

无监督学习 — — 聚类方法分类
*
–
+
* 0. 聚类
* 1. K均值聚类
*
– (1). K均值聚类存在问题:
– (2). K均值聚类实现代码:
* 2. 凝聚聚类
*
– (1). 凝聚聚类实现代码:
* 3. DBSCAN 聚类
*
– (1). DBSCAN 聚类实现代码:
* 👉原文链接
0. 聚类
clustering 是将数据集划分成组的任务,这些组叫做簇,其目标是划分数据,使得一个簇内的数据点非常相似,不通簇内的数据点又非常不同。
1. K均值聚类
K均值算法试图找到代表数据特定区域的簇中心,交替执行以下两个步骤:
1.将每个数据点分配给最近的簇中心,
2.每个簇中心设置为所分配的所有数据点的平均值,如果簇的分配不再发生变化,算法结束
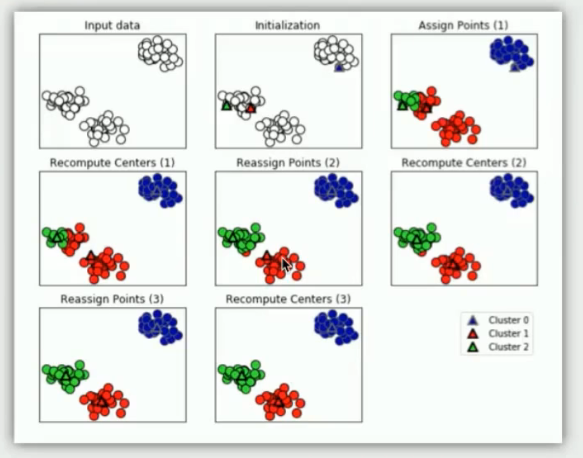

; (1). K均值聚类存在问题:
- 要求指定寻找簇的个数
- k均值只能找到相对简单的形状
- k均值仅考虑到最近簇中心的距离
- 算法的输出依赖于随机种子

(2). K均值聚类实现代码:
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X,y = make_blobs(random_state=1)
plt.scatter(X[:,0],X[:,1])
Kmeans = KMeans(n_clusters=3)
Kmeans.fit(X)
y_pred = Kmeans.predict(X)
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.scatter(Kmeans.cluster_centers_[:,0],Kmeans.cluster_centers_[:,1],marker='^',linewidths=6,cmap=plt.cm.get_cmap('RdYlBu'))
plt.show()

2. 凝聚聚类
凝聚聚类:许多基于相同原则构建的聚类算法︰
1.首先每个点都是自己的簇,然后合并两个最相似的簇,直到满足某种停止准则为止,比如停止准则是簇的个数,因此相似的簇被合并,直到剩下指定个数的簇
2.用迭代的方式合并两个最近的簇,”最佳”的意思是簇的方差之和最小


; (1). 凝聚聚类实现代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.datasets import make_blobs
from sklearn.datasets import make_moons
from sklearn.cluster import KMeans
from sklearn.cluster import AgglomerativeClustering
X,y = make_blobs(random_state=1)
X_m,y_m = make_moons(n_samples=200,noise=0.05,random_state=1)
agg = AgglomerativeClustering(n_clusters=2)
ass = agg.fit_predict(X)
ass_m = agg.fit_predict(X_m)
plt.scatter(X_m[:,0],X_m[:,1],c = ass_m)

3. DBSCAN 聚类
DBSCAN原理:识别特征空间的”拥挤”区域的点
1.增大eps从左到右,更多的点会被包含在一个簇中,
2.增大min_samples,核心点会变得更少,更多的点被标记为噪声
2.用迭代的方式合并两个最近的簇,”最佳”的意思是簇的方差之和最小

; (1). DBSCAN 聚类实现代码:
from sklearn.cluster import DBSCAN
from sklearn.cluster import AgglomerativeClustering
X,y = make_blobs(random_state=1)
X_m,y_m = make_moons(n_samples=200,noise=0.05,random_state=1)
dbscan = DBSCAN(eps=0.2)
clusters_m = dbscan.fit_predict(X_m)
plt.scatter(X_m[:,0],X_m[:,1],c = clusters_m)

👉原文链接
Original: https://blog.csdn.net/weixin_47160526/article/details/123613679
Author: 码猿小菜鸡
Title: 无监督学习 — — 聚类方法分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/663971/
转载文章受原作者版权保护。转载请注明原作者出处!