C1∣x)。
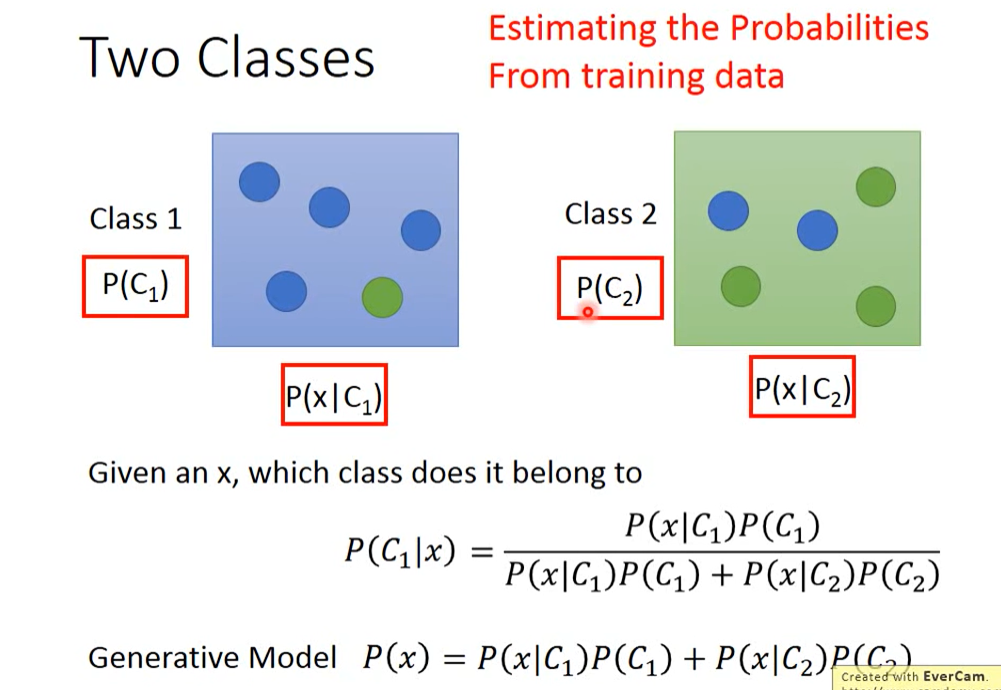
上述为引用贝叶斯公式;
实验设举例子:

P(C1)和P(C2)这两个概率,被称为Prior,计算这两个值还是比较简单的。在Training data里面,有79只水系宝可梦,61只一般系宝可梦,那么P(C1)= 79 / (79 + 61)= 0.56,P(C2)= 61/ (79 + 61)= 0.44,
现在的问题是,怎么得到P(x|C1)和P(x|C2)的值呢?
怎么得到P(x|C1)和P(x|C2)的值呢?假设我们的x是一只新来的海龟,它显然是水系的,但是在我们79只水系的宝可梦training data里面根本就没有海龟,所以挑一只海龟出来的可能性根本就是0啊!所以该怎么办呢?
其实每一只宝可梦都是用一组特征值组成的 向量来表示的,在这个 vector里一共有七种不同的feature,为了方便可视化,这里先只考虑 Defense和SP Defence这两种feature
下图只是采样了79个点之后得到的分布,但是从 高斯分布里采样出海龟这个点的几率并不是0,那从这79个已有的点,怎么找到那个 Gaussian distribution函数呢?

; Gaussian Distribution (正态分布/高斯分布)
首先介绍一下高斯函数,这里表示 均值μ,表示 协方差 Σ,两者 都是矩阵matrix,输入vector x,得到输出的是一个sample 出x 的概率密度;
下图中可以看出,同样的 Σ,不同的μ,概率分布最高点的地方是不一样的。
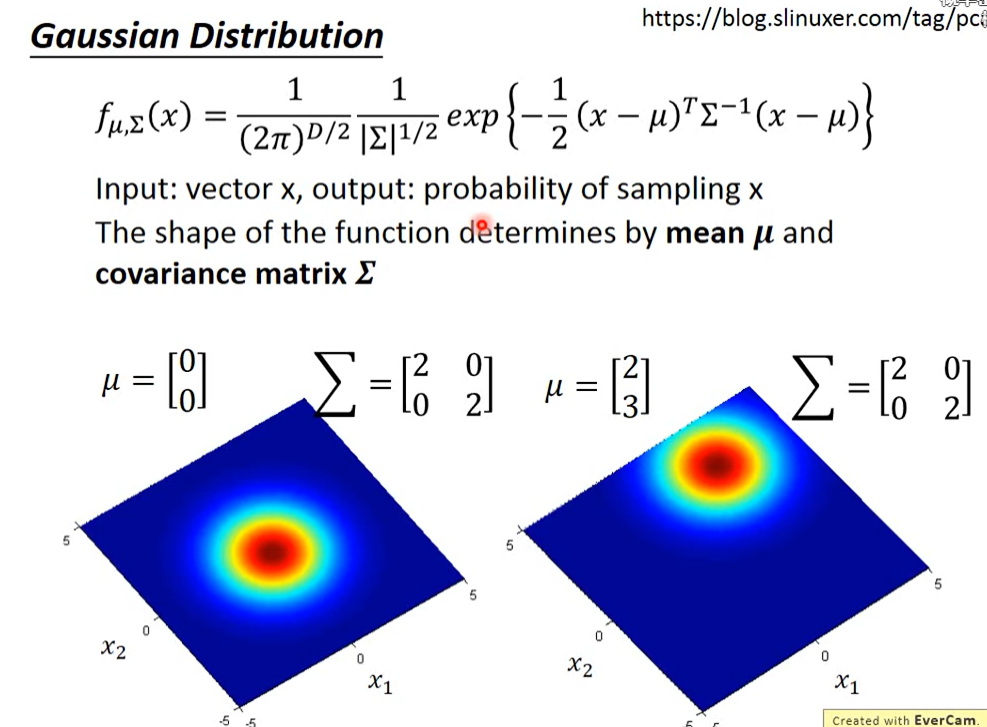
如果是同样的μ,不同的 Σ,概率分布最高点的地方是一样的,但是分布的密集程度是不一样的。
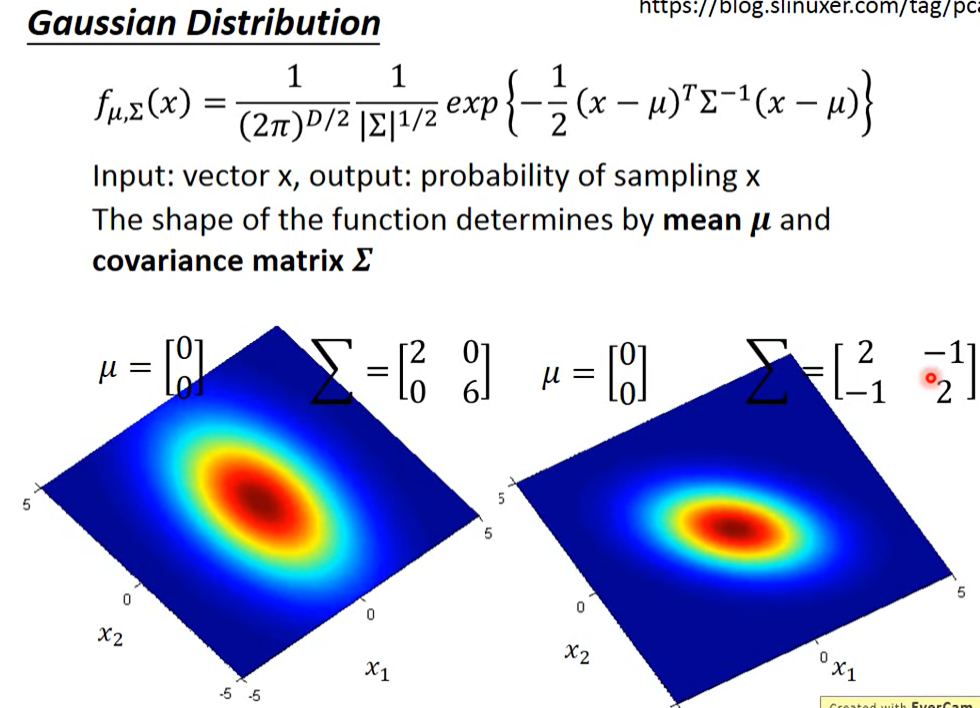
那接下来的问题就是怎么去找出这个Gaussian 函数,只需要我们去估测出这个Gaussian的均值μ和协方差 Σ
估测均值μ和协方差的方法就是 极大似然估计法(Maximum Likelihood)
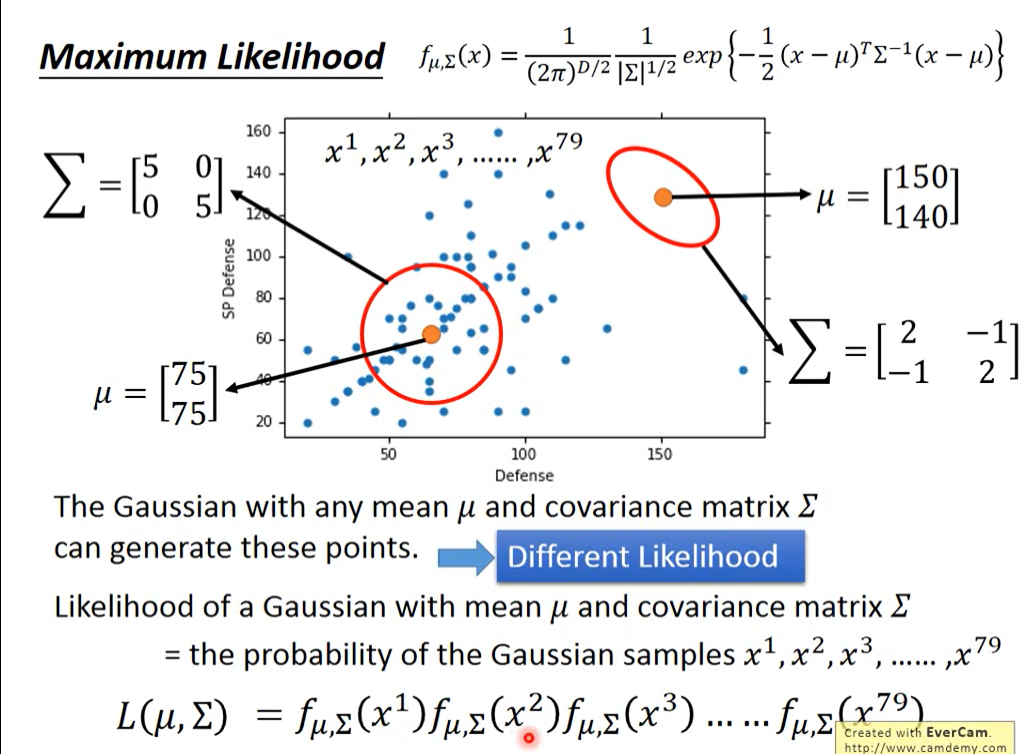
实际上任意一组μ和对应Σ的高斯函数(μ表示该Gaussian的中心点,Σ表示该Gaussian的分散程度)都有可能sample出跟当前分布一致的样本点,
如上图中的两个红色圆圈所代表的高斯函数,但肯定存在着发生概率最大的哪一个Gaussian函数,而这个函数就是我们要找的。
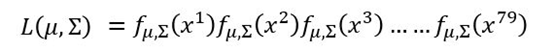
如下图所示:

现在就有了P(C1),P(x|C1),P(C2),P(x|C2)这四个值,可以开始真的分类了
Now we can do classification

那最后实验举例结果如何呢?
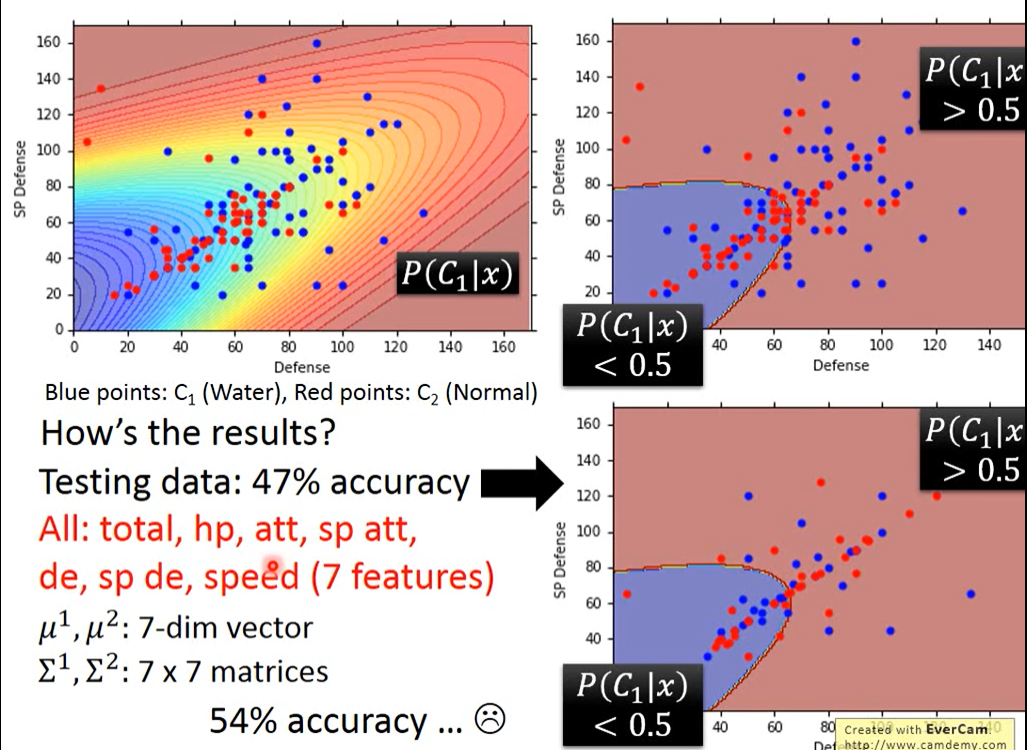
training训练集上得出:红色区域>0.5 水系概率比较大,但是在testing测试集上,效果表现准确率不高,结果是不大好的!
Modifying Model
首先呢,其实之前使用的model是不常见的,你是不会经常看到给每一个Gaussian都有自己的mean和covariance,比如我们的class 1用的是mean1和covariance1,class 2用的是mean2和covariance2;
解决方法常用:不同的class共用同一个模型covariance matrix(协方差矩阵)
由于covariance matrix(协方差矩阵)中的变量与输入输入样本数量的平方呈正比,故covariance matrix中的变量在样本数量较多时快速增长,造成overfitting,故使用同一组covariance matrix(协方差矩阵),以减少parameters。
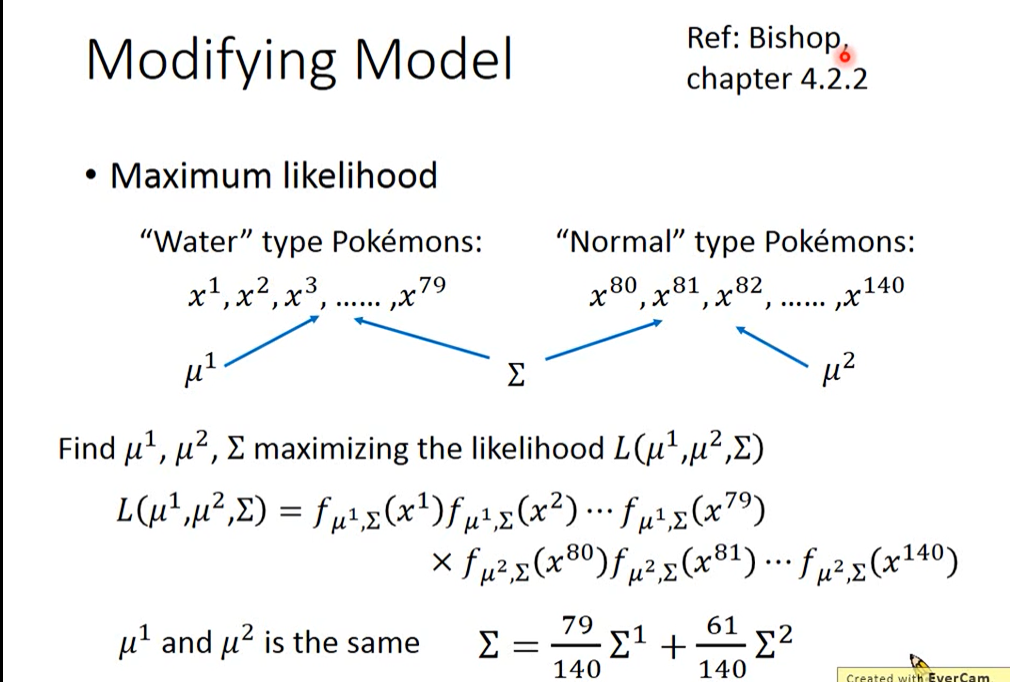
将μ1和μ2,以及共同的Σ,一起去合成一个极大似然函数,此时可以发现,得到的μ1和μ2还是各自的均值,而则是原先两个Σ1和Σ2的加权值。
结果分类结果变好了,同时boundary(分界线) 变为线性的;如下图:
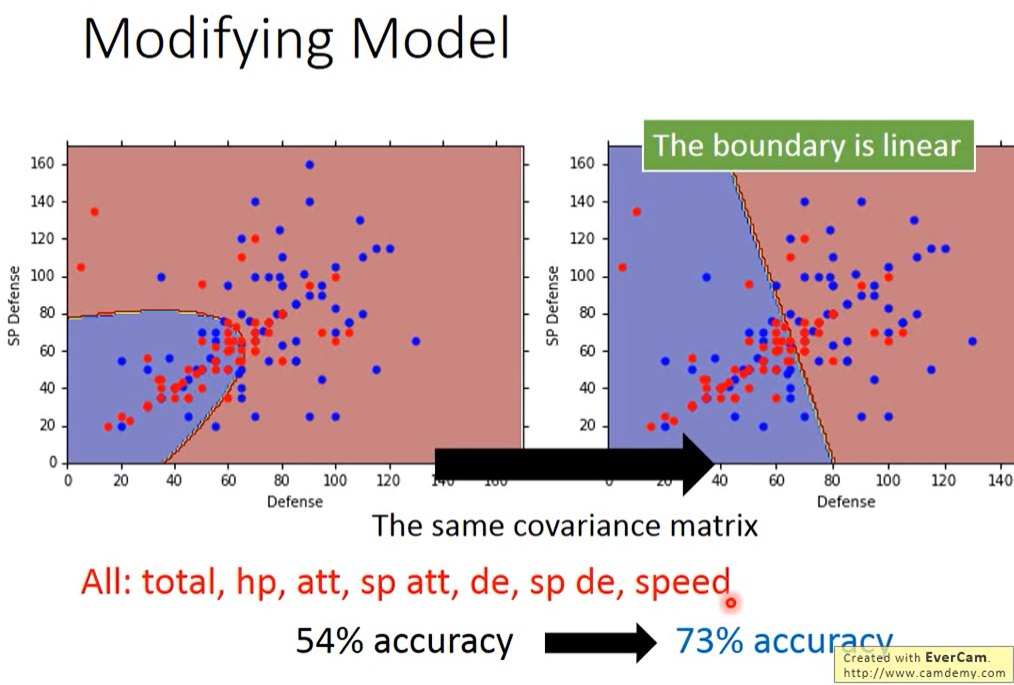
从图中可见:如果我们考虑所有的feature,并共用covariance(协方差矩阵)的话,原来的54%的正确率就会变成73%,显然是有分对东西的,但是为什么会做到这样子,我们是很难分析的,因为这是在高维空间中发生的事情,我们很难知道boundary到底是怎么切的,但这就是machine learning它fancy的地方,人显然是没有办法知道怎么做,但是machine可以帮我们做出来。
Three Steps of classification
总结——分类问题的三步骤:
1.定义模型集合
样本x属于类别1的概率:

2.定义损失函数(LOSS)来评价模型好坏:
假设高斯分布,利用已有的数据,求得μ \mu μ,Σ \Sigma Σ。最大化评价参数好坏的指标,即极大似然估计L ( μ , Σ ) L(\mu,\Sigma)L (μ,Σ);
3.找到最好的模型:

实际上,(有公式如下)最佳参数就是每个类别中,所有样本点的均值和协方差。比如,类别1的最佳均值与协方差:

- 注1:均值μ是每个类别单独求出的。
- 注2:协方差Σ \Sigma Σ先每个类别单独求出,然后共享的协方差为所有协方差的加权平均值。
数学警告
Original: https://blog.csdn.net/weixin_44790306/article/details/116049596
Author: HSR CatcousCherishes
Title: 2020李宏毅机器学习笔记——4.classification(分类)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/666591/
转载文章受原作者版权保护。转载请注明原作者出处!