

文章目录
简介
支持向量机(Support Vector Machine, SVM)对监督学习下二分类问题提供了一个绝妙的解决方案。通过对偶函数和核函数求解,将适用范围从二维线性推广到多维非线性模型,使用相关方法变形,也可用于多分类问题和回归问题。
支持向量机SVM是方法统称,如果应用于分类Classification,也叫支持向量分类SVC;如果应用于回归Regression,也叫支持向量回归SVR。
原理
硬间隔
首先考虑如何评估分类模型的好坏?


在上图中,红点和蓝叉分别表示两类线性可分的数据(取自鸢尾花数据集)。有黑色、橙色和绿色三个线性模型,都可以将数据分为两类。
直观来说,一般我们会认为黑色表示的分类模型会更好。在SVM中,是因为黑色的间隔最大。所谓的「间隔」,直白的说,就是向垂直方向两边平移,直到遇到数据点,所形成的间隔。
间隔示意图如下所示:

而SVM中认为最佳的模型,就是可以取到最大间隔d d d的中间那条直线,也就是到两边各是d 2 \frac{d}{2}2 d ,这样就在最大间隔中若干平行线里,唯一确定了最优的线。
如此一来,由于黑色的间隔最大,所以认为优于橙色和绿色所表示的模型。
; 支持向量
可以看出,在确定最大间隔时,只与少量样本数据有关,平移过程中遇到数据点即停止。我们称这部分样本数据为支持向量,也就是支持向量机名字的由来。这也是支持向量机的一大优势——适用于小样本情况。
以上是二维特征便于可视化的情况。对于二维,我们可以用线来划分;对于三维,我们可以用平面来划分;对于多维,我们称之为超平面,使用超平面来划分。
用如下方程表示超平面:
w T x + b = 0 \bold w^T\bold x +b =0 w T x +b =0
w \bold w w和x \bold x x是向量,分别表示权重和特征。
对于二分类任务中,当y=+1是表示正例,y=-1表示负例。也就是y=+1时,w T x + b ≥ 0 \bold w^T\bold x +b \geq 0 w T x +b ≥0,令:
{ w T x i + b ≥ + 1 , y i = + 1 w T x i + b ≤ − 1 , y i = − 1 \begin{cases}\bold w^T\bold x_i+b \geq +1,& y_i=+1\ \bold w^T\bold x_i+b \leq -1,& y_i=-1\end{cases}{w T x i +b ≥+1 ,w T x i +b ≤−1 ,y i =+1 y i =−1
也就是说,上图中三条平行线的表达式分别是w T x + b = + 1 \bold w^T\bold x+b=+1 w T x +b =+1、w T x + b = 0 \bold w^T\bold x+b=0 w T x +b =0、w T x + b = − 1 \bold w^T\bold x+b=-1 w T x +b =−1。
再由点到平面距离公式r = ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ r=\frac{|\bold w^T \bold x+b|}{||\bold w||}r =∣∣w ∣∣∣w T x +b ∣,得到间隔(两个异类支持向量到超平面距离)定义:
γ = 2 ∣ ∣ w ∣ ∣ \gamma=\frac{2}{||\bold w||}γ=∣∣w ∣∣2
为了求最大间隔,需要分式中分母最小,即最小化∣ ∣ w ∣ ∣ − 1 \bold ||w||^{-1}∣∣w ∣∣−1,等价于最小化1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||\bold w||^2 2 1 ∣∣w ∣∣2。
如此一来,对于线性模型,我们求解如下表达式即可求得最大间隔,也称支持向量机的基本型:
m i n w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i + b ) ≥ 1 \mathop{min}\limits_{\bold w,b}\quad\frac{1}{2}||\bold w||^2 \ s.t.\quad y_i(\bold w^T\bold x_i+b)\geq1 w ,b min 2 1 ∣∣w ∣∣2 s .t .y i (w T x i +b )≥1
属于二次规划问题,即目标函数二次项,限制条件一次项。使用拉格朗日乘子法可求得其对偶问题,使用对偶问题优化目标函数和限制条件,方便进行求解。
对偶问题
对偶问题(dual problem)简单来说就是同一问题的不同角度解法。比如时间=路程÷速度,那么求最短的时间等价于求最大的速度。
对偶问题定义L ( w , α , β ) = f ( w ) + α T g ( w ) + β T ( w ) L(w,\alpha,\beta)=f(w)+\alpha^Tg(w)+\beta^T(w)L (w ,α,β)=f (w )+αT g (w )+βT (w )
若w ∗ w^w ∗是原问题的解,α ∗ \alpha^α∗和β ∗ \beta^β∗是对偶问题的解,则有f ( w ∗ ) ≥ θ ( α ∗ , β ∗ ) f(w^)\geq\theta(\alpha^,\beta^)f (w ∗)≥θ(α∗,β∗)
对约束添加拉格朗日乘子α i ≥ 0 \alpha_i\geq0 αi ≥0,α i = ( α 1 , α 2 , … , α m ) \alpha_i=(\alpha_1,\alpha_2,\dots,\alpha_m)αi =(α1 ,α2 ,…,αm )
定义凸二次规划拉格朗日函数:L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) ) L(\bold w,b,\alpha)=\frac{1}{2}||\bold w||^2+\sum_{i=1}^m\alpha_i(1-y_i(\bold w^T\bold x_i+b))L (w ,b ,α)=2 1 ∣∣w ∣∣2 +i =1 ∑m αi (1 −y i (w T x i +b ))
定义原问题与对偶问题的间距G G G,G = f ( w ∗ ) − θ ( α ∗ , β ∗ ) ≥ 0 G=f(w^)-\theta(\alpha^,\beta^*)\geq0 G =f (w ∗)−θ(α∗,β∗)≥0
强对偶定理:若f ( w ) f(w)f (w )为凸函数,且g ( w ) = A w + b g(w)=Aw+b g (w )=A w +b,h ( w ) = C w + d h(w)=Cw+d h (w )=C w +d,则此优化问题的原问题与对偶问题的间距为0。
通过强对偶性,转换为:
m a x α m i n w , b L ( w , b , α ) \mathop{max}\limits_{\alpha} \mathop{min}\limits_{\bold w,b}L(\bold w,b,\alpha)αma x w ,b min L (w ,b ,α)
对w \bold w w和b b b求偏导,即令∂ L ∂ w = 0 \frac{\partial L}{\partial w}=0 ∂w ∂L =0和∂ L ∂ b = 0 \frac{\partial L}{\partial b}=0 ∂b ∂L =0,有∑ i = 1 m α i y i x i = w ∑ i = 1 m α i y i = 0 \sum_{i=1}^m\alpha_iy_i\bold x_i=\bold w\ \sum_{i=1}^m\alpha_iy_i=0 i =1 ∑m αi y i x i =w i =1 ∑m αi y i =0
代回L ( w , b , α ) L(\bold w,b,\alpha)L (w ,b ,α)中,一通消消乐后得到L ( w , b , α ) = ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j L(\bold w,b,\alpha)=\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_j\bold x^T_i\bold x_j L (w ,b ,α)=i =1 ∑m αi −2 1 i =1 ∑m j =1 ∑m αi αj y i y j x i T x j
也就是将求最小的w \bold w w和b b b转换为求最大的α \alpha α,即对偶问题:KaTeX parse error: No such environment: align at position 148: ….t.\quad \begin{̲a̲l̲i̲g̲n̲̲}̲\begin{split} …
同时满足约束和KKT条件:
s . t . { α i ≥ 0 y i f ( x i ) − 1 ≥ 0 α i ( y i f ( x i ) − 1 ) = 0 s.t.\quad \begin{cases}\bold \alpha_i\geq0\ y_if(\bold x_i)-1\geq0\\alpha_i(y_if(\bold x_i)-1)=0\end{cases}s .t .⎩⎪⎨⎪⎧αi ≥0 y i f (x i )−1 ≥0 αi (y i f (x i )−1 )=0
KKT条件:∀ i = 1 ∼ k , α i ∗ = 0 或 g i ∗ ( w ∗ ) = 0 \forall i=1\sim k,\alpha_i^=0或g_i^(w^*)=0 ∀i =1 ∼k ,αi ∗=0 或g i ∗(w ∗)=0
也就是说:
若α i = 0 \alpha_i=0 αi =0,则全部乘起来为0,f ( x ) f(x)f (x )该项累加0,即该样本无影响。
若α i > 0 \alpha_i>0 αi >0,由KKT条件则y i f ( x i ) = 1 y_if(\bold x_i)=1 y i f (x i )=1,该样本位于最大间隔边界上,是一个支持向量。
再次说明SVM仅与支持向量有关,与大部分训练样本无关,适用于小样本数据集。
软间隔
前面假设的都是硬间隔的情况,也就是所有样本严格满足约束,不存在任何错误样本。而软间隔则是允许一定误差,不是非要全部样本都满足约束,允许一些样本”出错”。图摘自网络。

引用松弛变量ξ i ≥ 0 \xi_i\geq0 ξi ≥0,添加一个正则化项,将SVM的基本型改写为:
m i n w , b , ξ i 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i s . t . y i ( w T x i + b ) ≥ 1 − ξ i \mathop{min}\limits_{\bold w,b,\xi_i}\quad\frac{1}{2}||\bold w||^2+C\sum_{i=1}^m\xi_i\ s.t.\quad y_i(\bold w^T\bold x_i+b)\geq1-\xi_i w ,b ,ξi min 2 1 ∣∣w ∣∣2 +C i =1 ∑m ξi s .t .y i (w T x i +b )≥1 −ξi
C C C是常数,也就是说原来需要大于等于1才能判为正例,现在只需大于等于( 1 − ξ i ) (1-\xi_i)(1 −ξi )即可。但ξ i \xi_i ξi 也不能太大,否则限制条件太容易成立,根本起不到限制作用,导致分类效果差。
同样的,将基本型转为对偶问题,添加拉格朗日乘子,并将偏导为0代回原式,得:
m a x α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j s . t . { 0 ≤ α i ≤ C ∑ i = 1 m α i y i = 0 \mathop{max}\limits_\alpha\quad\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_j\bold x_i^T\bold x_j\s.t.\quad \begin{cases}0\leq\alpha_i\leq C\ \sum_{i=1}^m \alpha_i y_i=0\end{cases}αma x i =1 ∑m αi −2 1 i =1 ∑m j =1 ∑m αi αj y i y j x i T x j s .t .{0 ≤αi ≤C ∑i =1 m αi y i =0
其实,与硬间隔的区别就只是限制条件不同了,硬间隔0 ≤ α i 0\leq\alpha_i 0 ≤αi 即可,软间隔0 ≤ α i ≤ C 0\leq\alpha_i\leq C 0 ≤αi ≤C。
兼容软间隔的情况,使模型具有一定容错能力。
; 核函数
我们再考虑下非线性模型,因为线性模型可以看成非线性模型的一种情况,得到非线性模型的表达式后,可以统一求解。
线性可分,是可以用一条直线进行区分;线性不可分,就是不能用一条直线区分,需要用曲线区分。而非线性模型,就是对于线性不可分的情况,如异或问题(图摘自网络):

对于这样的问题,我们可以将原本特征空间映射到一个更高维度的空间,使得在这个高纬度空间中存在超平面将样本分离,即是线性可分的。也就是升维,这个维度可以是无穷维的,一定可以使其线性可分的,只是我们难以想象。
f ( x ) = w T ϕ ( x ) + b f(\bold x)=\bold w^T \phi(\bold x)+b f (x )=w T ϕ(x )+b
升维后:
m a x α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j ϕ ( x i ) T ϕ ( x j ) \mathop{max}\limits_\alpha\quad\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_j\phi(\bold x_i)^T\phi(\bold x_j)αma x i =1 ∑m αi −2 1 i =1 ∑m j =1 ∑m αi αj y i y j ϕ(x i )T ϕ(x j )
但是新的问题是,我们不知道这个无限维映射ϕ ( x ) \phi(x)ϕ(x )的显示表达,即无法直接计算内积ϕ ( x i ) T ϕ ( x j ) \phi(\bold x_i)^T\phi(\bold x_j)ϕ(x i )T ϕ(x j ),此时需要用到核函数(Kernel Function):
K ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) \Kappa(\bold x_i,\bold x_j)=\phi(\bold x_i)^T\phi(x_j)K (x i ,x j )=ϕ(x i )T ϕ(x j )
通过核函数在原始样本空间计算的结果,等于升维后特征空间的内积,代回原表达式,得:
m a x α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j K ( x i , x j ) s . t . { 0 ≤ α i ≤ C ∑ i = 1 m α i y i = 0 \mathop{max}\limits_\alpha\quad\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_j\Kappa(\bold x_i,\bold x_j)\s.t.\quad \begin{cases}0\leq\alpha_i\leq C\ \sum_{i=1}^m \alpha_i y_i=0\end{cases}αma x i =1 ∑m αi −2 1 i =1 ∑m j =1 ∑m αi αj y i y j K (x i ,x j )s .t .{0 ≤αi ≤C ∑i =1 m αi y i =0
即
{ f ( x ) = w T ϕ ( x ) + b = ∑ i = 1 m α i y i ϕ ( x i ) + b = ∑ i = 1 m α i y i K ( x i , x j ) + b \begin{cases} f(x)&=\bold w^T\phi(\bold x)+b\ &= \sum_{i=1}^m\alpha_iy_i\phi(\bold x_i)+b\ &=\sum_{i=1}^m\alpha_iy_i\Kappa(\bold x_i,\bold x_j)+b \end{cases}⎩⎪⎨⎪⎧f (x )=w T ϕ(x )+b =∑i =1 m αi y i ϕ(x i )+b =∑i =1 m αi y i K (x i ,x j )+b
常用核函数:
名称表达式线性核
κ ( x i , x j ) = e x p ( x i T x j ) \kappa(\bold x_i,\bold x_j)=exp(\bold x_i^T\bold x_j)κ(x i ,x j )=e x p (x i T x j )
多项式核
κ ( x i , x j ) = e x p ( x i T x j ) d \kappa(\bold x_i,\bold x_j)=exp(\bold x_i^T\bold x_j)^d κ(x i ,x j )=e x p (x i T x j )d
高斯核
κ ( x i , x j ) = e x p ( ∣ ∣ x i − x j ∣ ∣ 2 2 σ 2 ) \kappa(\bold x_i,\bold x_j)=exp(\frac{||\bold x_i-\bold x_j||^2}{2\sigma^2})κ(x i ,x j )=e x p (2 σ2 ∣∣x i −x j ∣∣2 )
多项式核中d d d表示多项式次数,可以调参。
高斯核也需要调参σ > 0 \sigma>0 σ>0,表示高斯核的带宽。
核函数就是为了兼容非线性模型,升维后并求解。
SMO算法
求解:
m a x α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j K ( x i , x j ) s . t . { 0 ≤ α i ≤ C ∑ i = 1 m α i y i = 0 \mathop{max}\limits_\alpha\quad\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_jK(\bold x_i,\bold x_j)\s.t.\quad \begin{cases} 0\leq\alpha_i\leq C \ \sum_{i=1}^m \alpha_i y_i=0 \end{cases}αma x i =1 ∑m αi −2 1 i =1 ∑m j =1 ∑m αi αj y i y j K (x i ,x j )s .t .{0 ≤αi ≤C ∑i =1 m αi y i =0
用SMO(Sequential Minimal Optimization)算法求解这个二次规划问题。
思路是先固定α i \alpha_i αi 之外的所有参数,然后求α i \alpha_i αi 上的极值。由于存在约束∑ i = 1 m α i y i = 0 \sum_{i=1}^m\alpha_iy_i=0 ∑i =1 m αi y i =0,固定其他变量之后,便可求出α i \alpha_i αi 。于是每次选择两个变量α i \alpha_i αi 和α j \alpha_j αj 并固定其他参数,直至收敛。
仅考虑α i \alpha_i αi 和α j \alpha_j αj (α i ≥ 0 , α j ≥ 0 \alpha_i\geq0,\alpha_j\geq0 αi ≥0 ,αj ≥0):
α i y i + α j y j = c \alpha_iy_i+\alpha_jy_j=c αi y i +αj y j =c
c c c是使∑ i = 1 m \sum_{i=1}^m ∑i =1 m 成立的常数,c = − ∑ k ≠ i , j α k y k c=-\sum_{k\neq i,j}\alpha_ky_k c =−∑k =i ,j αk y k
如此便可计算α i \alpha_i αi 和α j \alpha_j αj 。
再代入任何一个支持向量y s f ( x s ) = 1 y_sf(\bold x_s)=1 y s f (x s )=1,便可求得b b b:
y s ( ∑ i ∈ S α i y i x i T x s + b ) = 1 y_s(\sum_{i\in S}\alpha_iy_i\bold x_i^T\bold x_s+b)=1 y s (i ∈S ∑αi y i x i T x s +b )=1
也可以带入全部的支持向量,然后取平均值。
(插播反爬信息 )博主CSDN地址:https://wzlodq.blog.csdn.net/
小结
- 训练流程
输入样本{x i , y i \bold x_i, y_i x i ,y i },i:1~m
最大化间隔:
m a x α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j K ( x i , x j ) s . t . { 0 ≤ α i ≤ C ∑ i = 1 m α i y i = 0 \mathop{max}\limits_\alpha\quad\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_jK(\bold x_i,\bold x_j)\s.t.\quad \begin{cases}0\leq\alpha_i\leq C\ \sum_{i=1}^m \alpha_i y_i=0\end{cases}αma x i =1 ∑m αi −2 1 i =1 ∑m j =1 ∑m αi αj y i y j K (x i ,x j )s .t .{0 ≤αi ≤C ∑i =1 m αi y i =0
在[0,C]中,找一个α i \alpha_i αi ,算b:
b = 1 − y i ∑ j = 1 n α j y j K ( x i , x j ) y i b=\frac{1-y_i\sum_{j=1}^n\alpha_jy_jK(\bold x_i,\bold x_j)}{y_i}b =y i 1 −y i ∑j =1 n αj y j K (x i ,x j ) - 测试流程
输入测试样本x \bold x x
若∑ i = 1 n α i y i K ( x i , x ) + b ≥ 0 \sum_{i=1}^n\alpha_iy_iK(\bold x_i,\bold x)+b\geq0 ∑i =1 n αi y i K (x i ,x )+b ≥0,则y=+1
若∑ i = 1 n α i y i K ( x i , x ) + b < 0 \sum_{i=1}^n\alpha_iy_iK(\bold x_i,\bold x)+b,则y=-1
多分类问题
如上SVM可以解决二分类问题,但是并不能直接解决多分类问题,不过也是可以在逻辑上进行求解,但是开销较大,需要构建多个SVM。
如三分类问题,有A、B、C三类,此时可以构建3个SVM。
比如:
SVM1:A vs B
SVM2:A vs C
SVM3:B vs C
如果SVM1=+1且SVM2=+1,SVM3无所谓,则分类为A。
如果SVM1=-1且SVM2=-1且SVM3=+1,则分类为B。
如果SVM1=-1且SVM2=-1且SVM3=-1,则分类为B。
再比如合并数据集:
SVM1:A vs BC
SVM2:B vs AC
SVM3:C vs AB
如果SVM1=+1或(SVM2=-1且SVM3=-1),则分类为A。
如果SVM2=+1或(SVM1=-1且SVM3=-1),则分类为B。
如果SVM3=+1或(SVM1=-1且SVM2=-1),则分类为C。
但如果出现SVM1=SVM2=SVM3=+1的情况,虽然逻辑上都是+1,没有满足条件的解,但其实我们是算出了具体的值w T x + b \bold w^T\bold x+b w T x +b,其大于等于+1,则置y=+1。此时我们可以用这个具体的值来判断,而不是用y,比较SVM123算出来的具体值w T x + b \bold w^T\bold x+b w T x +b,判为值最大的SVM对应类。
N分类以此类推,需要构建N个支持向量机。
回归问题
原理与求解步骤与分类时基本一致,在分类中添加了一个松弛变量,允许一定误差,满足软间隔。同样的在回归中,也添加了一个偏差ϵ \epsilon ϵ,构建了一个宽度为2 ϵ 2\epsilon 2 ϵ的误差间隔带,只要落入此间隔带内,则认为是被预测正确的。也就是两个松弛变量ξ \xi ξ和ξ ^ \hat{\xi}ξ^,,分别表示两侧的松弛程度。图摘自网络。

即:
m i n w , b , ξ , ξ ^ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ( ξ i + ξ i ^ ) s . t . { f ( x i ) − y i ≤ ϵ + ξ i y i − f ( x i ) ≤ ϵ + ξ i ^ ξ i ≥ 0 , ξ i ^ ≥ 0 \mathop{min}\limits_{\bold w,b,\xi,\hat{\xi}}\quad \frac{1}{2}||\bold w||^2+C\sum_{i=1}^m(\xi_i+\hat{\xi_i})\\s.t.\quad \begin{cases}f(\bold x_i)-y_i\leq\epsilon+\xi_i\ y_i-f(\bold x_i)\leq\epsilon+\hat{\xi_i}\\xi_i\geq0,\hat{\xi_i}\geq0\end{cases}w ,b ,ξ,ξ^min 2 1 ∣∣w ∣∣2 +C i =1 ∑m (ξi +ξi ^)s .t .⎩⎪⎨⎪⎧f (x i )−y i ≤ϵ+ξi y i −f (x i )≤ϵ+ξi ^ξi ≥0 ,ξi ^≥0
同样转换对偶问题,映射高维度并用核函数求解,得到回归方程:
f ( x ) = ∑ i = 1 m ( α i ^ − α i ) K ( x , x i ) + b f(\bold x)=\sum^m_{i=1}(\hat{\alpha_i}-\alpha_i)\Kappa(\bold x,\bold x_i)+b f (x )=i =1 ∑m (αi ^−αi )K (x ,x i )+b
; 应用示例
sklearn对支持向量机封装了很多模型,相关函数调用可以查询文档。
例1. 线性核
import numpy as np
from matplotlib import pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
from matplotlib.colors import ListedColormap
from sklearn.metrics import classification_report
def plot_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', 'black', '#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
w = model.coef_[0]
b = model.intercept_[0]
index_x = np.linspace(axis[0], axis[1], 100)
y_up = (1 - w[0] * index_x - b) / w[1]
x_index_up = index_x[(y_up >= axis[2]) & (y_up axis[3])]
y_up = y_up[(y_up >= axis[2]) & (y_up axis[3])]
y_down = (-1 - w[0] * index_x - b) / w[1]
x_index_down = index_x[(y_down >= axis[2]) & (y_down axis[3])]
y_down = y_down[(y_down >= axis[2]) & (y_down axis[3])]
y_origin = (- w[0] * index_x - b) / w[1]
x_index_origin = index_x[(y_origin >= axis[2]) & (y_origin axis[3])]
y_origin = y_origin[(y_origin >= axis[2]) & (y_origin axis[3])]
plt.plot(x_index_origin, y_origin, color="black")
iris = datasets.load_iris()
x = iris.data[:100, [2, 3]]
y = iris.target[0:100]
x_train, x_test, y_train, y_test = train_test_split(x, y)
linearsvc = LinearSVC(C=1e9)
linearsvc.fit(x_train, y_train)
y_pred = linearsvc.predict(x_test)
print('w:', linearsvc.coef_)
print('b:', linearsvc.intercept_)
print(classification_report(y_test, y_pred))
plot_boundary(linearsvc, axis=[0.9, 5.2, 0, 1.9])
for i in range(50):
plt.scatter(x[i][0], x[i][1], color="red", marker='o')
for i in range(50, 100):
plt.scatter(x[i][0], x[i][1], color="blue", marker='x')
plt.show()


例2. 多项式核
import numpy as np
from matplotlib import pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from matplotlib.colors import ListedColormap
from sklearn.metrics import classification_report
def plot_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', 'black', '#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
moons = datasets.make_moons(noise=0.1, random_state=20221017)
x = moons[0]
y = moons[1]
x_train, x_test, y_train, y_test = train_test_split(x, y)
poly_svc = SVC(kernel='poly', degree=5)
poly_svc.fit(x, y)
y_pred = poly_svc.predict(x_test)
print(classification_report(y_test, y_pred))
plot_boundary(poly_svc, axis=[-1.2, 2.2, -0.75, 1.25])
plt.scatter(x[y == 0, 0], x[y == 0, 1], color='red')
plt.scatter(x[y == 1, 0], x[y == 1, 1], color='blue')
plt.show()


例3. 高斯核
import numpy as np
from matplotlib import pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from matplotlib.colors import ListedColormap
from sklearn.metrics import classification_report
def plot_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', 'black', '#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
moons = datasets.make_moons(noise=0.1, random_state=20221017)
x = moons[0]
y = moons[1]
x_train, x_test, y_train, y_test = train_test_split(x, y)
poly_svc = SVC(kernel='rbf')
poly_svc.fit(x, y)
y_pred = poly_svc.predict(x_test)
print(classification_report(y_test, y_pred))
plot_boundary(poly_svc, axis=[-1.2, 2.2, -0.75, 1.25])
plt.scatter(x[y == 0, 0], x[y == 0, 1], color='red')
plt.scatter(x[y == 1, 0], x[y == 1, 1], color='blue')
plt.show()

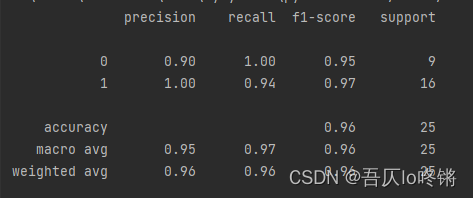
例4. 回归
import numpy as np
from matplotlib import pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC, SVR
from matplotlib.colors import ListedColormap
from sklearn.metrics import classification_report
def plot_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', 'black', '#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
X = np.linspace(0, 5, 100)
y = X ** 2 + 5 + np.random.randn(100)
x = X.reshape(-1, 1)
linear_svr = SVR(kernel="linear")
poly_svr = SVR(kernel="poly", degree=2)
rbf_svr = SVR(kernel="rbf")
linear_svr.fit(x, y)
poly_svr.fit(x, y)
rbf_svr.fit(x, y)
linear_pred = linear_svr.predict(x)
poly_pred = poly_svr.predict(x)
rbf_pred = rbf_svr.predict(x)
plt.plot(x, linear_pred, label='linear', color='red')
plt.plot(x, poly_pred, label='poly', color='orange')
plt.plot(x, rbf_pred, label='rbf', color='green')
plt.scatter(X, y, color='lightblue')
plt.legend()
plt.show()

参考文献:《机器学习》 周志华
原创不易,请勿转载(本不富裕的访问量雪上加霜 )
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤Original: https://blog.csdn.net/qq_45034708/article/details/127324747
Author: 吾仄lo咚锵
Title: 分类和回归-支持向量机SVM算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/663528/
转载文章受原作者版权保护。转载请注明原作者出处!