

YOLO系列 — YOLOV7算法(一):使用自定义数据集跑通YOLOV7算法
这不就尴尬了。。。刚理解完美团出的YOLO V6算法,V7就出来了。。。而且最关键的是V7还有V4作者的背书,不过好在其实V6和V7都是在YOLO V5的基础上修改的代码,所以代码读起来就比较顺畅。YOLOV7算法打算按照以下的结构进行讲解:
- YOLOV7算法(一):使用自定义数据集跑通YOLOV7算法(包括对整个项目文件作用的解读)
- YOLO系列 — YOLOV7算法(二):YOLO V7算法detect.py代码解析
- YOLO系列 — YOLOV7算法(三):YOLO V7算法train.py代码解析
- YOLO系列 — YOLOV7算法(四):YOLO V7算法网络结构解析
- 训练过程中的重要代码解析
- YOLO系列 — YOLOV7算法(六):YOLO V7算法onnx模型部署
- YOLO系列 — YOLOV7算法(七):YOLOV7算法总结


; 一、YOLO V7算法项目文件剖析
代码链接:YOLO V7
首先,从git上clone下来整个项目文件夹,如下图所示:
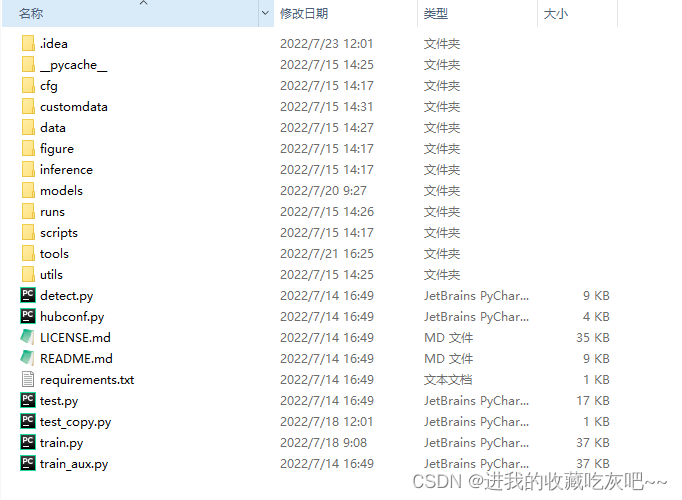
分别介绍下重要的文件夹和文件的作用:
- cfg:存放训练所需要的网络结构yaml文件
- customdata:这个文件夹是存放用户自定义数据集,这是我后来训练v7的时候创建的,刚下载的时候是没有的
- data:存放训练过程中超参数和训练相关data的yaml文件
- models:存放的是定义网络结构的相关python文件和导出模型部署所需要的代码
- runs:存放训练和测试的权重文件和相关信息
- utils:存放一些代码运行中必备的代码
- detect.py:用于测试的脚本
- requirement.txt:训练和测试所需要下载的库
- train.py:用于开启训练的脚本
; 1、创建训练环境
一般,我推荐大家都使用conda或者miniconda去创建虚拟环境去训练模型,这样不仅能隔离出本机环境,避免污染本机的环境。而且还避免了创建训练环境的时候下载相应的库版本之间出现问题。conda或者miniconda的具体安装方法直接找度娘,上面一大堆,这里我就不赘述了~
下载好conda之后:
conda create -n yolov7 python=3.7
conda activate yolov7
pip install -r your_yolov7_path/requirement.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
目前来说,yolo v7的作者貌似也没有指定python的版本,这里我就选择了3.7版本(笔者使用3.7是不报错的)。
2、创建自定义数据集
上述中有一个文件夹:customdata,该文件夹就是自定义数据集的存放路径。
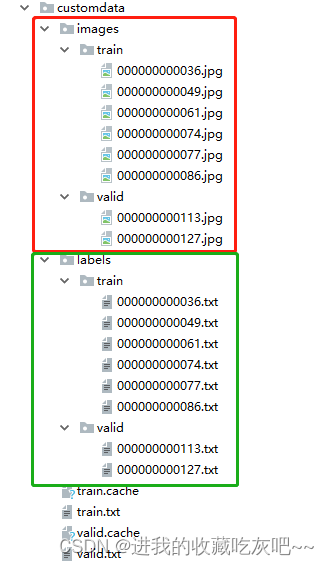
上图就是具体的存放规则,这里为了简便只使用了几张图片。分别创建images和labels文件夹来分别存放训练train和测试valid的图片和标签。下面可以使用我提供的代码来创建train.txt和valid.txt。
import glob
train_image_path = r"your_yolov7_path/customdata/images/train/"
valid_image_path = r"your_yolov7_path/customdata/images/valid/"
txt_path = r"your_yolov7_path/customdata/"
def generate_train_and_val(image_path, txt_file):
with open(txt_file, 'w') as tf:
for jpg_file in glob.glob(image_path + '*.jpg'):
tf.write(jpg_file + '\n')
generate_train_and_val(train_image_path, txt_path + 'train.txt')
generate_train_and_val(valid_image_path, txt_path + 'valid.txt')
3、开启训练
首先,在 your_yolov7_path/data里面创建一个custom_data.yaml文件,写入:
train: your_yolov7_path/customdata/train.txt
val: your_yolov7_path/customdata/valid.txt
test: your_yolov7_path/customdata/valid.txt
nc:
names: []
其中 nc和 names根据自己自定义数据集进行修改。
然后,打开要选择的网络结构yaml文件,这里我就选择 cfg/training/yolov7.yaml,修改 nc的值。
最后,打开train.py文件,根据自己的需求进行适当的参数修改:
parser.add_argument('--weights', type=str, default='', help='initial weights path')
parser.add_argument('--cfg', type=str, default=r'cfg/training/yolov7x.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/custom_data.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.p5.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=24, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
python train.py
搞定!!!
Original: https://blog.csdn.net/weixin_42206075/article/details/125947437
Author: 进我的收藏吃灰吧~~
Title: YOLO系列 — YOLOV7算法(一):使用自定义数据集跑通YOLOV7算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/668377/
转载文章受原作者版权保护。转载请注明原作者出处!