

KNN
K-Nearest Neighbors
简单类比(Simple Analogy)
KNN:通过你周围的人来判断你是哪一类人
Tell me about your friends(who your neighbors are ) and I will tell you who you are


; 背景
KNN – K-Nearest Neighbors 别名:
- Memory-Based Reasoning
- Example-Based Reasoning
- Instance-Based Learning
- Lazy Learning
KNN在模式识别和数据挖掘领域有着非常广泛的应用;KNN利用某种相似性度量方案(常见的比如距离函数)对周围对结点进行度量,从而确定当前结点所属对类别。没错,它是一种分类算法,并且是无参数化的懒惰的学习算法。
K nearest neighbors stores all available cases and classifies new cases based on a similarity measure (e.g distance function)
说KNN懒惰是因为它不做任何的抽象和泛化,仅仅使用一种特定的相似性度量方案,不需要学习任何东西。
Using a strict definition of learning, in which the learner summarizes raw input into a model (equations, decision trees, clustering, if then rules), a lazy learner is not really learning anything.
与其他学习算法不一样,KNN在训练的时候只需要花费很短的时间,它只是存储训练数据,但是在测试的时候需要花费较长的时间;也不需要建立模型。这点和其他学习算法正好相反。
KNN使用多数投票的方式对新的样本进行分类,在邻近的K个样本中,某一类的样本个数最多,那么就新样本就属于这一类。
An object (a new instance) is classified by a majority votes for its neighbor classes.
The object is assigned to the most common class amongst its K nearest neighbors.(measured by a distant function)

比如在上面这个图种,绿色的新样本就被分类成B类。
KNN
前面说过KNN是一种懒惰的学习算法,对新样本进行分类是通过对邻近样本使用某种相似性指标得到的,并且是采用多数投票对方式。
那么这就有两个问题,第一:邻近样本中的”邻近”是如何定义的?第二:相似性度量指标是啥?
先来看第一个问题。KNN中的K就是解决这个问题的,K的值代表了取新样本周围最近邻居的数目。
“K” stands for number of data set items that are considered for the classification.

对于第二个问题,相似性度量指标一般用的是距离函数,即选择距离新样本最近的邻居。
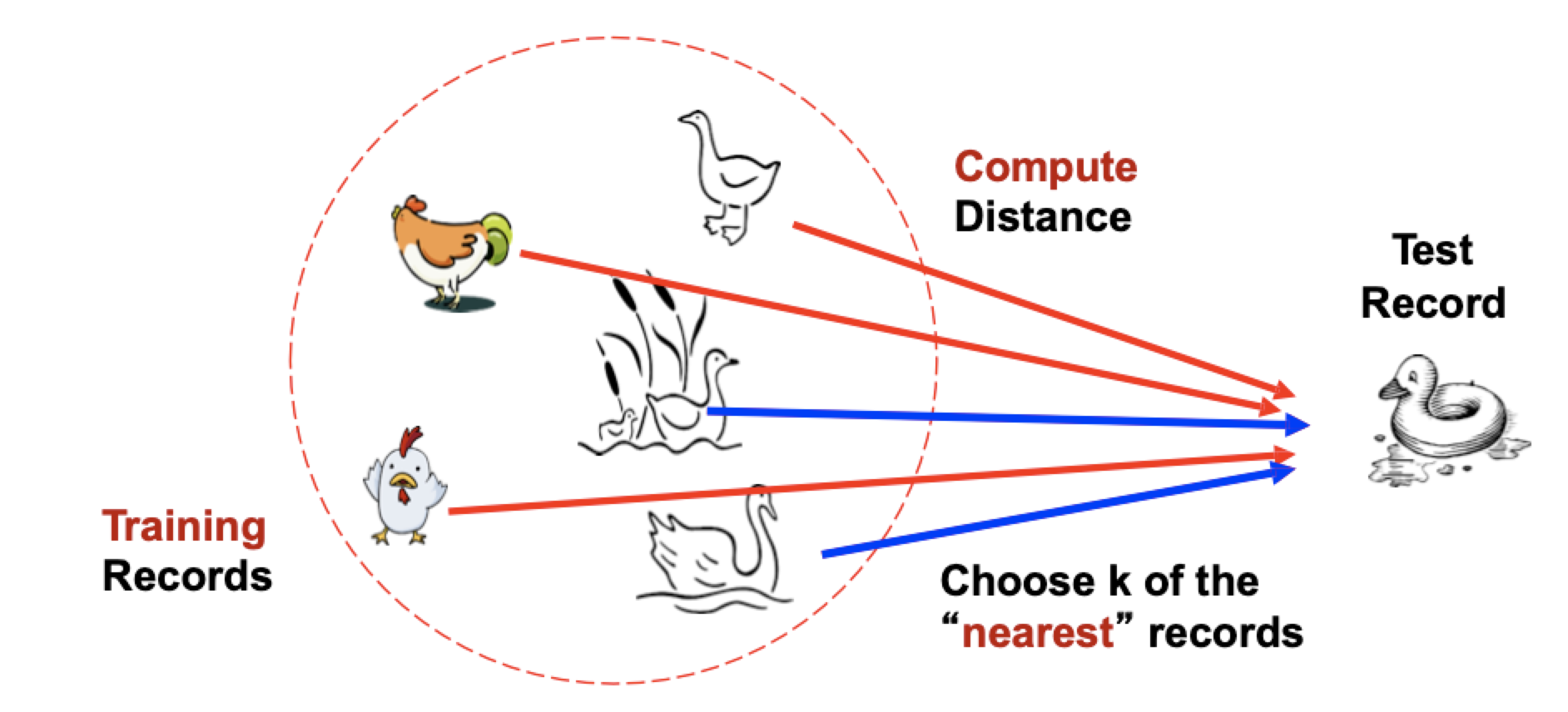
如上图,左边是已经存储好的训练集,对于测试集中的每个样本都与训练集的样本计算距离,然后选择K个最近的训练集样本,接着在选择好的训练集样本中使用多数投票的方式来对测试集数据进行分类。
听起来好像没啥问题,但是这其中隐含了两个问题。第一,距离如何算?第二,从上面对流程能看出,KNN对时间复杂度是O(n2)。
第二个问题好像没啥解决办法,因为这是KNN本身的缺点。那如何计算距离呢?
- 欧几里得距离(Euclidean)

- 曼哈顿距离(Manhattan)

好的,到目前为止,已经讨论完了KNN算法的完整流程了,小结一下吧:
- 所有的样本都是在一个n维的空间中的
- 每个样本由数字类型的属性和标签组成
- 选择距离新样本最近的K个训练集样本
- 找出这K个样本里出现次数最多的标签
那么这个k值如何选择呢?或者说它的值对算法性能有什么影响呢?
- K值太小对话,算法对异常值就非常敏感。举个极端的例子,k=1,并且距离新样本最近的样本点是一个误分类点。
- 稍大点的k比较好,但是如何很大又回包含很多其他类大样本点。
- 根据经验,k < sqrt(n),n是训练集样本的个数。并且最好选择奇数(二分类)。
从上面的描述可以得到如下结论:
- k太小的话,模型的bias小, _variance_高,过拟合,高复杂度。
- 随着k增大,bias增大,variance减小,走向欠拟合,低复杂度。
- 可以使用crass_validation来调整k值。
这部分可以参考下: KNN和K-means的区别 为什么KNN算法里的K越小模型会越复杂? 过拟合和欠拟合的偏差和方差问题 ( https://blog.csdn.net/yanni0616/article/details/100008763 )
直观地理解,过拟合就是学习到了很多”局部信息”,或者是”噪音”,使得我们的模型中包含很多”不是规律的规律”。在knn算法中,k越小,就越有可能让我们的学习结果被”局部信息”所左右。在极端情况下,k=1,knn算法的结果只由离我们待预测样本最近的那个点决定,这使得我们knn的结果高概率被”有偏差的信息”或者”噪音”所左右,是一种过拟合。
最后贴一下优缺点吧。

; 结语
这篇文章介绍了knn的一些基本问题,花了大概一个半小时的时间整理,图片都是来自于上课老师的ppt。考虑了许久要不要加sklearn的实现,如果加了是不是还要弄个不用sklearn的实现方案,但是想到这个东西遍地都是,懒得写了。
当然还有一些东西本文并未涉及到,比如说距离函数那里使用的都是数字类型的特征,如果特征是二分类的呢?如果是string呢?其实也有相应的衡量指标的,没加的原因主要是因为感觉没必要,因为我的初衷是为了应付期末考试的哈哈哈。
吐槽一下,notion笔记贴到csdn操作不友好。
Original: https://blog.csdn.net/williamgavin/article/details/122766486
Author: williamgavin
Title: 机器学习(二)— KNN(K-Nearest Neighbors)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/664437/
转载文章受原作者版权保护。转载请注明原作者出处!