

0、导入所需的包
from sklearn.svm import SVC
from sklearn import datasets
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
1、获取数据
iris = datasets.load_iris()
x = iris.data
y = iris.target
print(x)
print(y)
鸢尾花数据共150个,每个样本有4个特征如下:


其标签有3种类型,分别是0,1,2:

2、数据预处理
特征缩放:我们可以观察到X的值之间相差比较大,为了能够得到更好的分类效果,我们采用特征缩放对数据进行处理。这里用到的是MinMaxScaler。还有其他特征缩放方法参见:其他特征缩放方法
scaler = MinMaxScaler(feature_range=(0,1))
x = scaler.fit_transform(x)
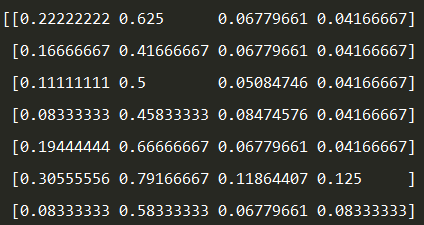
3、划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size= 1/3, random_state=0)
4、模型训练
SVC分类器,线性核函数,probability = True才能用predict_proba()函数查看每种类别的概率
classifier = SVC(kernel="linear",probability=True)
classifier.fit(X_train,y_train)
5、预测
y_pred = classifier.predict(X_test)
6、模型评估
params = classifier.get_params()
print(params)
y_pred_each = classifier.predict_proba(X_test)
score = classifier.score(X_test,y_test)
print("score: ",score)
print(y_pred)
print(y_test)
查看分类模型评分报告
report = classification_report(y_test,y_pred)
print(report)
7、交叉验证
cv=5表示分为5份进行划分
cross_scores = cross_val_score(classifier, x,y,cv=5)
print("cross_scores: ",cross_scores)
8、模型优化
优化模型的方法包括:网格搜索法、随机搜索法、模型特定交叉验证,信息准则优化。
网络搜索:在指定超参数空间对每种情况进行交叉验证评分并选出最好的超参数模型
classifier_2 = SVC()
param_grid = [{'C':[0.1, 1, 10, 100, 1000], 'kernel':['linear']},
{'C':[0.1, 1, 10, 100, 1000], 'kernel':['rbf'], 'gamma':[0.001, 0.01]}]
clf = GridSearchCV(classifier_2,param_grid,scoring='accuracy',cv=10)
clf.fit(X_train,y_train)
y_pred_best = clf.predict(X_test)
score_best = clf.score(X_test,y_test)
print("score best: ", score_best)
print(y_pred_best)
print(y_test)
9、总结
官方教程:
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
if __name__ == '__main__':
pipe = make_pipeline(
StandardScaler(),
LogisticRegression()
)
x,y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(x,y, test_size= 1/3,random_state=0)
pipe.fit(X_train,y_train)
y_pred = pipe.predict(X_test)
print(accuracy_score(y_pred,y_test))
print(y_pred)
print(y_test)
根据上面官方教程的方法得到的
score = 84%
根据第6步的方法得到的score = 96%
根据第8步的方法得到的score = 98%


参考链接:添加链接描述
Original: https://blog.csdn.net/ETF6996/article/details/115957558
Author: SIAT_啊哦
Title: sklearn-鸢尾花分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/666571/
转载文章受原作者版权保护。转载请注明原作者出处!