

作业代码地址:点我
1.分析数据
训练集
列是时间, 一共24列,是每天的24小时
行是检测的特征值,每次会检测18个特征值,故 每18行是一天的数据
一个月20天,一年12个月,所以一共 182012行的数据
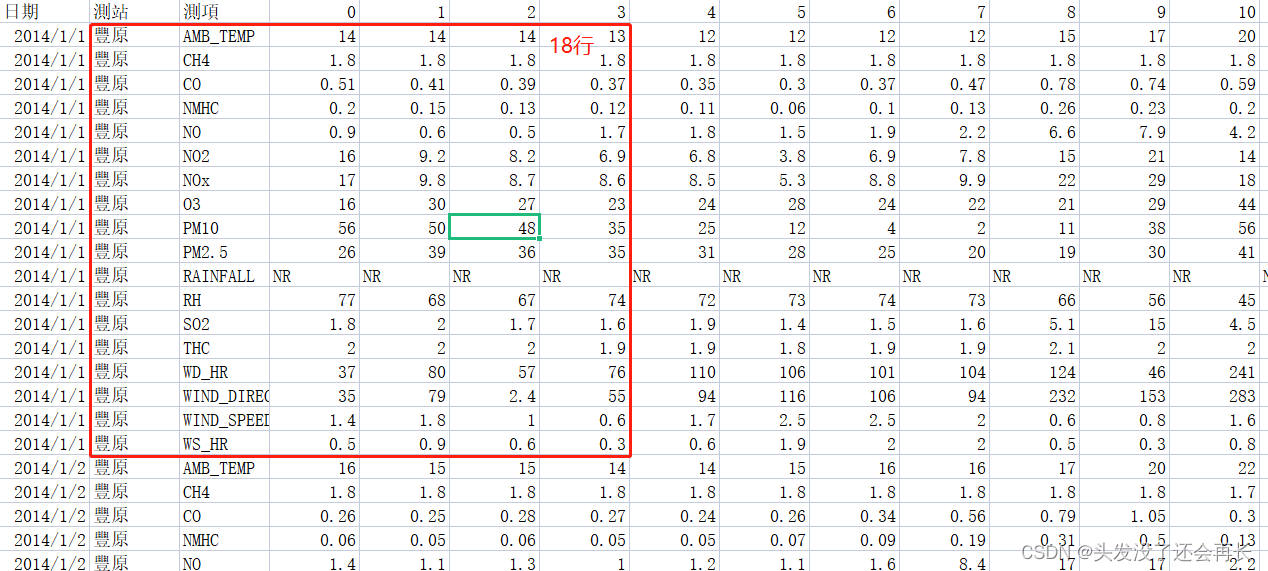

; 测试集
给了 连续9个小时的数据,预测 第十个小时的PM2.5的值
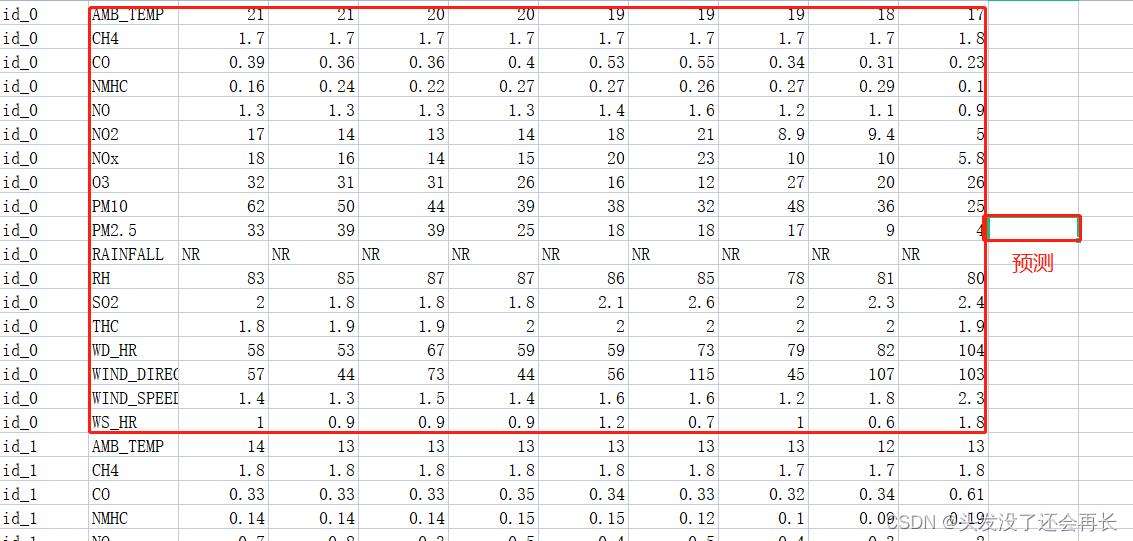
看上图可知,我们需要训练的Model的
input 应该是这18个测量数据在9个小时内的所有测量值,而 output 则是第10个小时的PM2.5的值。
2.数据的预处理
首先 删除无用的数据:
删除前三列数据,前三列是日期,测站,测项
然后 替换掉非数字数据:
将降雨量对应的一行NR替换成0
最后将数据转换为 numpy
import pandas as pd
import numpy as np
import csv
import math
data = pd.read_csv('./train.csv', encoding='big5')
data = data.iloc[:, 3:]
data[data=='NR'] = 0
raw_data = data.to_numpy()
打印第一行raw_data[0]:
[’14’ ’14’ ’14’ ’13’ ’12’ ’12’ ’12’ ’12’ ’15’ ’17’ ’20’ ’22’ ’22’ ’22’
’22’ ’22’ ’21’ ’19’ ’17’ ’16’ ’15’ ’15’ ’15’ ’15’]
3.提取特征
根据测试数据来划分训练数据,测试数据的 输入是9个小时的数据,每次输入18行,所以我们可以先将测试集划分为 只有18行的数据,方法如下:
想只留下18行,剩下数据就可以拼接到这18行的右侧( 不区分天数,我们只关心连续的小时)
每 18行24列是一天的数据, 一个月的20天也就是20×18行24列的数据,我们可以每个月的这 20天的数据每18行都拼接到右侧,这样 每个月就是20×24列,一个12个月
如下图所示(略粗糙,最后那个是12月)
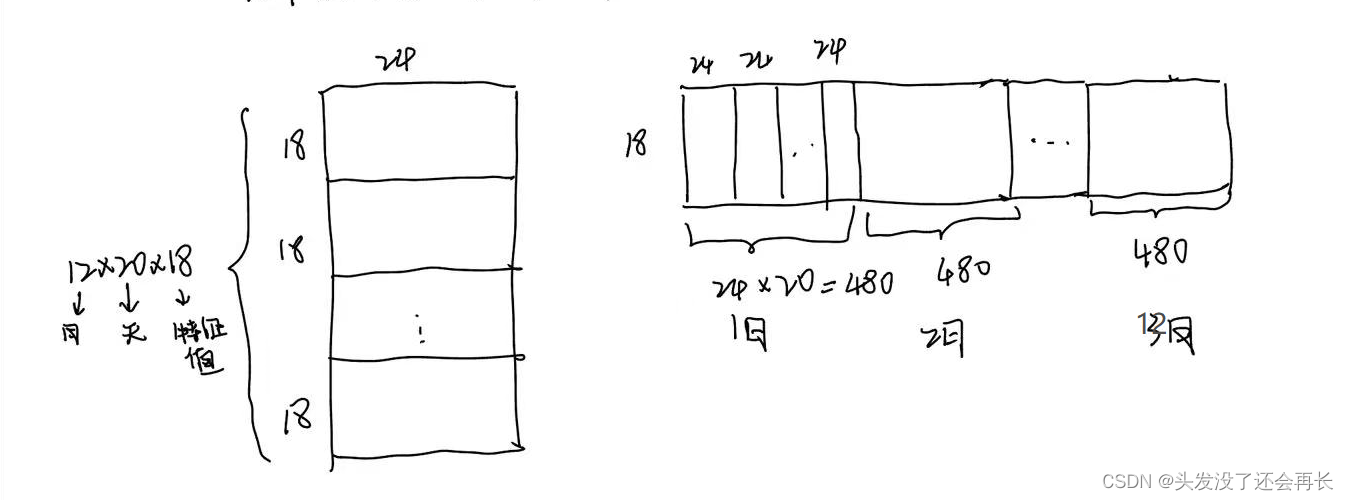
另外,因为是 只有前9个小时作为输入,所以数据集还要按照每10列划分为一组(输入9,另外1列作为target),每个月是480列,按照每次移动一步来划分数据集,划分完 一共是471组数据。每一组的输入都用reshape扁平化为向量。
x = np.empty((12*471, 18*9))
y = np.empty((12*471, 1))
for month in range(12):
for hour in range(471):
x[month*471+hour] = month_data[month][:, hour:hour+9].rashape(1,-1)
y[month*471+hour] = month_data[month][:, 9, hour+9]
4.归一化
归一化,即对每个特征,求其均值和标准差。然后将每个数值都减去其均值后再除以标准差,这样特征的期望就变成了0,标准差变成1。
mean_x = np.mean(x, axis=0)
std_x = np.std(x, axis=0)
for i in range(18*9):
if std_x[i] != 0:
x[:, i] = (x[:i]-mean_x[i]) / std_x[i]
5.将数据分为训练集和验证集
def reArrangeTrainValidation(x,i=0,total=5):
group_size = int(len(x) / total)
x_train=np.concatenate((x[:group_size*i],x[group_size*(i+1):]),axis=0)
y_train=np.concatenate((y[:group_size*i],y[group_size*(i+1):]),axis=0)
x_validation=x[group_size*i:group_size*(i+1)]
y_validation=y[group_size*i:group_size*(i+1)]
return (x_train,y_train),(x_validation,y_validation)
6.定义模型开始训练
- 在GradientDescent的环节中采用的就是n次函数
- GradientDescent的时候还是使用的残差平方和来计算梯度
- 采用Adagrad优化算法
def computeY(n,x,w):
py = np.zeros([len(x), 1])
for e in range(1 + n):
py += np.dot(x ** e, w[e])
return py
def gradientDescent(n, x, y):
dim = 18*9
w = [np.zeros([dim, 1]) for e in range(1 + n)]
adagrad = [np.zeros([dim, 1]) for e in range(1+n)]
learning_rate = 100
epoch = 10000
eps = 0.0000000001
for t in range(epoch):
py = computeY(n, x, w)
loss = np.sqrt(np.sum(np.power(py - y, 2)) / len(x))
if(t % 100==0):
print(str(t) + ":" + str(loss))
for e in range(1+n):
gradient = 2 * np.dot(x.transpose() ** e, py - y)
adagrad[e] += gradient ** 2
w[e] = w[e] - learning_rate / np.sqrt(adagrad[e] + eps) * gradient
for e in range(1 + n):
np.save(str(e) + '.weight.npy', w[e])
7.测试数据集处理
测试数据集和训练数据集做相同的处理
testdata=pd.read_csv('./test.csv',header = None,encoding='big5')
test_data=testdata.iloc[:,2:]
test_data[test_data=='NR']=0
test_data=test_data.to_numpy()
test_x=np.empty([240,18*9],dtype=float)
for i in range(240):
test_x[i]=test_data[i*18:(i+1)*18,:].reshape(1,-1)
for i in range(18*9):
if std_x[i] !=0:
test_x[:,i]=(test_x[:,i]-mean_x[i])/std_x[i]
8.对测试集做预测
将上一步训练保存的模型权值直接下载下来用于训练
w=[]
for e in range(1+n):
w.append(np.load(str(e)+'.weight.npy'))
做预测(输入x得到输出,computeY函数)
py=computeY(n,test_x,w)
9.保存模型
with open('submit.csv', mode='w', newline='') as submit_file:
csv_writer = csv.writer(submit_file)
header = ['id', 'value']
print(header)
csv_writer.writerow(header)
for i in range(240):
row = ['id_' + str(i), py[i][0]]
csv_writer.writerow(row)
print(row)
参考文献
李宏毅 2020机器学习作业1 详细解析
李宏毅机器学习特训营-机器学习作业1-PM2.5预测
Original: https://blog.csdn.net/m0_51474171/article/details/127739808
Author: 头发没了还会再长
Title: 【李宏毅】机器学习——作业1-PM2.5预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/658596/
转载文章受原作者版权保护。转载请注明原作者出处!