

目录
*
– 1. 文章主要内容
– 2. KNN算法(K近邻算法)
–
+ 2.1 定义(大白话)
+ 2.2 欧拉距离
+ 2.3 KNN算法原理(通过上图和下图解释)
+ 2.4 通过例子验证KNN算法(加深对原理的掌握)
– 3. 总结
– 4. 源代码整合
1. 文章主要内容
本篇博客致力于讲解<
2. KNN算法(K近邻算法)
2.1 定义(大白话)


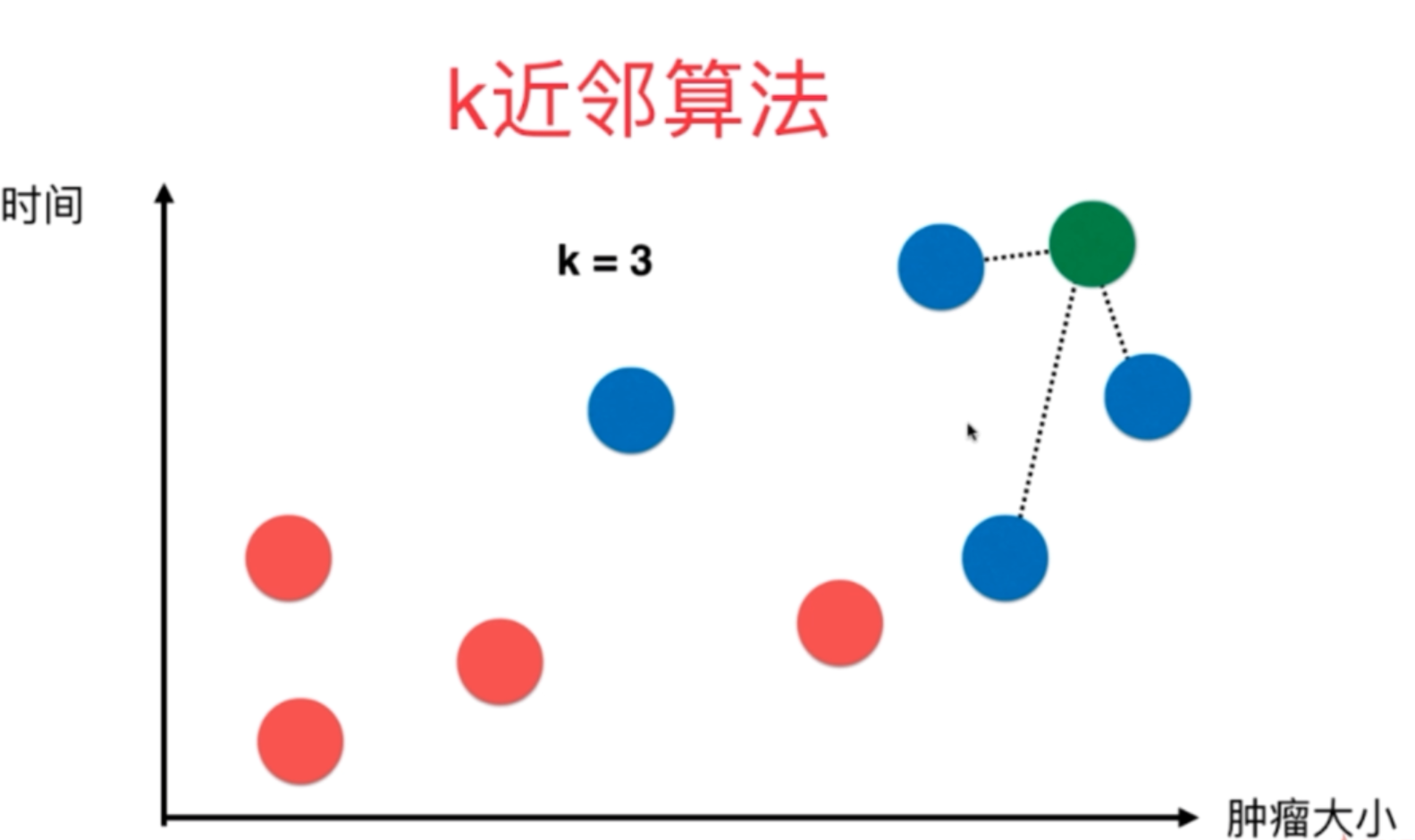
根据上图,我们说明几个注意事项。首先,在直角坐标系中,红色和蓝色的圆球是分别代表两个不同的种类。其次,绿色的圆球则是新来的一个球(可以理解成新来的数据)。我们需要通过KNN算法来判断新进来绿色的圆球属于红色类别还是蓝色的类别。
; 2.2 欧拉距离
在讲解KNN原理之前我们首先来认识一个概念,就是 欧拉距离。其实欧拉距离在我们高中的时候就经常被用到,比如计算平面上两点的距离等。
我们假设二维平面上有两个点分别是(x a , y a x_{a},y_{a}x a ,y a )、(x b , y b x_{b},y_{b}x b ,y b ),那么其在二维平面上的公式可以表示为:( x a − x b ) 2 + ( y a − y b ) 2 \sqrt {(x_{a}-x_{b})^2+(y_{a}-y_{b})^2}(x a −x b )2 +(y a −y b )2 。
在三维立体空间中公式可以表示为:( x a − x b ) 2 + ( y a − y b ) 2 + ( z a − z b ) 2 \sqrt {(x_{a}-x_{b})^2+(y_{a}-y_{b})^2+(z_{a}-z_{b})^2}(x a −x b )2 +(y a −y b )2 +(z a −z b )2 。
推广到n个维度平面上公式可以表示为:(因为上标的a和b找不到相应公式编辑器。这个公式说明几点:a和b代表两个点,X下标的1~n是一共有n个维度。整个公式的意思就是:两个点a和b在n个维度上的欧拉距离)
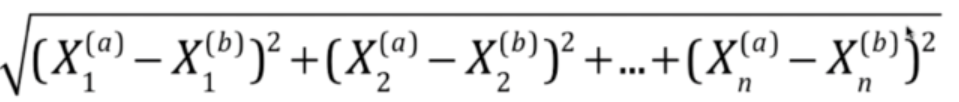
用求和的公式表示上面的公式,即可得到下面的公式,这也正是我们之后需要用到的欧拉距离一般公式。至此,我们已经简单介绍完欧拉公式的概念。

2.3 KNN算法原理(通过上图和下图解释)
KNN算法需要取一个k值,我们假设将k取3,那么对于上图绿圆球点来说:K近邻算法会寻找所有数据点,直到找到与绿色圆球距离(这里的距离计算使用的就是欧拉距离)最近的三个点。通过分析这三个点,看蓝色和红色圆球的占比,谁更大,那么新进来的绿圆球就属于这个类别。
从下图可以知道,离绿圆球最近的三个点都是蓝色圆球,那么新进来的绿色圆球就属于蓝色圆球的类别。至此,我们已经用大白话讲清了KNN算法的实现过程,更详细的参数或者实现步骤需要自行网上搜索。
接下来我们会用一个数据集来验证KNN算法原理的过程。其中需要提前搭建好Python、Anconda和Jupyter Notebook等环境(请参考搭建Anaconda、JupyterNoteBook相关环境),并知悉Python的基础知识即可。
我们通过逐步代码分解来解释说明,在文章的最后会给出源代码的整块部分,以便于复现代码。
; 2.4 通过例子验证KNN算法(加深对原理的掌握)
- 首先我们导入需要的numpy和matplotlib的包,其中numpy用来作矩阵的运算,而matplotlib用来进行绘图。
import numpy as np
import matplotlib.pyplot as plt
- raw_data_X、raw_data_y为本次例子使用的源数据,其中raw_data_X的shape是(10,2),而raw_data_y的shape为(1,10)。
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
- 由于上面的源数据是Python当中的list类型,numpy科学数据包适用于array的类型,所以我们使用np.array()进行转换即可。
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
- 如下的两行代码整体意思是:将raw_data_X的列方向的第一维度当做直角坐标系的x轴,而其第二维度当做直角坐标系的y轴。raw_data_X一共有十个样本数据,所以总共描述十个点。
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='g')
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='r')
plt.show()

注意:解释一下上面两行代码的具体流程。首先从总体来看plt.scatter(x,y,color)。然后,我们以X_train[y_train==0,0]为例说明:当y_train == 0 的时候,我们输出的值为:(y_train原本的值为:array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1]))。
array([ True, True, True, True, True, False, False, False, False,
False])
此时,我们会取array当中为True值的索引。从这个例子来说,就是前五位也就是0,1,2,3,4。然后可以得到X_train[0,0]~X_train[1,0],其中X_train后面那个0是代表取X_train的第一维度,如果为1就是取第二维度。
举个例子:X_train[0,0]取的就是3.393533211,而X_train[0,1]取的就是 2.331273381。同理后面的X_train是一样的分析原理。
- 如同4操作一样,我们把新来的数据点x也一同画到坐标系中。(其中蓝色点代表x数据,也就是新的数据)
x = np.array([8.093607318, 3.365731514])
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='g')
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='r')
plt.scatter(x[0],x[1],color='b')
plt.show()

6. 正如第二大点的欧拉公式的求解公式一样,我们通过代码实现其求和的距离公式。其中sqrt代表开根号,sum代表求和,**2代表平方。
from math import sqrt
distances = []
for x_train in X_train:
d = sqrt(np.sum(x_train-x)**2)
distances.append(d)
从而可以将坐标系上所有点与x点的距离求出来存放到distances数据当中,结果如下所示:
[5.734532240000001,
6.5677257110000005,
6.747169047,
3.1978656800000005,
6.31198613,
0.6606209850000004,
2.1802970320000004,
0.2239308349999991,
0.24246641000000047,
2.727880784]
- 从KNN算法原理得知,我们需要求解x与所有点的距离,从而求出与最小的k个点的距离。所以谈到最小,我们首先想到的是排序,首先将distances进行从小到大的排序。我们这里使用numpy的argsort()从小到大排序,得到的结果是原distances的索引值。举个例子,索引值为7在distances为0.2239308349999991,即是distances最小的元素,同理其他一样的排序取值。
np.argsort(distances)
array([7, 8, 5, 6, 9, 3, 0, 4, 1, 2], dtype=int64)
- 我们这里取k=6,意思就是与x数据距离最近的6个点。然后取出这6个点的类别,也就是对应y的值。
nearset = np.argsort(distances)
k = 6
topK_y = [y_train[neigbor] for neigbor in nearset[:k]]
topK_y
由此求出的topK_y也就是这6个点对应的y值,如下所示:
[1, 1, 1, 1, 1, 0]
- 我们将topK_y进行比例的转换,以便于我们进行类别比率的比较,这里使用Counter()方法即可。
from collections import Counter
votes = Counter(topK_y)
votes
Counter({1: 5, 0: 1})
- 我们发现1的比例比0要高,所以通过votes.most_common(1)取出第一大的数值,如下所示:
votes.most_common(1)
[(1, 5)]
- 最后我们取出[(1, 5)]中的1,就是新来数据x的类别(这也是KNN算法得出来x的类别)。至此,我们通过举例,实践了KNN算法的原理的过程。
predict_y = votes.most_common(1)[0][0]
predict_y
1
3. 总结
通过本篇博客,讲解了KNN的定义、算法原理,以及通过一个小例子来加深对KNN的理解。下一篇博客,会继续讲解KNN算法以及在Scikit-Learn当中如何调用KNN算法。如有错误,欢迎大家指正,谢谢!
4. 源代码整合
import numpy as np
import matplotlib.pyplot as plt
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='g')
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='r')
plt.show()
x = np.array([8.093607318, 3.365731514])
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='g')
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='r')
plt.scatter(x[0],x[1],color='b')
plt.show()
from math import sqrt
distances = []
for x_train in X_train:
d = sqrt(np.sum(x_train-x)**2)
distances.append(d)
distances
np.argsort(distances)
nearset = np.argsort(distances)
k = 6
topK_y = [y_train[neigbor] for neigbor in nearset[:k]]
topK_y
from collections import Counter
votes = Counter(topK_y)
votes
votes.most_common(1)
predict_y = votes.most_common(1)[0][0]
predict_y
Original: https://blog.csdn.net/qq_32575047/article/details/121588844
Author: 弗兰随风小欢
Title: <<从零入门机器学习>> 最基础的分类的算法-KNN(K近邻算法)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/665047/
转载文章受原作者版权保护。转载请注明原作者出处!