

Abstract
我们考虑零样本识别问题:仅利用 类别的单词嵌入及其与 其他类别的关系来学习具有零训练示例的类别的视觉分类器,并提供视觉数据。处理陌生或新类的关键是将从熟悉类中获得的知识转移到陌生类的描述中。在本文中,我们基于最近引入的图卷积网络(GCN),提出了一种同时使用语义嵌入和类别关系来预测分类器的方法。对于一个已习得的知识图(KG),我们的方法将每个节点(表示视觉类别)作为输入语义嵌入。经过一系列的图卷积后,我们预测每个类别的视觉分类器。在训练过程中,给出了几个类别的视觉分类器来学习GCN参数。在测试时,这些过滤器被用来预测不可见类别的视觉分类器。结果表明,该方法在KG条件下对噪声具有鲁棒性。更重要的是,与目前最先进的结果相比,我们的方法提供了显著的性能改进(从一些指标的2 – 3%提高到一些指标的20%)。
Introduction
想想动物类别”非洲鹿”。尽管我们可能从未听说过这一类或视觉的例子在过去,我们还是可以学习一个好的视觉分类器基于以下描述:”斑马纹四腿的动物有一个棕色的躯干和一个形似鹿的脸”(图1)上测试自己。另一方面,我们目前的识别算法仍然在封闭世界条件下运行:也就是说,它们只能识别训练过的类别。添加一个新的类别需要收集数千个训练示例,然后重新训练分类器。为了解决这个问题,我们经常使用零样本学习。


处理陌生或新类的关键是将从熟悉类中获得的知识转化为对不熟悉类的描述 ( 泛化 )。 知识转移有两种范式。第一种范式是使用隐式知识表示,即语义嵌入。在这种方法中,人们使用文本数据学习不同类别的向量表示,然后直接学习向量表示与可视化分类器之间的映射。然而,这些方法受到语义模型和映射模型本身泛化能力的限制。从结构化信息中学习语义嵌入也很困难。
零样本学习的另一种较少探索的范例是 使用显性知识库或知识图。在这个范例中,一个人显式地将知识表示为规则或对象之间的关系。这些关系可以用来学习新类别的零样本分类器。最简单的例子是学习组成类别的视觉分类器。给定原始视觉概念的分类器作为输入,应用一个简单的组合规则来为新的复杂概念生成分类器。然而,在一般形式下,关系可能比简单的组合更复杂。我们想探究的一个有趣的问题是,我们是否可以使用结构化信息和复杂的关系来学习可视化分类器,而不需要看到任何示例。
在本文中,我们提出 同时提取隐式知识表示 ( 即词嵌入 ) 和显式关系 ( 即知识图 ) 来学习新类的视觉分类器。我们构建一个知识图,其中每个节点对应一个语义类别。这些节点通过关系边连接。图的每个节点的输入是每个类别的向量表示(语义嵌入)。然后我们使用图卷积网络在不同类别之间传输信息(消息传递)。具体来说,我们训练了一个6层深的GCN,输出不同类别的分类器。
在我们的工作中,我们提出 通过语义嵌入和知识图两种方法提取信息。具体来说,给定一个嵌入了不可见类别的单词嵌入和编码显式关系的知识图,我们的方法预测了不可见类别的可视化分类器。为了建立知识图的模型,我们的工作建立在图卷积网络之上。它最初是为语言处理中的半监督学习而提出的。我们通过改变模型结构和训练损失将其扩展到我们的零短期学习问题。
Approach
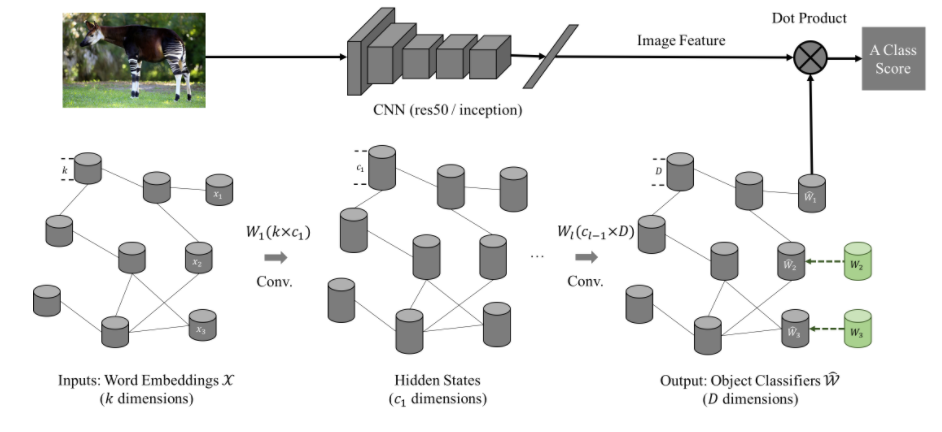
1、GCN
形式上,给定一个有n个实体
的数据集,其中xi表示实体i和yi∈{1,…, C}表示其标签。在半监督设置中,我们知道前m个实体的基础真理标签。我们的目标是利用词嵌入和关系图来推断剩余的n – m个没有标签的实体的yi。在关系图中,每个节点都是一个实体,如果两个节点之间有关系,则两个节点是链接的。
我们用函数F(·)表示图卷积网络。它将所有嵌入的实体词X作为一次输入,将所有这些实体词的SoftMax分类结果输出为F (X)。为简单起见,我们将第i个实体的输出表示为Fi(X),这是一个C维SoftMax概率向量。在训练时间中,我们将SoftMax损失应用于前m个实体,它们的标签为:
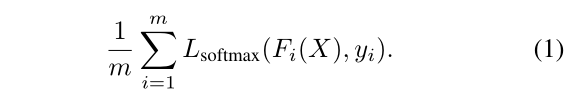
与操作图像局部区域的标准卷积不同,在GCN中,卷积操作根据邻接图定义的相邻节点计算节点上的响应。数学上,网络中每一层的卷积运算F(·)表示为:
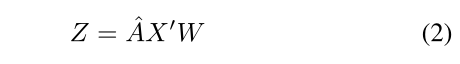
2、GCN For Zero-Shot Learning
我们的模型建立在图卷积网络的基础上。然而,我们将其应用于具有回归损失的零样本识别,而不是实体分类。我们框架的 输入是类别集合及其相应的语义嵌入向量(用X =
表示)。对于输出,我们希望 预测每个输入类别的可视分类器(用W = 表示)。
一种方法是训练一个神经网络(多层感知器),它将𝑥𝑖作为输入,并学习预测𝑥𝑖作为输出。网络的参数可以用m个训练对来估计。然而,通常m是很小的(在几百个数量级),因此,我们想要使用视觉世界的显式结构或类别之间的关系来约束问题。
我们将这些关系表示为知识图(KG)。KG中的每个节点代表一个语义类别。因为我们总共有n个类别,所以图中有n个节点。如果两个节点之间存在关系,则它们是相互连接的。图结构用n × n邻接矩阵a表示,我们不构建二部图,而是用无向边替换KG中的所有有向边,从而得到对称的邻接矩阵。
如图所示,我们使用6层GCN,其中每一层l以前一层(𝑍𝑙−1)的特征表示作为输入,并输出一个新的特征表示(Zl)。对于第一层,输入是X,它是一个n × k矩阵(k是单词嵌入向量的维数)。最后一层输出特征向量为ˆW,其大小为n × D;D是分类器的维数或视觉特征向量。
Our pipeline consists of two parts: CNN and GCN.
-
CNN: Input an image and output deep features for the image.
-
GCN: Input the word embedding for every object class, and output the visual classifier for every object class. Each visual classifier (1-D weight vector) can be applied on the deep features for classification.
Loss-function:对于前m个类别,我们已经预测分类器权重ˆW1…m和ground truth分类器权重从训练图像W1…我们使用平均误差作为预测值和ground truth分类器之间的损失函数。
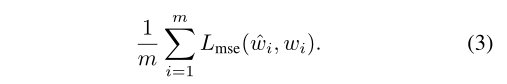
3、实现细节
我们的GCN由6个卷积层组成,输出通道号为2048→2048→1024→1024→512→D,其中D表示对象分类器的维数。与在[22]中介绍的2层网络不同,我们的网络要深得多。如烧蚀研究所示,我们发现使网络深度是产生分类器权值的必要条件。对于激活函数,我们不是在每个卷积层后使用ReLU,而是使用LeakyReLU,其负斜率为0.2。根据经验,我们发现LeakyReLU可以使我们的回归问题更快地收敛。
在训练我们的GCN时,我们对网络和ground-truth分类器的输出执行l2 -归一化。在测试过程中,生成的未见类的分类器也是L2-Normalized。我们发现添加这个约束很重要,因为它将所有分类器的权重正则化成类似的大小。在实践中,我们还发现ImageNet预训练网络的最后一层分类器是自然归一化的。也就是说,如果我们在测试期间对最后一层的每个分类器执行L2-Normalization,ImageNet 2012 1k类验证集的性能稍有变化(< 1%)。
为了获得 GCN 输入的单词嵌入,我们使用在维基百科数据集上训练的 GloVe 文本模型 ,从而得到 300d 向量。对于名称包含多个单词的类,我们匹配训练模型中的所有单词并找到它们的嵌入。通过平均这些词的嵌入,我们得到类的嵌入。
Original: https://blog.csdn.net/qq_29260257/article/details/122093436
Author: 一只瓜皮呀
Title: 【阅读笔记】Zero-shot Recognition via Semantic Embeddings and Knowledge Graphs-2018
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557622/
转载文章受原作者版权保护。转载请注明原作者出处!