

目录
- 一、 分类与聚类
* - 1、分类
- 2、聚类
– - 二、K-Means聚类
* - 1、定义、优点
- 2、k-means聚类算法的分析流程:
- 3、K-Means优缺点
- 4、代码实现
- 三、 层次聚类
* - 1、定义
- 2、凝聚层次聚类的流程
- 3、层次聚类的优缺点
- 4、示例
- 5、树状图分类判断
- 6、示例代码
- 四、密度聚类
* - 1、算法
- 2、优缺点
- 3、示例代码
- 五、扩展–谱聚类
* - 1、算法步骤
一、 分类与聚类
1、分类
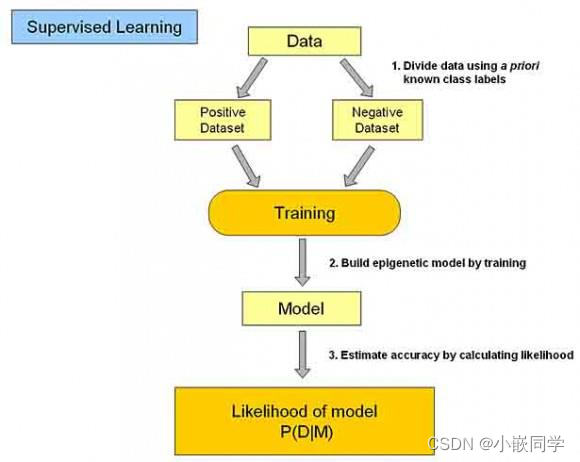
分类其实是 从特定的数据中挖掘模式,作出判断的过程。
分类学习主要过程:
(1)训练数据集存在一个类标记号,判断它是正向数据集(起积极作用,不垃圾邮件),还是负向数据集(起抑制作用,垃圾邮件);
(2)然后需要对数据集进行学习训练,并构建一个训练的模型;
(3)通过该模型对预测数据集进预测,并计算其结果的性能。

; 2、聚类
从广义上说,聚类就是 将数据集中在某些方面相似的数据成员放在一起。
一个聚类就是一些数据实例的集合,其中处于相同聚类中的数据元素彼此相似,但是处于不同聚类中的元素彼此不同。
由于在聚类中那些表示数据类别的分类或分组信息是没有的, 即这些数据是没有标签的,所以 聚类通常被归为无监督学习(Unsupervised Learning),分类使用的数据大多数是有标签的,称为有监督学习。
聚类的目的也是把数据分类,但是事先是不知道如何去分的,完全是算法自己来判断各条数据之间的相似性,相似的就放在一起。
在聚类的结论出来之前,完全不知道每一类有什么特点,一定要根据聚类的结果通过人的经验来分析,看看聚成的这一类大概有什么特点。
总之,聚类主要是”物以类聚”,通过相似性把相似元素聚集在一起,它没有标签;而分类通过标签来训练得到一个模型,对新数据集进行预测的过程,其数据存在标签。
聚类样本间的属性
- 有序属性:西瓜的甜度: 0.1,0.5,0.9
- 无序属性:性别:男,女
聚类的常见算法
聚类算法分为三大类:
- 原型聚类:
• K均值聚类算法 - 层次聚类
- 密度聚类
二、K-Means聚类
1、定义、优点
K-Means聚类是最常用的聚类算法,最初起源于信号处理,其目标是将数据点划分为K个类簇。
该算法的 最大优点是简单、便于理解,运算速度较快,缺点是要在聚类前指定聚集的类簇数。
k-means算法是一种原型聚类算法。
2、k-means聚类算法的分析流程:
第一步,确定K值,即将数据集聚集成K个类簇或小组。
第二步,从数据集中随机选择K个数据点作为质心(Centroid)或数据中心。
第三步,分别计算每个点到每个质心之间的距离,并将每个点划分到离最近质心的小组。
第四步,当每个质心都聚集了一些点后,重新定义算法选出新的质心。(对于每个簇,计
算其均值,即得到新的k个质心点)
第五步,迭代执行第三步到第四步,直到迭代终止条件满足为止(聚类结果不再变化)
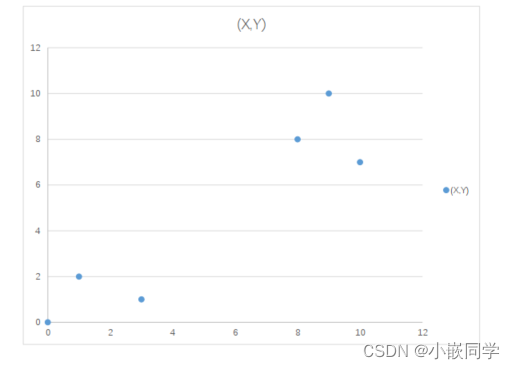
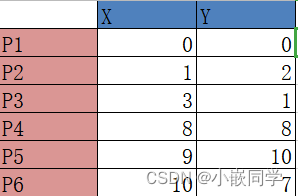
第一步,确定K值,即将数据集聚集成K个类簇或小组。
第三步,分别计算每个点到每个质心之间的距离,并将每个点划分
到离最近质心的小组。
(2+1+8+10+7) /5) =(6.2, 5.6)。
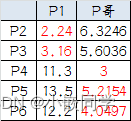
再次计算点到质心的距离:
这时可以看到P2、 P3离P1更近, P4、 P5、 P6离P哥更
近。
第二次分组的结果是:
• 组A: P1、 P2、 P3
• 组B: P4、 P5、 P6(虚拟质心这时候消失)
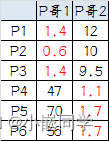
`c
按照上一次的方法选出两个新的虚拟质心:
P5、 P6离P哥2更近。
Original: https://blog.csdn.net/weixin_45842280/article/details/125011128
Author: 小嵌同学
Title: 图像聚类算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/718839/
转载文章受原作者版权保护。转载请注明原作者出处!