

分类算法:logistic回归
一、线性模型之回归
1、线性模型
线性模型一般形式为
由d个属性构成的实例x=(x1,x2,…,xd),xi表示x在第i个属性上的取值
线性模型试图学的一个通过属性的线性组合来进行预测的函数,一般形式为:


一般用向量形式写成:

w,b学得之后,模型就得以确定
很多功能更为强大得 非线性模型可在线性模型得基础上通过引入 层级结构或高位映射而得。
w,b是如何进行学习得到的呢
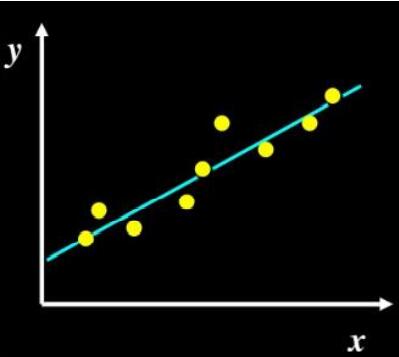
当x为一维数据时,如下图示,假设学习得到的模型就是图中得蓝线,学习得训练数据就是那些黄色的点,对每个黄色的点,模型会给出对应的预测值 f(xi),预测的点在线上
学习的过程就是更好的用模型(蓝线)去拟合这些黄色的点。
线性回归模型试图学习,使得

如何度量学习的好坏呢,在这里使用基于欧氏距离的均方误差最小化来进行学习,也称为” 最小二乘法“。
用D={(x1,y1), (x2,y2), …, (xm,ym)}l来表示黄色的点,计算每个预测值与黄色点的距离的平方,再累加求和,公式如下
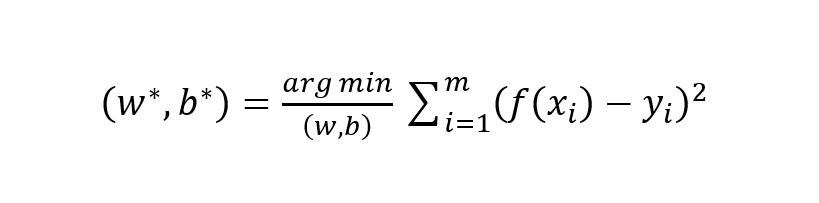
均方误差:
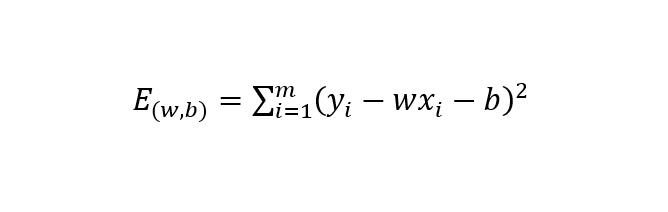
均方误差最小化的过程,称为模型的最小二乘”参数估计”,可对均方误差E(w,b)对w,b求偏导可得


当x为多维数据时,称为” 多元线性回归”
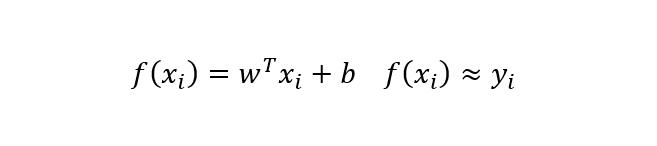
那如果f(xi)逼近的 yi 在空间中是非线性的呢,如何用输入映射非线性的输出呢。
例如对于yi 实际上yi的图像是 yi = e(wxi +b)
处理方法:可以对yi取对数,那么 ln(yi) = w xi + b , 以另w xi + b 逼近 yi的衍生物。
更一般的 考虑单调可微函数 g(·)令
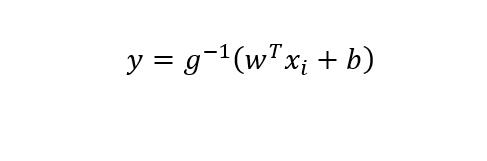
这样,就可以逼近非线性的值,成为” 广义线性模型“,其中函数g(·)称为”联系函数”,显然上面举例是 g(·)= ln(·)时的特例。
现在通过线性回归模型既可以逼近线性的值又可以逼近非线性的值
; 二、线性模型之分类
上面一节讨论了如何使用线性模型进行回归模型,但是要做的事分类任务该怎么办?答案就蕴含在上节最后提到的广义线性模型:只需要找 一个单调可微函数来将分类任务的真实标记y与线性回归模型的预测值联系起来。 –《机器学习》 周志华
1、logistic回归
考虑二分类任务,yi = {0,1} , 而 线性回归模型产生的预测值 z = w xi + b 是实值
于是考虑 将实值 z 转换为 0/1 值.最理想的是 “单位跃阶函数 “
单位跃阶函数
0 , z < 0
y = 0.5 , z = 0
1 , z > 0
但是已经提到,要求g(·)是单调可微的,显然单位阶跃函数是离散的
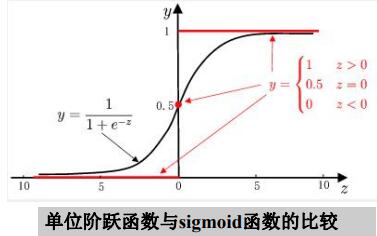
寻找一个替代函数,有逻辑斯蒂函数/对数几率函数(logistic function),是一种”Sigmoid函数”

图中左右,为同一个函数,即逻辑斯蒂函数。
可以看出实质上,是 预测结果 z 去逼近真实标记的对数几率 ,因此,对应的模型称为” 逻辑斯蒂/对数几率回归(logistic regression)“
对数几率就是 ln [ y /(1-y)]
现在模型构建好了,就可以用极大似然法来估计w,b(如果这句话看的懂可以跳过浅色线之间的内容。)
; 2、极大似然估计再理解
现在模型构建好了,那如何获得w,b呢
那完蛋啦了呀,那没办法了呀,我们手里只有训练数据,那只能用训练数据了
那训练数据有啥用呢,我们在干嘛呢,在研究这个训练数据能表示出什么知识(再通过模型把知识表示出来)。
哦,我看看,300个训练样本是1,700个训练样本是0,那请问 这种情况发生的概率是多少?
哦,那很简单 P(300个是1,700 个是0) = P(1) 的300次方 + P(0)的 700次方
取个对数就是 lnP(300个是1,700 个是0)= 300个 lnP(1)相加 + 700个lnP(0)相加
那是不是就是P(1)和P(0)不知道, P(0)又=1-P(1),那就是P(1)不知道。
假如我这时候告诉你 P(1)可能是0.3 0.5 0.7,请问你选哪一个? 那必然选择0.3
这是什么原理呢,这就是极大似然原理,事物所展现的状态就是所有状态中发生概率最大的状态。
三个中,选P(1)= 0.3,使得 (300个是1,700 个是0)这个状态发生概率最大
那没有假如咋把这个 P(1)求出来呢,这不是很简单嘛,函数求导,分析单调性,找到最大值点
求导之后发现,P(1)= 0.3,取最大值。确实和极大似然原理想印证。
所以极大似然估计到底是啥呢,用我的土话说,就是,收集到了所有样本的类别情况(比如300个是1,700 个是0这一情况),当我们模型的参数可以表示所有样本的类别情况时,用这个情况发生概率最大的条件,找到使这个概率最大的参数,反过来说,当参数取得某值使得概率最大时,那么这个取值是所求得值。
刚才是用P(1)来表示了发生概率最大的情况得概率,那么只要用w,b将这个概率表达出来,就可以求得w,b。
3、极大似然估计参数
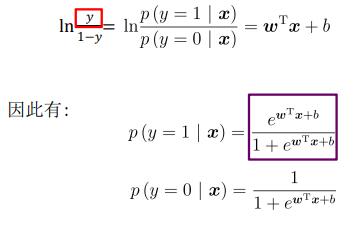
于是(第一个)似然函数(即最大化概率的表达式),即

为便于讨论,令

则

于是似然函数,又等于

此处第二个似然函数是不等于第一个似然函数的。
具体情况为 将p(yi | xi;wi,b)中的红框项和篮框项先取倒数,得到新的p(yi | xi;wi,b),再将新的p(yi | xi;wi,b)代入第一个似然函数,容易理解此时是最小化第二个似然函数
下面就要一步一步的逼近似然函数的最小值,来找到β。
第二个似然函数是高阶可导连续凸函数,根据凸优化理论,经典的数值优化算法如梯度下降法、牛顿法等都可求得其最优解

下面就要一步一步的逼近似然函数的最小值,来找到β。

Logistic回归优点:
1、无需事先假设数据分布
2、可得到”类别”得近似概率分布(概率值还可以用于后续应用)
3、可直接应用现有数值优化算法(如牛顿法)求取最优解,具有快速、高效得特点。
; 4、实战
一般过程
1、收集数据
2、准备数据
3、分析数据
4、训练算法,找到最佳得参数
5、测试算法,
6、使用算法
实验出了很大的问题,我已经不想写了,以后再写吧
data = pd.read_csv("heart.csv")
data = np.array(data)
labels = data[:,13]
data = np.mat(data)
def sigmoid(inx):
return 1.0/(1+np.exp(-inx))
def stocGradAscent1(dataMatIn, classLabels):
#梯度上升法
dataMatrix=np.mat(dataMatIn)
labelMat=np.mat(classLabels).transpose()
m,n=np.shape(dataMatrix)
alpha=0.001 #步长
maxCycles=500 #迭代次数
weights=np.ones((n,1)) #初始回归系数
for k in range(maxCycles):
h=sigmoid(dataMatrix*weights)
error=(labelMat-h)
weights=weights+alpha*dataMatrix.transpose()*error
return weights #返回回归系数
def classify2(data,weights):
m,n = np.shape(data)
z_all = []
error = 0
for j in range(m):
z = sigmoid(np.sum(data[j]*weights))
if z >0.5:
z=1
else:
z=0
if z != labels[j]:
error =error+1
z_all.append(z)
errorate = error/float(m)
print(errorate)
return z_all,errorate
weights2 = stocGradAscent1(data,labels)
m2,c = classify2(data,weights2)
错误率 有39.60%,基本上都分类成1。
Original: https://blog.csdn.net/Lixiaoyyyu/article/details/121579030
Author: Lixiaoyyyu
Title: 【机器学习实战 4】、基于最优化线性回归的分类算法:logistic回归
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/665332/
转载文章受原作者版权保护。转载请注明原作者出处!