

目录
常见的决策树算法有ID3、C4.5和CART算法。ID3算法,是由澳大利亚计算机科学家Quinlan在1986年提出的,它是经典的决策树算法之一。ID3算法在选择划分节点的属性时,使用信息增益来选择。由于ID3算法不能处理非离散型特征,而且由于没有考虑每个节点的样本大小,所以可能导致叶子节点的样本数量过小,往往会带来过拟合的问题。C4.5算法是对ID3算法的进一步改进,它够进行处理不连续的特征,在选择划分节点的属性时,使用信息增益率来选择。因为信息增益率考虑了节点分裂信息,所以不会过分偏向于取值数量较多的离散特征。ID3算法和C4.5算法主要用来解决分类问题,不能用来解决回归问题,而CART(Classification And Regression Tree)算法则能同时处理分类和回归问题。CART算法在解决分类问题时,使用Gini系数(基尼系数)的下降值,选择划分节点属性的度量指标;在解决回归问题时,根据节点数据目标特征值的方差下降值,作为节点分类的度量标准。
本文章的内容是对书籍《Python机器学习算法与实战》(博文视点出品)——孙玉林,余本国著,中决策树数据分类小节的内容展示。下面将会介绍如何使用Python中的Sklearn库,完成决策树的分类任务。


书籍封面
1 决策树模型数据分类
建立决策数据分类模型时,使用预处理好的泰坦尼克数据集,预处理好的数据使用下面的方式进行数据切分:
import seaborn as sns
sns.set(font= "Kaiti",style="ticks",font_scale=1.4)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.tree import *
from sklearn.metrics import *
from io import StringIO
import graphviz
import pydotplus
定于预测目标变量名
Target = ["Survived"]
## 定义模型的自变量名
train_x = ["Pclass", "Name", "Sex", "Age", "SibSp", "Parch",
"Fare","Embarked", "IsAlone"]
##将训练集切分为训练集和验证集
定于预测目标变量名
Target = ["Survived"]
## 定义模型的自变量名
train_x = ["Pclass", "Name", "Sex", "Age", "SibSp", "Parch",
"Fare","Embarked", "IsAlone"]
##将训练集切分为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(
train_pro[train_x], train_pro[Target],
test_size = 0.25,random_state = 1)
print("X_train.shape :",X_train.shape)
print("X_val.shape :",X_val.shape)
print(X_train.head())
Out[9]:
X_train.shape : (668, 9)
X_val.shape : (223, 9)
Pclass Name Sex Age SibSp Parch Fare Embarked IsAlone
35 1 2 1 42.0 1 0 52.0000 2 0
46 3 2 1 31.2 1 0 15.5000 1 0
453 1 2 1 49.0 1 0 89.1042 0 0
291 1 3 0 19.0 1 0 91.0792 0 0
748 1 2 1 19.0 1 0 53.1000 2 0
对训练集切分后可发现,训练集中会有668个样本进行模型训练,剩下的样本进行模型的泛化能力验证。
首先使用DecisionTreeClassifier()函数中的默认参数建立一个决策树模型,并计算在训练集和验证集上的预测精度,程序如下所示:
## 先使用默认的参数建立一个决策树模型
dtc1 = DecisionTreeClassifier(random_state=1)
## 使用训练数据进行训练
dtc1 = dtc1.fit(X_train, y_train)
## 输出其在训练数据和验证数据集上的预测精度
dtc1_lab = dtc1.predict(X_train)
dtc1_pre = dtc1.predict(X_val)
print("训练数据集上的精度:",accuracy_score(y_train,dtc1_lab))
print("验证数据集上的精度:",accuracy_score(y_val,dtc1_pre))
训练数据集上的精度: 0.9910179640718563
验证数据集上的精度: 0.726457399103139
从程序的输出结果中可以发现:建立的模型在训练数据集上的精度为0.99,而在验证集上的精度就只有0.72,这是很明显的模型过拟合信号。为了更直观的展示过拟合决策树的情况,可以将其结果可视化分析,使用下面的程序获得如图1所示的过拟合决策时的结构图。
## 将获得的决策树结构可视化
dot_data = StringIO()
export_graphviz(dtc1, out_file=dot_data,
feature_names=X_train.columns,
filled=True, rounded=True,special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
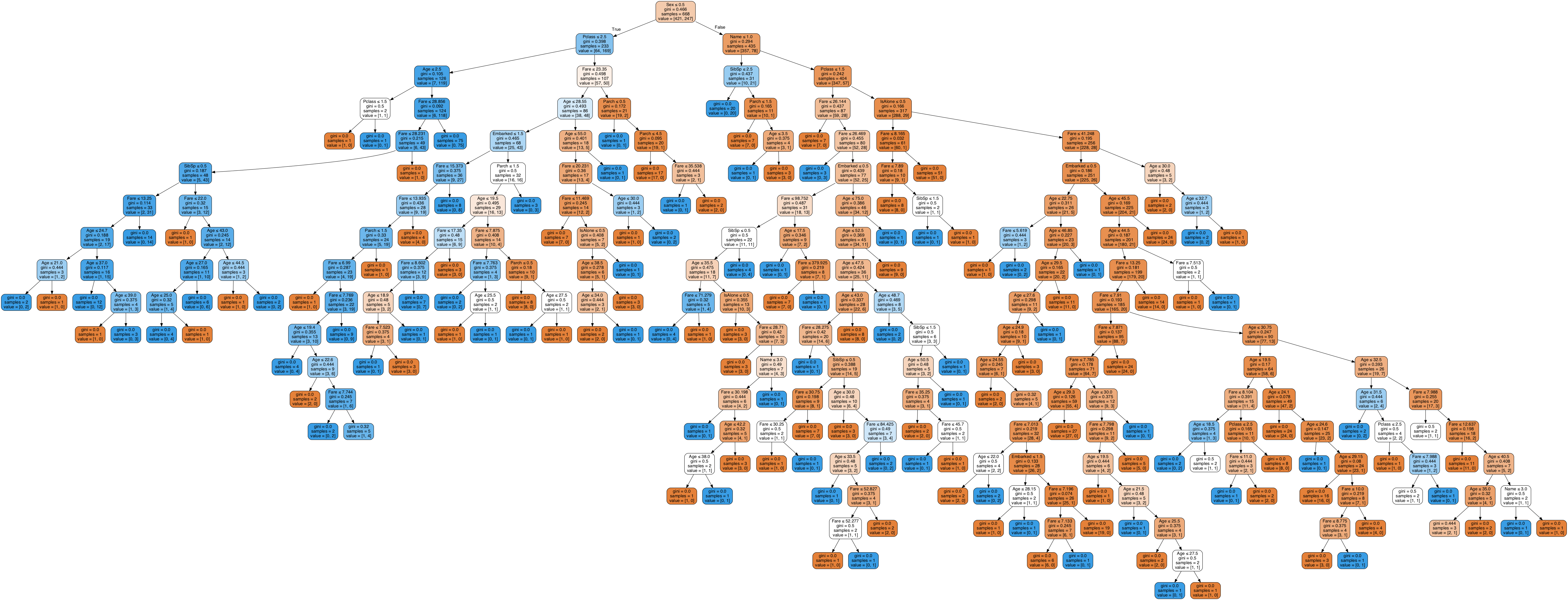
图1 过拟合的决策树模型
观察图1所示的模型结构可以发现,该模型是非常复杂的决策树模型,而且决策树的层数远远超过了10层,从而使用该决策树获得的规则会非常的复杂。通过模型的可视化进一步证明了获得的决策树模型具有严重的过拟合问题,需要对模型进行剪枝,精简模型。
2 决策树剪枝缓解过拟合问题
决策树模型的剪枝操作主要会用到DecisionTreeClassifier()函数中的max_depth和max_leaf_nodes两个参数,其中max_depth指定了决策树的最大深度,max_leaf_nodes指定了模型的叶子节点的最大数目,这里使用参数网格搜索的方式,对该模型中的两个参数进行搜索,并通过该在验证集上的预测精度为准测,获取较合适的模型参数组合,程序如下所示:
## 借助参数网格搜索找到合适的决策树模型参数
depths = np.arange(3,20,1)
leafnodes = np.arange(10,30,2)
tree_depth = []
tree_leafnode = []
val_acc = []
for depth in depths:
for leaf in leafnodes:
dtc2 = DecisionTreeClassifier(max_depth=depth, ## 最大深度
max_leaf_nodes=leaf,##最大叶节点数
min_samples_leaf=5,
min_samples_split=2,
random_state=1)
dtc2 = dtc2.fit(X_train,y_train)
## 计算在测试集上的预测精度
dtc2_pre = dtc2.predict(X_val)
val_acc.append(accuracy_score(y_val,dtc2_pre))
tree_depth.append(depth)
tree_leafnode.append(leaf)
## 将结果组成数据表并输出较好的参数组合
DTCdf = pd.DataFrame(data = {"tree_depth":tree_depth,
"tree_leafnode":tree_leafnode,
"val_acc":val_acc})
## 根据在验证集上的精度进行排序
print(DTCdf.sort_values("val_acc",ascending=False).head(15))
tree_depth tree_leafnode val_acc
0 3 10 0.811659
1 3 12 0.811659
2 3 14 0.811659
3 3 16 0.811659
4 3 18 0.811659
5 3 20 0.811659
6 3 22 0.811659
7 3 24 0.811659
8 3 26 0.811659
9 3 28 0.811659
99 12 28 0.807175
98 12 26 0.807175
89 11 28 0.807175
88 11 26 0.807175
68 9 26 0.807175
从上面程序的输出结果中可以发现,针对泰坦尼克数据在相同的树深度下,树叶节点数量的影响并不是很大,下面使用一组较合适的参数训练一个决策树模型,程序如下所示:
## 使用较合适的参数建立决策树分类器
dtc2 = DecisionTreeClassifier(max_depth=3, ## 最大深度
max_leaf_nodes=10, ## 最大叶节点数量
min_samples_leaf=5,min_samples_split=2,
random_state=1)
dtc2 = dtc2.fit(X_train,y_train)
## 输出其在训练数据和验证数据集上的预测精度
dtc2_lab = dtc2.predict(X_train)
dtc2_pre = dtc2.predict(X_val)
print("训练数据集上的精度:",accuracy_score(y_train,dtc2_lab))
print("验证数据集上的精度:",accuracy_score(y_val,dtc2_pre))
训练数据集上的精度: 0.842814371257485
验证数据集上的精度: 0.8116591928251121
运行上面的程序,从输出结果中可以发现:此时在训练集上的精度为0.84 < 0.99,在验证集上的精度为0.8116 > 0.72,说明决策树的过拟合问题已经得到了一定程度的缓解。并且获得的模型泛化能力更强。
下面的程序可以获得剪枝后的决策树模型结构,运行程序可获得如图2所示的图像。
## 可视化决策树经过剪剪枝后的树结构
dot_data = StringIO()
export_graphviz(dtc2, out_file=dot_data,
feature_names=X_train.columns,
filled=True, rounded=True,special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
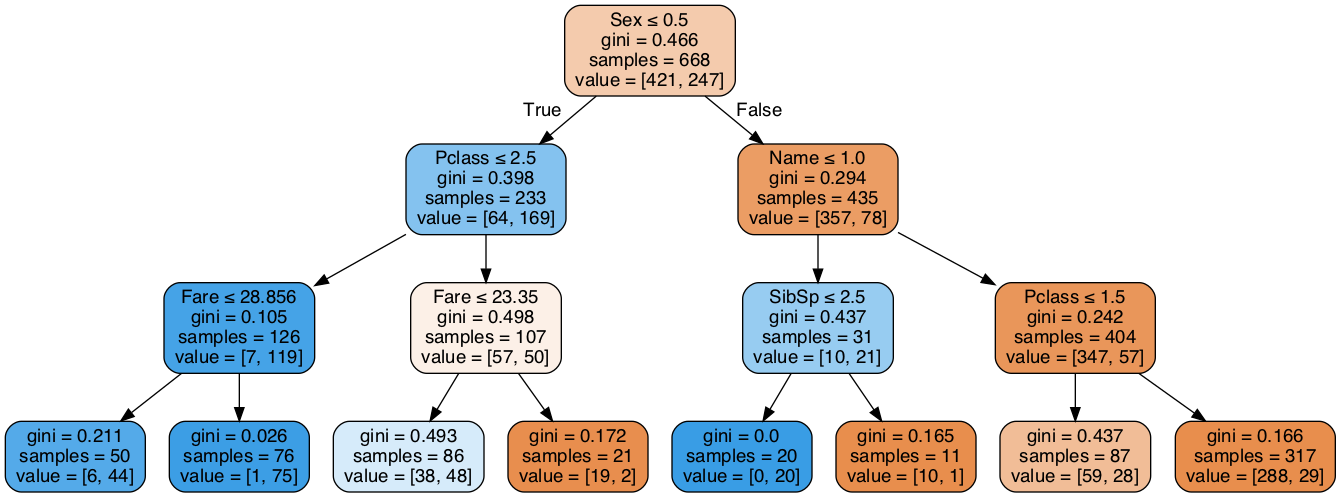
从图2剪枝后决策树模型中可以发现:该模型和未剪枝的模型相比已经大大的简化了,根节点为Sex(性别)特征,即如果Sex_Code
Original: https://blog.csdn.net/daitulin/article/details/120324542
Author: Daitu_Adam
Title: Python——决策树分类模型剪枝
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/664350/
转载文章受原作者版权保护。转载请注明原作者出处!