

1、数据集构建
MMRoteate 支持的数据集


; 类别
The object categories in DOTA-v1.0:
plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field and swimming pool.
The object categories in DOTA-v1.5:
plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, swimming pool and container crane.
The object categories in DOTA-v2.0:
plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, swimming pool, container crane, airport and helipad.
注释的格式
在数据集中,每个对象都由一个面向边界框(OBB)标注,可以表示为
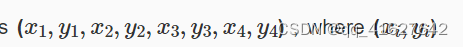
,其中(xi, yi)表示OBB的第i个顶点。顶点按顺时针顺序排列。下面是注释的可视化。 黄色的点代表起点,这意味着: (a) top-left of a plane, (b) top-left corner of a large vehicle diamond, © center of a baseball diamond.
除了OBB,每个实例还被标记为一个类别和一个困难,表明实例是否难以检测(1为困难,O为不困难)。对图像的注释保存在具有相同文件名的文本文件中。每一行表示一个实例。下面是一个图片注释的例子:
x1, y1, x2, y2, x3, y3, x4, y4, category, difficult
x1, y1, x2, y2, x3, y3, x4, y4, category, difficult
...
给出了图像采集数据、图像源和GSD的元数据。在第一行,给出了”收购日期”。在第二行,给出了Yimagesource’ (GoogleEarth, GF-2或JL-1)。第三行给出了地面采样距离(GSD),单位为米。如果缺少lacquisition dates’和’gsd’,则将其标注为’None’。
'acquisition dates':acquisition dates
'imagesource':imagesource
'gsd':gsd
在这里插入图片描述
Data Download
DOTA-v1.0
Task1– Detection with oriented bounding boxes
Task2– Detection with horizontal bounding boxes
其他情况说明
图片大小:800×800到4000×4000
1、DOTA 航拍数据集格式构建
DOTA数据集文件结构
mmrotate
├── mmrotate
├── tools
├── configs
├── data
│ ├── DOTA
│ │ ├── train
images
annfiles
│ │ ├── val
images
annfiles
│ │ ├── test
1、dataset dota settings
dataset_type = 'DOTADataset'
data_root = 'data/split_1024_dota1_0/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='RResize', img_scale=(1024, 1024)),
dict(type='RRandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1024, 1024),
flip=False,
transforms=[
dict(type='RResize'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'trainval/annfiles/',
img_prefix=data_root + 'trainval/images/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'trainval/annfiles/',
img_prefix=data_root + 'trainval/images/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'test/images/',
img_prefix=data_root + 'test/images/',
pipeline=test_pipeline))
2、split dota dataset(train\val\test)
将得到的 train、test、val 中的图片进行裁剪,裁剪的原因 是由于我的图像是1920×1080的矩形,而且也不是png格式的,所以找到:mmrotate-main/tools/data/dota/split/ 路径下img_split.py文件(裁剪脚本) 以及 mmrotate-main/tools/data/dota/split/split_configs/ 路径下的配置文件,其文件内容就是img_split.py的配置信息,我们需要修改其中的参数,让其加载上述的train、test、val中的图像及标签,并进行裁剪。

修改好上述几个关键的参数之后,即可运行img_split.py进行裁剪了:
; 1、请将原始图像裁剪成1024×1024的补丁,运行时重叠200个
python tools/data/dota/split/img_split.py --base-json \
tools/data/dota/split/split_configs/ss_trainval.json
python tools/data/dota/split/img_split.py --base-json \
tools/data/dota/split/split_configs/ss_test.json
2、如果您想获得一个多尺度数据集,可以运行以下命令
python tools/data/dota/split/img_split.py --base-json \
tools/data/dota/split/split_configs/ms_trainval.json
python tools/data/dota/split/img_split.py --base-json \
tools/data/dota/split/split_configs/ms_test.json
1、ss_train.json修改
{
"nproc": 10,
"img_dirs": [
"data/DOTA/dotav1/train/images/"
],
"ann_dirs": [
"data/DOTA/dotav1/train/obb_annfiles_v1/"
],
"sizes": [
1024
],
"gaps": [
200
],
"rates": [
1.0
],
"img_rate_thr": 0.6,
"iof_thr": 0.7,
"no_padding": false,
"padding_value": [
104,
116,
124
],
"save_dir": "data/DOTA/split_ss_dotav1/train/",
"save_ext": ".png"
}
请修改json中的img_dirs和ann_dirs。
其他 test、val、trainval数据集的裁剪同理,只需修改 – -base_json参数为对应的配置文件即可。
python tools/data/dota/split/img_split.py --base-json tools/data/dota/split/split_configs/ss_train.json
python tools/data/dota/split/img_split.py --base-json tools/data/dota/split/split_configs/ss_val.json
python tools/data/dota/split/img_split.py --base-json tools/data/dota/split/split_configs/ss_test.json

裁剪的结果:




3、更改数据集基础路径及训练、验证和测试路径
change data_root in configs/_base_/datasets/dotav1.py to split DOTA dataset.
dataset_type = 'DOTADataset'
data_root = 'data/DOTA/split_ss_dotav1/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='RResize', img_scale=(1024, 1024)),
dict(type='RRandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1024, 1024),
flip=False,
transforms=[
dict(type='RResize'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'train/annfiles/',
img_prefix=data_root + 'train/images/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'val/annfiles/',
img_prefix=data_root + 'val/images/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'test/images/',
img_prefix=data_root + 'test/images/',
pipeline=test_pipeline))
2、下载预训练模型权重文件

; 1、ReDet
1、mmrotate/configs/redet/redet_re50_refpn_1x_dota_le90.py 配置文件信息
_base_ = [
'../_base_/datasets/dotav1.py', '../_base_/schedules/schedule_1x.py',
'../_base_/default_runtime.py'
]
angle_version = 'le90'
model = dict(
type='ReDet',
backbone=dict(
type='ReResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
style='pytorch',
pretrained='work_dirs/pretrain/re_resnet50_c8_batch256-25b16846.pth'),
neck=dict(
type='ReFPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RotatedRPNHead',
in_channels=256,
feat_channels=256,
version=angle_version,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
roi_head=dict(
type='RoITransRoIHead',
version=angle_version,
num_stages=2,
stage_loss_weights=[1, 1],
bbox_roi_extractor=[
dict(
type='SingleRoIExtractor',
roi_layer=dict(
type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
dict(
type='RotatedSingleRoIExtractor',
roi_layer=dict(
type='RiRoIAlignRotated',
out_size=7,
num_samples=2,
num_orientations=8,
clockwise=True),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
],
bbox_head=[
dict(
type='RotatedShared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=15,
bbox_coder=dict(
type='DeltaXYWHAHBBoxCoder',
angle_range=angle_version,
norm_factor=2,
edge_swap=True,
target_means=[0., 0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2, 1]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='RotatedShared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=15,
bbox_coder=dict(
type='DeltaXYWHAOBBoxCoder',
angle_range=angle_version,
norm_factor=None,
edge_swap=True,
proj_xy=True,
target_means=[0., 0., 0., 0., 0.],
target_stds=[0.05, 0.05, 0.1, 0.1, 0.5]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
]),
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=0,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=2000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=[
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1,
iou_calculator=dict(type='BboxOverlaps2D')),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1,
iou_calculator=dict(type='RBboxOverlaps2D')),
sampler=dict(
type='RRandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)
]),
test_cfg=dict(
rpn=dict(
nms_pre=2000,
max_per_img=2000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
nms_pre=2000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(iou_thr=0.1),
max_per_img=2000)))
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='RResize', img_scale=(1024, 1024)),
dict(
type='RRandomFlip',
flip_ratio=[0.25, 0.25, 0.25],
direction=['horizontal', 'vertical', 'diagonal'],
version=angle_version),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
data = dict(
train=dict(pipeline=train_pipeline, version=angle_version),
val=dict(version=angle_version),
test=dict(version=angle_version))
optimizer = dict(lr=0.005)


3、修改配置文件
1、修改数据集的更改数据集基础路径及训练、验证和测试路径(如上所示)
2、修改数据的类别数
bbox_head=[
dict(
type='RotatedShared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=15,
bbox_coder=dict(
type='DeltaXYWHAHBBoxCoder',
angle_range=angle_version,
norm_factor=2,
edge_swap=True,
target_means=[0., 0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2, 1]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='RotatedShared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=15,
bbox_coder=dict(
type='DeltaXYWHAOBBoxCoder',
angle_range=angle_version,
norm_factor=None,
edge_swap=True,
proj_xy=True,
target_means=[0., 0., 0., 0., 0.],
target_stds=[0.05, 0.05, 0.1, 0.1, 0.5]),
reg_class_agnostic=False,
3、修改线程和batch_size(configs/ base /datasets/dotav1.py)
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'trainval/annfiles/',
img_prefix=data_root + 'trainval/images/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'trainval/annfiles/',
img_prefix=data_root + 'trainval/images/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'test/images/',
img_prefix=data_root + 'test/images/',
pipeline=test_pipeline))
4、修改训练epoches(configs_base_\schedules)
evaluation = dict(interval=12, metric='mAP')
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=1.0 / 3,
step=[8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)
checkpoint_config = dict(interval=12)
5、修改模型训练的日志打印和load from 加载与训练模型(configs_base_/default_runtime.py)
log_config封装了多个记录器挂钩,并允许设置间隔。现在MMCV支持WandbLoggerHook, MlflowLoggerHook和TensorboardLoggerHook。详细用法可以在文档中找到。
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook')
])
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook')
])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
opencv_num_threads = 0
mp_start_method = 'fork'
6、修改数据集的类别名称(mmrotate\datasets\dota.py)
@ROTATED_DATASETS.register_module()
class DOTADataset(CustomDataset):
"""DOTA dataset for detection.
Args:
ann_file (str): Annotation file path.
pipeline (list[dict]): Processing pipeline.
version (str, optional): Angle representations. Defaults to 'oc'.
difficulty (bool, optional): The difficulty threshold of GT.
"""
CLASSES = ('plane', 'baseball-diamond', 'bridge', 'ground-track-field',
'small-vehicle', 'large-vehicle', 'ship', 'tennis-court',
'basketball-court', 'storage-tank', 'soccer-ball-field',
'roundabout', 'harbor', 'swimming-pool', 'helicopter')
PALETTE = [(165, 42, 42), (189, 183, 107), (0, 255, 0), (255, 0, 0),
(138, 43, 226), (255, 128, 0), (255, 0, 255), (0, 255, 255),
(255, 193, 193), (0, 51, 153), (255, 250, 205), (0, 139, 139),
(255, 255, 0), (147, 116, 116), (0, 0, 255)]
7、修改图像数据集的后缀(修改mmrotate/mmrotate/datasets/dota.py)


数据集准备好之后,接下来,需要修改训练相关的配置信息:主要就是 tools/tain.py 中的相关参数修改,train.py文件如下:
两个主要的参数: - -config: 使用的模型文件 (我使用的是 faster rcnn) ; - -work-dir:训练得到的模型及配置信息保存的路径
由于使用的模型是:rotated_faster_rcnn_r50_fpn_x1_dota_le90.py,在该文件中实现了:训练相关参数的配置,数据集信息的配置,以及faster-rcnn网络架构的搭建;打开该文件修改其中的目标类别数为自己数据集的类别数,我的类别为1, 所以修改:num_classes = 1,

同时,修改 mmrotate-main/mmrotate/datasets/dota.py 文件中的类别名字(CLASSES), 具体如下

最后,修改训练使用的数据集路径:找到并打开 mmrotate-main/configs/base/datasets/dotav1.py 文件,修改其中的 data_root 路径为自己裁剪的数据集路径,该路径包含了上述划分的train、test、val、trainval数据集

8、修改模型的骨架网络backbone
1、将backbone由r50变为r101

; 2、将bacobone由r50变为r101


将用新密钥_delete_=True替换字段中的所有旧密钥backbone。
_base_ = '../mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py'
model = dict(
pretrained='open-mmlab://msra/hrnetv2_w32',
backbone=dict(
_delete_=True,
type='HRNet',
extra=dict(
stage1=dict(
num_modules=1,
num_branches=1,
block='BOTTLENECK',
num_blocks=(4, ),
num_channels=(64, )),
stage2=dict(
num_modules=1,
num_branches=2,
block='BASIC',
num_blocks=(4, 4),
num_channels=(32, 64)),
stage3=dict(
num_modules=4,
num_branches=3,
block='BASIC',
num_blocks=(4, 4, 4),
num_channels=(32, 64, 128)),
stage4=dict(
num_modules=3,
num_branches=4,
block='BASIC',
num_blocks=(4, 4, 4, 4),
num_channels=(32, 64, 128, 256)))),
neck=dict(...))
9、使用多尺度策略来训练 Mask R-CNN
配置文件中使用了一些中间变量,例如数据集中的train_pipeline/ test_pipeline。需要注意的是,修改子配置中的中间变量时,用户需要将中间变量重新传入相应的字段。例如,我们想使用多尺度策略来训练 Mask R-CNN。train_pipeline/test_pipeline是我们要修改的中间变量。
_base_ = './mask_rcnn_r50_fpn_1x_coco.py'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(
type='Resize',
img_scale=[(1333, 640), (1333, 672), (1333, 704), (1333, 736),
(1333, 768), (1333, 800)],
multiscale_mode="value",
keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
train=dict(pipeline=train_pipeline),
val=dict(pipeline=test_pipeline),
test=dict(pipeline=test_pipeline))
10、修改归一化层
Similarly, if we would like to switch from SyncBN to BN or MMSyncBN, we need to substitute every norm_cfg in the config.
_base_ = './mask_rcnn_r50_fpn_1x_coco.py'
norm_cfg = dict(type='BN', requires_grad=True)
model = dict(
backbone=dict(norm_cfg=norm_cfg),
neck=dict(norm_cfg=norm_cfg),
...)
5、模型训练
1、Train with a single GPU
python tools/train.py ${CONFIG_FILE} [optional arguments]
如果你想在命令中指定工作目录,你可以添加一个参数–work_dir $[YOUR_WORK_DIR]。
2、Train with multiple GPUs
./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
Optional arguments are:
–no-validate (not suggested): By default, the codebase will perform evaluation during the training. To disable this behavior, use –no-validate.
–work-dir ${WORK_DIR}: Override the working directory specified in the config file.
–resume-from ${CHECKPOINT_FILE}: Resume from a previous checkpoint file.
Difference between resume-from and load-from: resume-from loads both the model weights and optimizer status, and the epoch is also inherited from the specified checkpoint. It is usually used for resuming the training process that is interrupted accidentally. load-from only loads the model weights and the training epoch starts from 0. It is usually used for finetuning.
3、Train with multiple machines
•如果你启动了多台连接以太网的机器,你可以简单地运行以下命令:
On the first machine:
NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
On the second machine:
NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
如果你没有像InfiniBand这样的高速网络,通常会很慢。
4、Manage jobs with Slurm
如果在由slurm管理的集群上运行MMRotate,可以使用脚本slurm_train.sh。(此脚本也支持单机训练。)
[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR}
如果您有多台机器与以太网连接,您可以参考PyTorch启动实用程序添加链接描述。如果你没有像InfiniBand这样的高速网络,通常会很慢
5、在一台机器上启动多个作业
如果您在一台机器上启动多个作业,例如,在一台有8个gpu的机器上启动2个4-GPU训练的作业,您需要为每个作业指定不同的端口(默认为29500),以避免通信冲突。
If you use dist_train.sh to launch training jobs, you can set the port in commands.
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4
如果使用Slurm启动培训作业,则需要修改配置文件(通常是配置文件中倒数第6行)以设置不同的通信端口。
In config1.py,
dist_params = dict(backend=’nccl’, port=29500)
In config2.py,
dist_params = dict(backend=’nccl’, port=29501)
Then you can launch two jobs with config1.py and config2.py.
CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR}
CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR}
6、开始启动模型训练
python tools/train.py configs/redet/redet_re50_refpn_1x_dota_le90.py --work-dir work_dirs/runs/redet/


6、启动tensorboad查看模型训练
如果有在default_runtime中解除注释tensorboard,键入下面的命令可以开启实时更新的tensorboard可视化模块。
在config文件修改如下
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook')
])
设置之后,会在work_dir目录下生成一个tf_logs目录,使用Tensorboard打开日志
cd /path/to/tf_logs
tensorboard --logdir . --host 服务器IP地址 --port 6006
tensorboard --logdir work_dirs/runs/redet/tf_logs/ --host 10.1.42.60
tensorboard 默认端口号是6006,在浏览器中输入http://:6006即可打开tensorboard界面

7、测试模型
single GPU
single node multiple GPU
multiple node
可以使用以下命令推断数据集。
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [optional arguments]
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments] --launcher slurm
Examples:
•在DOTA-1.0数据集上推断RotatedRetinaNet,它可以生成在线提交的压缩文件。
python ./tools/test.py \
configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
checkpoints/SOME_CHECKPOINT.pth --format-only \
--eval-options submission_dir=work_dirs/Task1_results
./tools/dist_test.sh \
configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
checkpoints/SOME_CHECKPOINT.pth 1 --format-only \
--eval-options submission_dir=work_dirs/Task1_results
You can change the test set path in the data_root to the val set or trainval set for the offline evaluation.
python ./tools/test.py \
configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
checkpoints/SOME_CHECKPOINT.pth --eval mAP
或者
./tools/dist_test.sh \
configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
checkpoints/SOME_CHECKPOINT.pth 1 --eval mAP
You can also visualize the results.
python ./tools/test.py \
configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
checkpoints/SOME_CHECKPOINT.pth \
--show-dir work_dirs/vis
Original: https://blog.csdn.net/qq_41627642/article/details/125348037
Author: qq_41627642
Title: 旋转框目标检测mmrotate v0.3.1 训练DOTA数据集(二)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/719411/
转载文章受原作者版权保护。转载请注明原作者出处!