

Google发布的TabNet是一种针对于表格数据的神经网络,它通过类似于加性模型的顺序注意力机制(sequential attention mechanism)实现了instance-wise的特征选择,还通过encoder-decoder框架实现了自监督学习。
表格数据是日常中用到的最多的数据类型。例如信用卡的欺诈检测:我们提取交易、身份、产品和网络属性(并将它们放入一个大的特征表中,不同的机器学习模型可以轻松地使用这些特征进行训练和推理。基于决策树的模型(例如随机森林或 XGBoost)是处理表格数据的首选算法,因为它们的性能、可解释性、训练速度和鲁棒性都是目前最好的。
但是神经网络在许多领域被认为是最先进的,并且在具有最少特征工程的大型数据集上表现特别好。我们的许多客户都有大量交易量,深度学习是提高模型在欺诈检测方面性能的潜在途径。
在这篇文章中,我们将深入研究称为 TabNet (Arik & Pfister (2019)) 的神经网络架构,该架构旨在可解释并与表格数据很好地配合使用。在解释了它背后的关键构建块和想法之后,您将了解如何在 TensorFlow 中实现它以及如何将其应用于欺诈检测数据集,如果你使用Pytorch也不用担心,TabNet有各种深度学习框架的实现。
TabNet
TabNet 使用 Sequential Attention 的思想模仿决策树的行为。 简单地说,可以将其视为一个多步神经网络,在每一步应用两个关键操作:
- Attentive Transformer 选择最重要的特征在下一步处理
- 通过Feature Transformer 将特征处理成更有用的表示
模型最后使用Feature Transformer 的输出稍后用于预测。 TabNet 同时使用 Attentive 和 Feature Transformers,能够模拟基于树的模型的决策过程。 例如以下的成人人口普查收入数据集的预测,模型能够选择和处理对手头任务最有用的特征,从而提高可解释性和学习能力。
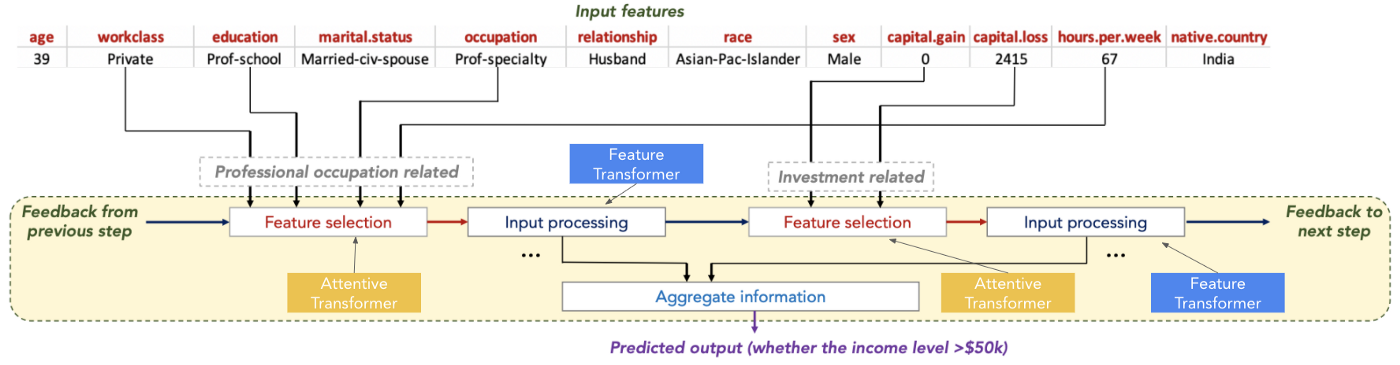

Attentive 和 Feature Transformer 的关键构建块是所谓的 Feature Blocks,所以让我们先来探索一下。
; Feature Block 特征块
Feature Block由顺序应用的全连接(FC)或密集层和批量归一化(BN)组成。 此外,对于Feature Transformer ,输出通过 GLU 激活层传递。

GLU(与 sigmoid 门相反)的主要功能是允许隐藏单元更深入地传播到模型中并防止梯度爆炸或消失。
def glu(x, n_units=None):
"""Generalized linear unit nonlinear activation."""
return x[:, :n_units] * tf.nn.sigmoid(x[:, n_units:])
原论文在训练过程中使用了Ghost Batch Normalisation来提高收敛速度。如果你感兴趣,你可以搜索下相关的介绍,但在本文中我们将使用默认的BN层。
class FeatureBlock(tf.keras.Model):
"""
Implementation of a FL->BN->GLU block
"""
def __init__(
self,
feature_dim,
apply_glu = True,
bn_momentum = 0.9,
fc = None,
epsilon = 1e-5,
):
super(FeatureBlock, self).__init__()
self.apply_gpu = apply_glu
self.feature_dim = feature_dim
units = feature_dim * 2 if apply_glu else feature_dim # desired dimension gets multiplied by 2
# because GLU activation halves it
self.fc = tf.keras.layers.Dense(units, use_bias=False) if fc is None else fc # shared layers can get re-used
self.bn = tf.keras.layers.BatchNormalization(momentum=bn_momentum, epsilon=epsilon)
def call(self, x, training = None):
x = self.fc(x) # inputs passes through the FC layer
x = self.bn(x, training=training) # FC layer output gets passed through the BN
if self.apply_gpu:
return glu(x, self.feature_dim) # GLU activation applied to BN output
return x
Feature Transformer
Feature Transformer (FT) 是按顺序应用的特征块的集合。 在论文中,一个 FeatureTransformer 由两个共享块(即跨步重用权重)和两个依赖于步的块组成。 共享权重减少了模型中的参数数量并提供更好的泛化。

下面将介绍如何使用上一节中的 Feature Block来构建 Feature Transformer。
class FeatureTransformer(tf.keras.Model):
def __init__(
self,
feature_dim,
fcs = [],
n_total = 4,
n_shared = 2,
bn_momentum = 0.9,
):
super(FeatureTransformer, self).__init__()
self.n_total, self.n_shared = n_total, n_shared
kwrgs = {
"feature_dim": feature_dim,
"bn_momentum": bn_momentum,
}
# build blocks
self.blocks = []
for n in range(n_total):
# some shared blocks
if fcs and n < len(fcs):
self.blocks.append(FeatureBlock(**kwrgs, fc=fcs[n])) # Building shared blocks by providing FC layers
# build new blocks
else:
self.blocks.append(FeatureBlock(**kwrgs)) # Step dependent blocks without the shared FC layers
def call(self, x, training = None):
# input passes through the first block
x = self.blocks[0](x, training=training)
# for the remaining blocks
for n in range(1, self.n_total):
# output from previous block gets multiplied by sqrt(0.5) and output of this block gets added
x = x * tf.sqrt(0.5) + self.blocks[n](x, training=training)
return x
@property
def shared_fcs(self):
return [self.blocks[i].fc for i in range(self.n_shared)]
Attentive Transformer
Attentive Transformer (AT) 负责每一步的特征选择。 特征选择是通过应用 sparsemax 激活(而不是 GLU)来完成的并同时考虑到先验的比例。 先验比例允许我们控制模型选择一个特征的频率,并由它在前面的步骤中使用的频率控制(稍后会详细介绍)。
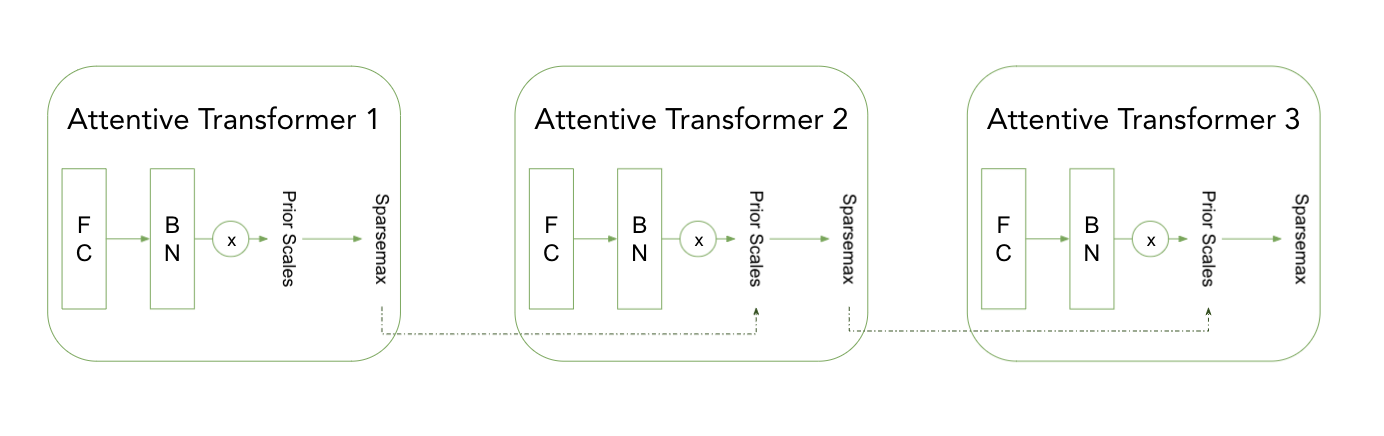
前一步的Transformer 提供前一步特征的比例信息,相当于告知了前一个步骤中使用了哪些特性。 与 Feature Transformer 类似Attentive Transformer 可以作为 TensorFlow 模型集成到更大的架构中。
class AttentiveTransformer(tf.keras.Model):
def __init__(self, feature_dim):
super(AttentiveTransformer, self).__init__()
self.block = FeatureBlock(
feature_dim,
apply_glu=False, # sparsemax instead of glu
)
def call(self, x, prior_scales, training=None):
# Pass input trhough a FC-BN block
x = self.block(x, training=training)
# Pass the output through sparsemax activation
return sparsemax(x * prior_scales)
由于Feature和Transformer块可能会变得非常依赖参数,TabNet使用了一些机制来控制复杂性并防止过拟合。
正则化
前一步特征比例计算
先验比例(P)允许我们控制模型选择特征的频率。 使用先前的 Attentive Transformer 激活和松弛因子 (γ) 参数计算先验尺度 §。 这是论文中提出的公式。
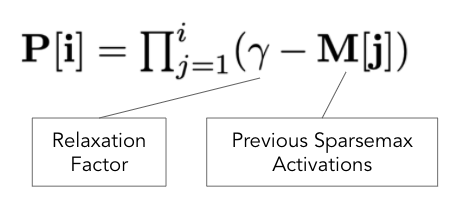
这个等式显示了先验比例(P)是如何更新的。 从直观上来说,如果在前面的步骤中使用了一个特征,那么模型会更加关注剩下的特征,以减少过拟合。
例如,当 γ=1 时,具有较大激活(例如 0.9)的特征将具有较小的先验尺度(1-0.9=0.1)。 较小的先验比例确保不会在当前步骤中选择该特征。
稀疏正则化
由超参数 λ 缩放的激活熵会被添加到整体模型损失中,通过这种方式对于损失进行稀疏正则化可以使注意力掩码变得更稀疏。
def sparse_loss(at_mask):
loss = tf.reduce_mean(
tf.reduce_sum(tf.multiply(-at_mask, tf.math.log(at_mask + 1e-15)),
axis=1)
)
return loss
not_sparse_mask = np.array([[0.4, 0.5, 0.05, 0.05],
[0.2, 0.2, 0.5, 0.1]])
sparse_mask = np.array([[0.0, 0.0, 0.7, 0.3],
[0.0, 0.0, 1, 0.0]])
print('Loss for non-sparse attention mask:', sparse_loss(not_sparse_mask).numpy())
print('Loss for sparse attention mask:', sparse_loss(sparse_mask).numpy())
Loss for non-sparse attention mask: 1.1166351874690217
Loss for sparse attention mask: 0.3054321510274452
TabNet的所有组件都已经介绍完成了,接下来让我们了解如何使用这些组件来构建 TabNet 模型。
TabNet 架构
把它们放在一起,TabNet 的主要思想是按顺序应用 Feature 和 Attentive Transformers 组件,这样模型可以模仿决策树的生成过程。 Attentive Transformer 执行特征选择,而 Feature Transformer 执行允许模型学习数据中复杂模式的转换。 可以在下面看到一个图表,该图表总结了 2 步 TabNet 模型的数据流。
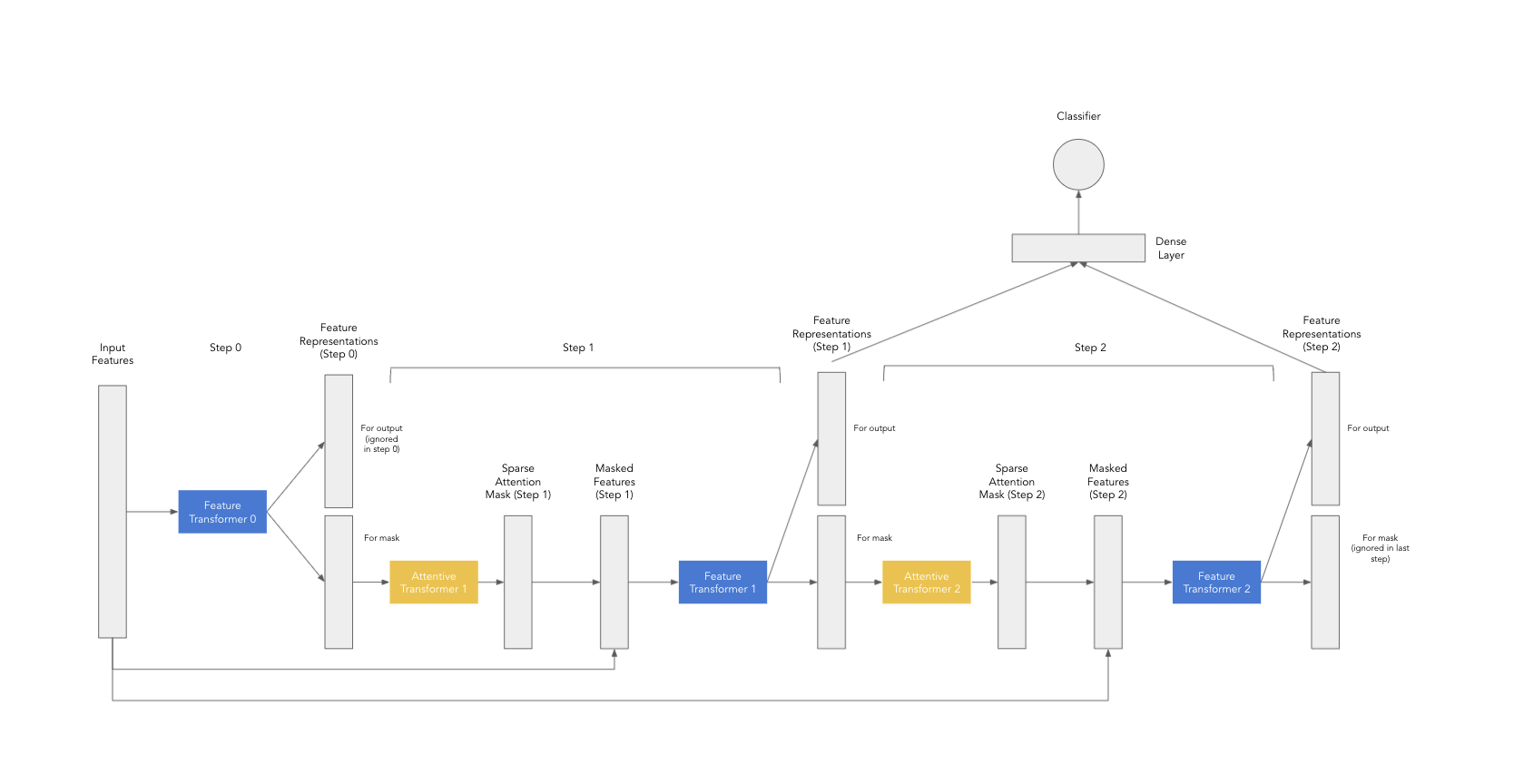
首先通过Feature Transformer传递初始输入特征以获得初始特征表示。 这个Feature Transformer的输出会被用作Attentive Transformer的输入,Attentive Transformer选择一个特征子集传递到下一步。 这会有一个超参数来设定重复此步骤的次数。
模型通过使用每个决策步骤的Feature Transformer输出来生成最终预测。 此外,在每一步注意力的掩码,以了解哪些特征被用于进行预测。 这些掩码可用于获得局部特征重要性以及全局重要性。
以上就是TabNet的完整架构,下面让我们看看如何在Kaggle的欺诈检测示例数据集上训练这个模型。
; 使用 TabNet 进行欺诈检测
下面使用的数据集和代码都可以在我们最后提供的连接中找到。
数据
训练数据集非常大,有大约 590k 条数据,每条数据包含 420 个特征。执行的预处理是非常基础的,因为这不是本文的目标:
- 删除非信息列
- 缺失值填充
- 编码分类变量
- 基于时间的训练/验证拆分
超参数调优
TabNet(与任何神经网络一样)对超参数非常敏感,因此调整对于获得一个好的模型至关重要。 以下是我们发现对模型性能影响最大的变量(和建议范围):
- 特征维度/输出维度:从 32 到 512(我们通常将这些参数设置为相等的数值,因为论文也是这么建议的)
- 步数:从 2(简单模型)到 9(非常复杂的模型),就是我们在架构中说的那个超参数
- 松弛因子:从 1(强制仅在 第1 步使用特征)到 3(放松限制)
- 稀疏系数:从 0(无正则化)到 0.1(强正则化)
文末提供的代码中还给出了一个简单的 HP 调整示例。
训练和评估
训练TabNet与其他模型类似,可以通过试验学习速率调度和衰减来进一步提高性能。
Params after 1 hour of tuning
tabnet = TabNet(num_features = train_X_transformed.shape[1],
output_dim = 128,
feature_dim = 128,
n_step = 2,
relaxation_factor= 2.2,
sparsity_coefficient=2.37e-07,
n_shared = 2,
bn_momentum = 0.9245)
Early stopping based on validation loss
cbs = [tf.keras.callbacks.EarlyStopping(
monitor="val_loss", patience=30, restore_best_weights=True
)]
Optimiser
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01, clipnorm=10)
Second loss in None because we also output the importances
loss = [tf.keras.losses.CategoricalCrossentropy(from_logits=False), None]
Compile the model
tabnet.compile(optimizer,
loss=loss)
Train the model
tabnet.fit(train_ds,
epochs=1000,
validation_data=val_ds,
callbacks=cbs,
verbose=1,
class_weight={
0:1,
1: 10
})
通常使用ROC和PR AUC分数来评估模型(因为目标是不平衡的),所以这里是这个模型的验证集上的指标。
Test ROC AUC 0.8505
Test PR AUC 0.464
结果还可以,但是其实不太好,不过我们本文的目的并不是获得名次,我们的目的是如何构建和训练TabNet模型。
总结
本文介绍了 TabNet 的架构,以及它如何使用 Attentive 和 Feature Transformers 进行预测。 TabNet 还有很多我们没有涉及的内容(例如注意力掩码和自监督的预训练),所以如果想进一步探索这个模型,请再深入阅读下面的这些资源:
https://www.overfit.cn/post/ed9ca50d53a14158a4d82718ca9a4767
本文作者:Anton Rubert
Original: https://blog.csdn.net/m0_46510245/article/details/122535383
Author: deephub
Title: 深入了解 TabNet :架构详解和分类代码实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/666474/
转载文章受原作者版权保护。转载请注明原作者出处!