



一、原始GAN的缺点
生成的图像是随机的,不可预测的,无法控制网络输出特定的图片,生成目标不明确,可控性不强。针对原始GAN不能生成具有特定属性的图片的问题, Mehdi Mirza等人提出了cGAN,其核心在于将属性信息y 融入生成器G和判别器D中,属性y可以是任何标签信息, 例如图像的类别、人脸图像的面部表情等。
二、CGAN的基本原理
cGAN的中心思想是希望 可以控制 GAN 生成的图片,而不 是单纯的随机生成图片。 具体来说,Conditional GAN 在生成器和判别器的输入中 增加了额外的 条件信息,生成器生成的图片只有足够真实 且与条件相符,才能够通过判别器。
实际上 , 在无条件约束的生成模型中 , 没法控制数据生成的模式。然而,通过额外的信息对模型进行约束,有可能指导数据生成的过程。条件约束可以是类标签 , 可以是图像修补的部分数据, 甚至是来自不同模态的数据
cGAN将 无监督学习 转为 有监督学习 使得网络可以更好地在我们的掌控下进行学习!
从公式看,cgan相当于在原始GAN的基础上对生成器部分 和判别器部分都加了一个条件
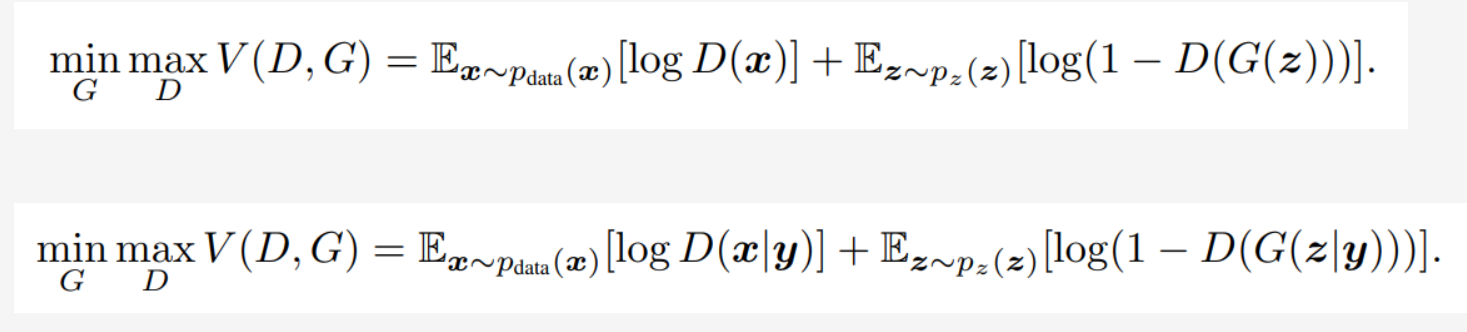
三、CGAN模型
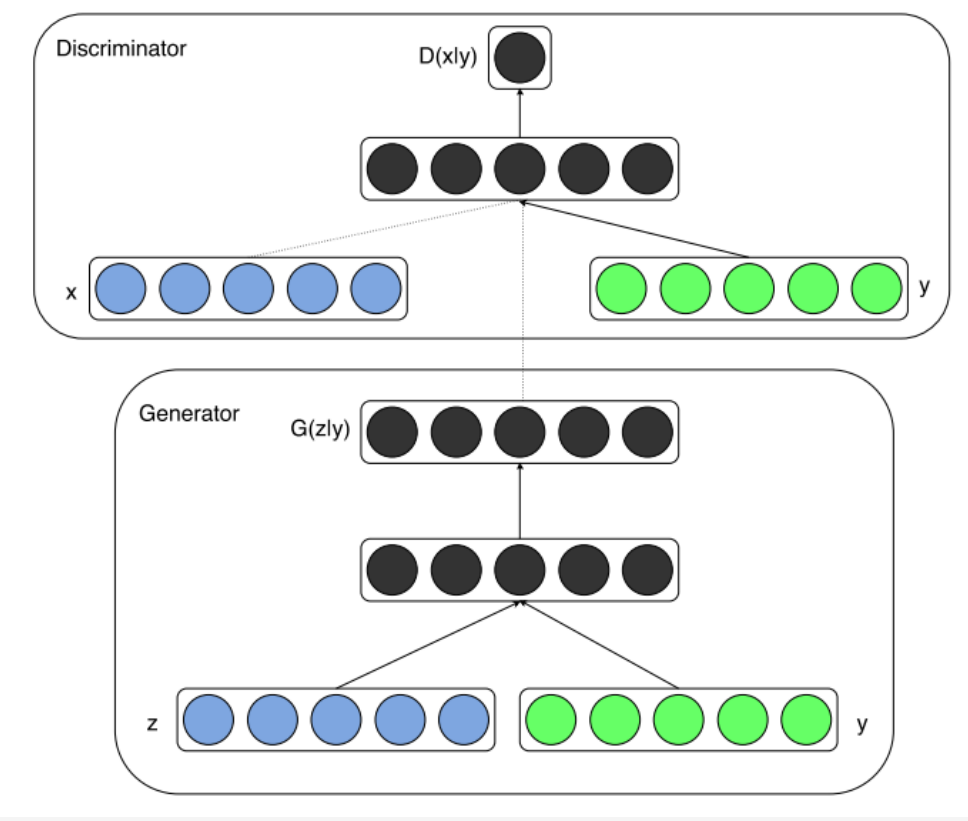
如果将上图绿色部分的y去掉,就是GAN的原理图。
四、CGAN结构
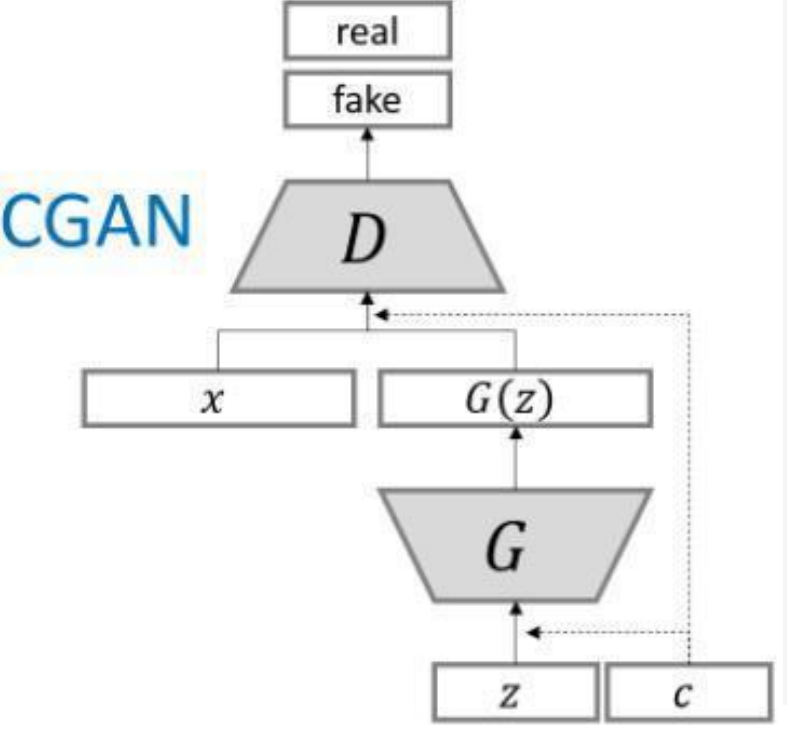
为了实现条件GAN的目的,生成网络和判别网络的原理和 训练方式均要有所改变。
模型部分,在判别器和生成器中都添加了额外信息 y,y 可 以是类别标签或者是其他类型的数据,可以将 y 作为一个 额外的输入层丢入判别器和生成器。
在生成器中,作者将输入噪声 z 和 y 连在一起隐含表示, 带条件约束这个简单直接的改进被证明非常有效,并广泛用 于后续的相关工作中。论文是在MNIST数据集上以类别标 签为条件变量,生成指定类别的图像。作者还探索了CGAN 在用于图像自动标注的多模态学习上的应用,在MIR Flickr25000数据集上,以图像特征为条件变量,生成该图像的tag的词向量。
五、CGAN缺陷
cGAN生成的图像虽有很多缺陷,譬如图像边缘模糊,生成的图像分辨率太低等,但是它为后面的pix2pixGAN和CycleGAN开拓了道路,这两个模型转换图像风格时对属性特征的 处理方法均受cGAN启发。
六、代码实现,生成指定手写数字
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
from torch.utils import data
import os
import glob
from PIL import Image
独热编码
输入x代表默认的torchvision返回的类比值,class_count类别值为10
def one_hot(x, class_count=10):
return torch.eye(class_count)[x, :] # 切片选取,第一维选取第x个,第二维全要
transform =transforms.Compose([transforms.ToTensor(),
transforms.Normalize(0.5, 0.5)])
dataset = torchvision.datasets.MNIST('data',
train=True,
transform=transform,
target_transform=one_hot,
download=False)
dataloader = data.DataLoader(dataset, batch_size=64, shuffle=True)
定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.linear1 = nn.Linear(10, 128 * 7 * 7)
self.bn1 = nn.BatchNorm1d(128 * 7 * 7)
self.linear2 = nn.Linear(100, 128 * 7 * 7)
self.bn2 = nn.BatchNorm1d(128 * 7 * 7)
self.deconv1 = nn.ConvTranspose2d(256, 128,
kernel_size=(3, 3),
padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv2 = nn.ConvTranspose2d(128, 64,
kernel_size=(4, 4),
stride=2,
padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv3 = nn.ConvTranspose2d(64, 1,
kernel_size=(4, 4),
stride=2,
padding=1)
def forward(self, x1, x2):
x1 = F.relu(self.linear1(x1))
x1 = self.bn1(x1)
x1 = x1.view(-1, 128, 7, 7)
x2 = F.relu(self.linear2(x2))
x2 = self.bn2(x2)
x2 = x2.view(-1, 128, 7, 7)
x = torch.cat([x1, x2], axis=1)
x = F.relu(self.deconv1(x))
x = self.bn3(x)
x = F.relu(self.deconv2(x))
x = self.bn4(x)
x = torch.tanh(self.deconv3(x))
return x
定义判别器
input:1,28,28的图片以及长度为10的condition
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.linear = nn.Linear(10, 1*28*28)
self.conv1 = nn.Conv2d(2, 64, kernel_size=3, stride=2)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2)
self.bn = nn.BatchNorm2d(128)
self.fc = nn.Linear(128*6*6, 1) # 输出一个概率值
def forward(self, x1, x2):
x1 =F.leaky_relu(self.linear(x1))
x1 = x1.view(-1, 1, 28, 28)
x = torch.cat([x1, x2], axis=1)
x = F.dropout2d(F.leaky_relu(self.conv1(x)))
x = F.dropout2d(F.leaky_relu(self.conv2(x)))
x = self.bn(x)
x = x.view(-1, 128*6*6)
x = torch.sigmoid(self.fc(x))
return x
初始化模型
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device)
dis = Discriminator().to(device)
损失计算函数
loss_function = torch.nn.BCELoss()
定义优化器
d_optim = torch.optim.Adam(dis.parameters(), lr=1e-5)
g_optim = torch.optim.Adam(gen.parameters(), lr=1e-4)
定义可视化函数
def generate_and_save_images(model, epoch, label_input, noise_input):
predictions = np.squeeze(model(label_input, noise_input).cpu().numpy())
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i + 1)
plt.imshow((predictions[i] + 1) / 2, cmap='gray')
plt.axis("off")
plt.savefig('D:/practice/CGAN/img/image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
noise_seed = torch.randn(16, 100, device=device)
label_seed = torch.randint(0, 10, size=(16,))
label_seed_onehot = one_hot(label_seed).to(device)
print(label_seed)
print(label_seed_onehot)
开始训练
D_loss = []
G_loss = []
训练循环
for epoch in range(150):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(dataloader.dataset)
# 对全部的数据集做一次迭代
for step, (img, label) in enumerate(dataloader):
img = img.to(device)
label = label.to(device)
size = img.shape[0]
random_noise = torch.randn(size, 100, device=device)
d_optim.zero_grad()
real_output = dis(label, img)
d_real_loss = loss_function(real_output,
torch.ones_like(real_output, device=device)
)
d_real_loss.backward() #求解梯度
# 得到判别器在生成图像上的损失
gen_img = gen(label,random_noise)
fake_output = dis(label, gen_img.detach()) # 判别器输入生成的图片,f_o是对生成图片的预测结果
d_fake_loss = loss_function(fake_output,
torch.zeros_like(fake_output, device=device))
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
d_optim.step() # 优化
# 得到生成器的损失
g_optim.zero_grad()
fake_output = dis(label, gen_img)
g_loss = loss_function(fake_output,
torch.ones_like(fake_output, device=device))
g_loss.backward()
g_optim.step()
with torch.no_grad():
d_epoch_loss += d_loss.item()
g_epoch_loss += g_loss.item()
with torch.no_grad():
d_epoch_loss /= count
g_epoch_loss /= count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
if epoch % 10 == 0:
print('Epoch:', epoch)
generate_and_save_images(gen, epoch, label_seed_onehot, noise_seed)
plt.plot(D_loss, label='D_loss')
plt.plot(G_loss, label='G_loss')
plt.legend()
plt.show()
具体实战代码解读,参考:GAN实战之Pytorch 使用CGAN生成指定MNIST手写数字
Original: https://blog.csdn.net/m0_62128864/article/details/123972758
Author: 码农男孩
Title: GANs系列:CGAN(条件GAN)原理简介以及项目代码实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/517882/
转载文章受原作者版权保护。转载请注明原作者出处!