

前言
Give me a user manual, and I’m happy for hours.
— Lennon Parham
When all else fails, read the instructions.
— Anonymous
从这两句话可以看出,对于任何一件事情,如果有一个用户手册或者是用户指南对于我们做任何事情都会有很大帮助,这篇文章我们就带大家了解一下使用自然语言处理(NLP)技术来利用用户手册帮助我们进行数据库调参的最新论文和进展。
1 问题背景和定义
数据库调参是数据库中非常重要且困难的一件事,主要原因是数据库的参数非常多且繁杂,并且这些数据库参数之间也并不是完全正交的。因此,数据库调参往往需要很强的数据库专业知识。为了解决这样的问题,之前的研究工作提出了一些使用强化学习(RL)来解决数据库调参问题的框架[1,2,3],但是这样的框架需要数百轮的迭代才能使调参模型收敛和可用。因此,本文的作者提出了希望能够用可以自动获取的信息(使用自然语言处理技术从用户手册中获取)来取代原有强化学习框架中的输入的目标[4]。
具体来说,原有的数据库调参问题可以表示为一个三元组〈b,P,V〉,其中b表示为一组查询组成的工作负载以及对应的需要优化的性能指标(比如时延和吞吐);P表示需要调整的参数;V表示参数的具体值使得系统能够达到最优的性能指标。而在新的自然语言处理增强的数据库调参中,问题被表示为〈b,T,S〉,其中b的表示和之前一样;T表示一组用于获取调参提示(hints)的文本文档;S表示为一个用于表示系统参数的数字表示的向量(包括内存大小,CPU核心数等)。在新的问题定义中,不再需要用户自己指定需要调整的参数和具体的数值,而是直接从工作手册中获取到提示,再将提示转换为数据库系统需要调整的参数和对应的数值。
在新的问题定义下,有以下几个任务需要解决,包括1. 在工作手册中发现提示;2. 提取发现出来的提示;3. 调整这些提示的数值 4. 解决提示之间可能产生的冲突。
需要注意的是,本文只考虑整型、布尔型和数值型的参数,其他类型的参数不做考虑。
系统框架概述
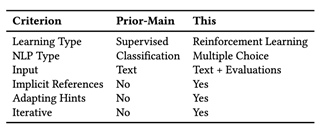
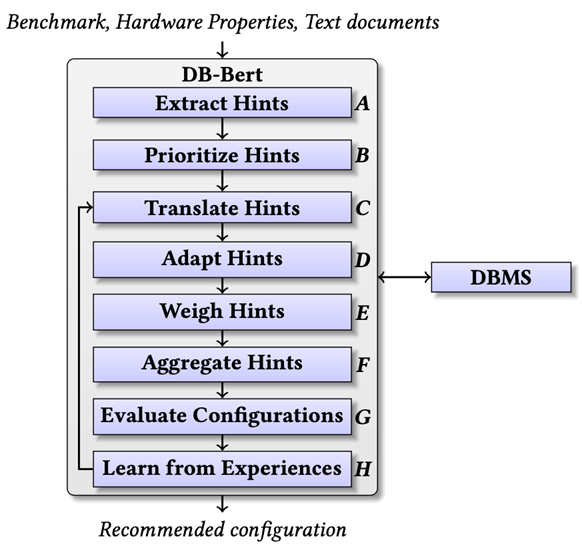
该自然语言处理增强的数据库调参系统框架的八个模块(A-H)主要如下图所示,包含了解决我们在第一节中提到的四个主要需要解决的任务的模块,同时还有一些在设计上更加细节的模块。简单来说,系统的整体运行流程如下:首先,对输入的文本进行提示的发现和提取,根据这些提示出现的频次进行优先度排序;然后,将有优先次序的提示们翻译成数据库系统中对应的参数及数值,同时解决提示之间可能产生的冲突,以及对表达相似意思的提示进行聚类;最后将这些提示重新组合成数据库系统可以识别的一组参数和数值进行评估,将评估结果反馈给上述几个步骤(C-F)进行迭代,最终可以产生能够给数据库系统使用的提升系统性能的参数,完成数据库系统调参优化的过程。这个整体框架,相比于作者之前的工作[5]有了较大的修改和扩充,两种自然语言处理增强的数据库调参系统的对比如下表所示:

关键技术
首先,在提取提示方面,相比于之前的工作,本文不仅可以根据关键字匹配提取到显式的提示和数值,而且能可以提取出隐式的提示。具体方法为,将参数使用BERT进行编码,去匹配文本中的余弦相似度,如果能够在文本语意的角度匹配上某个提取出来的参数并且有对应的数值,就认为该文本包含了这个参数,作为隐式的提示进行提取。具体流程表示为下图:

其次,在优先度排序阶段,作者作出了如下两个假设:1. 重要的参数会在更多的文档中被提及;2. 当考虑同一个参数越来越多的提示时,边际收益是递减的。因此作者提出了一个简单而有效的方式来进行优先度排序:提示越多的参数优先度越高,但是同一个参数的提示不能无限增加而应该有一个阈值加以限制,剩下的提示需要等剩余的参数考虑完再考虑。下图的例子就表示,参数1和2的提示数都超过了阈值,因此他们超过阈值的部分需要排在参数3之后。

然后,在提示翻译成参数和对应数值的阶段,由于在整体框架中应用了强化学习的逻辑,即不仅需要吸收(exploitation),也需要探索(exploration),因此在转换的过程中,会对参数的数值乘以一个大于1的乘数,从而探索出更多更优的参数值。对于绝对值直接进行转换即可,而对于相对值,需要在问题定义中提到的系统的某个参数(比如内存总量、CPU核心数等)。
最后,在强化学习的模型选择上,作者将神经网络的动作选择问题建模为一个多项选择题回答问题,使用的模型为BertForMultipleChoice Transformer model,并且整体的强化学习算法选择了Double Deep Q-Networks。
综上,总的算法如下所示,相应的详细函数的算法感兴趣的同学可以参考论文原文。

实验结果
在实验方面,本文主要对比了最近的一个数据库调参的工作DDPG++[3]以及作者之前的工作和其使用的实验基线[5]。系统使用的输入文本文档主要是在google.com中搜索XXX(数据库名字) performance tuning hints这个问题的前100个结果的页面。作者分别比较了MySQL和Postgres两种数据库系统,其中出现频率较高的数据库参数如下表所示:

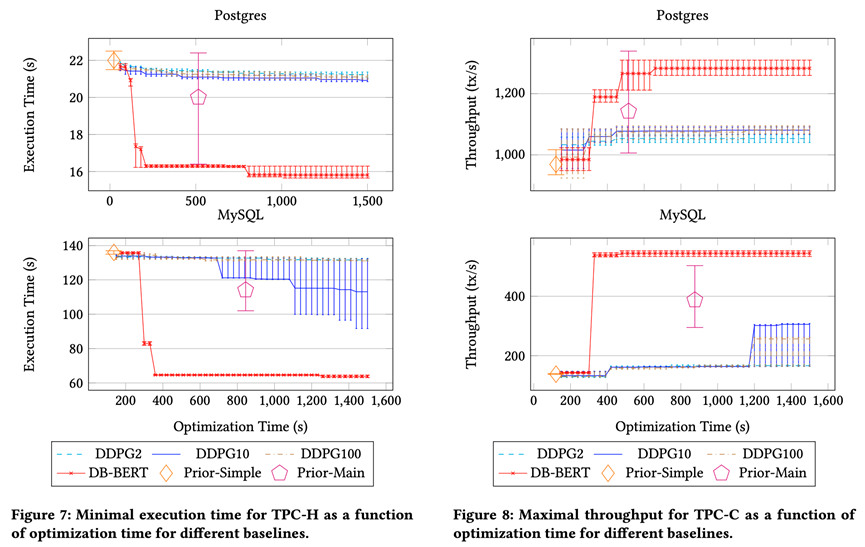
实验结果如下图,表明本文提出的方法可以在不同的数据库类型、不同的数据集上都能够取得更好的性能结果,也能够相比于其他强化学习类的方法能够更快得收敛,达到模型认为的最优的参数。其他更多的实验结果,感兴趣的同学也可以参考原文。
总结
文章的作者提出了自然语言处理增强的数据库调参方法和对应的系统框架,该方法在实验中被证明了能够从以工作手册为主的文本文档中提取出能够极大提升系统性能的相关提示,从而不仅能够处理相对而言比较复杂的数据库调参问题,也能够相比于之前的强化学习方法使用更少的迭代轮次(节约训练时间)。
但是,从文章整体的阅读和思考来看,也存在以下几个问题(仅代表本人意见,欢迎大家思考和批评指正):
在提示提取、优先度排序以及翻译等步骤,作者还是采用了更多rule-base的方法,这些方法有很多并没有在理论上或者实验上被证明是有效的。或许在这些步骤中还有很多值得商榷或者改进的点;
在强化学习的设计部分,为了能够用上自然语言处理的最新预训练技术(BERT),存在将自然语言先转换成格式化的语句,又再转换为模板化自然语言的情况,这种转换有可能会增加级联误差,从而导致模型的效果不够理想。因此在强化学习的动作选择方面或许还有更好的策略。
整体系统的可用性也值得思考。操作这个系统运行,以及对系统模块的部分修改的工作量似乎并不比阅读工作手册再进行调参的工作量和效果要好。如果文章中有更多的case study就更好了。
作者对DB-BERT这个系统也进行了开源,欢迎大家试用,可 点击原文至:
https://github.com/itrummer/dbbert
参考文献
[1] Li, Guoliang, et al. “Qtune: A query-aware database tuning system with deep reinforcement learning.” Proceedings of the VLDB Endowment 12.12 (2019): 2118-2130.
[2] Zhang, Ji, et al. “An end-to-end automatic cloud database tuning system using deep reinforcement learning.” Proceedings of the 2019 International Conference on Management of Data. 2019.
[3] Van Aken, Dana, et al. “An inquiry into machine learning-based automatic configuration tuning services on real-world database management systems.” Proceedings of the VLDB Endowment 14.7 (2021): 1241-1253.
[4] Trummer, Immanuel. “DB-BERT: a Database Tuning Tool that” Reads the Manual”.” arXiv preprint arXiv:2112.10925 (2021).
[5] Trummer, Immanuel. “The case for NLP-enhanced database tuning: towards tuning tools that” read the manual”.” Proceedings of the VLDB Endowment 14.7 (2021): 1159-1165.
Original: https://blog.csdn.net/weixin_48167662/article/details/123580409
Author: PKUMOD
Title: 论文导读 | 自然语言处理增强的数据库调参
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/530109/
转载文章受原作者版权保护。转载请注明原作者出处!