

目录
Python语言自然不用多说了,专门做数据分析和数据挖掘、数据解刨的语言,模块很多使用方便。
Numpy、Pandas模块包简介
Numpy
NumPy 是 Python 中科学计算的基础包。它是一个 Python 库,提供多维数组对象、各种派生对象
(例如掩码数组和矩阵)以及用于对数组进行快速操作的各种例程,包括数学、逻辑、形状操作、
排序、选择、I/O 、离散傅里叶变换、基本线性代数、基本统计运算、随机模拟等等。
Pandas
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
numpy和pandas的两个官网链接,API和文档信息都在官网内查询。注意版本的不同带来的影响。

数据操作分析实例操作:
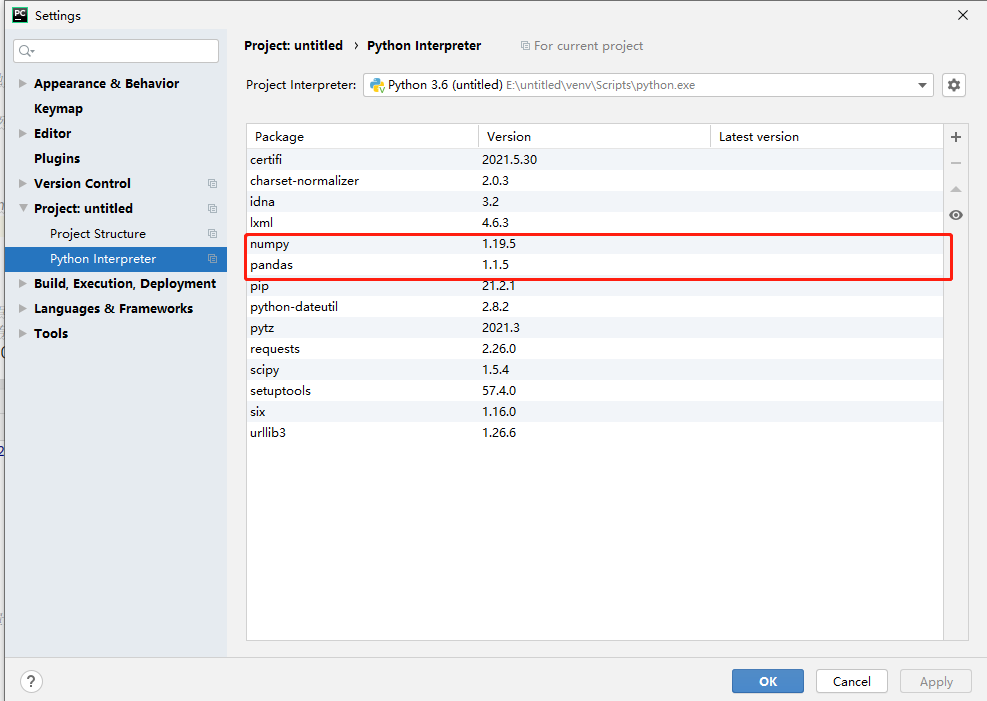
环境准备
准备numpy、pandas、python3.6版本
准备清洗的数据:

数据文档放置在Data文件夹:


写代码实操部分
导入依赖包进行打包处理
#导入依赖包
#-*-coding:utf-8-*-
from __future__ import division #"/"执行的才是精确算法
from scipy import stats #Scipy的stats模块包含了多种概率分布的随机变量,随机变量分为连续的和离散的两种
import pandas as pd #导入pandas包,命名为pd
import numpy as np #导入numpy包,命名为np
执行结果呈现:(下面的文章,代码在上部分,执行结果在下部分)
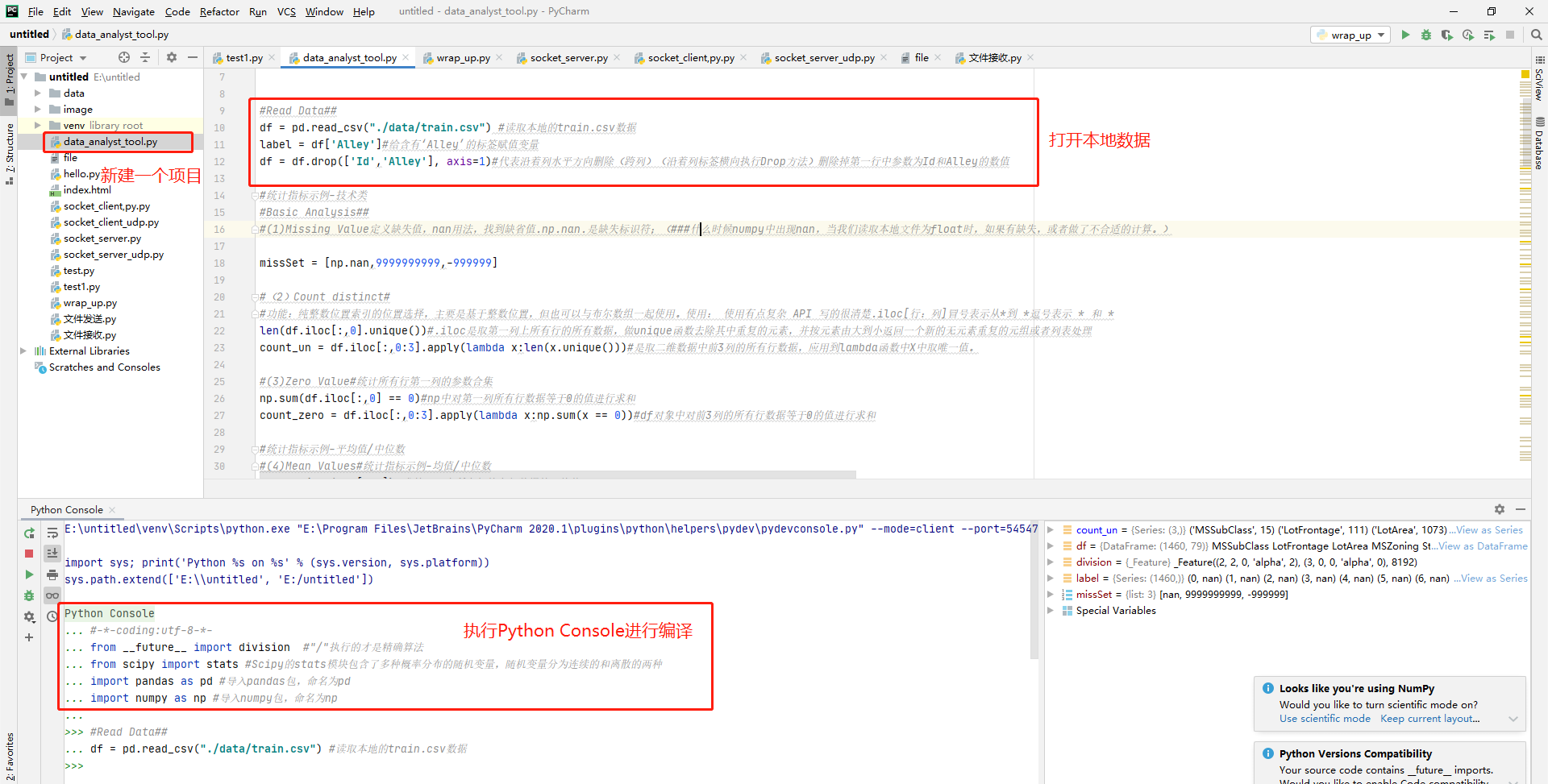
数据预处理,处理缺失值和清除不要的列数据。
#Read Data##读取数据
df = pd.read_csv("./data/train.csv") #读取本地的train.csv数据
label = df['Alley']#给含有'Alley'的标签赋值变量
df = df.drop(['Id','Alley'], axis=1)#代表沿着列水平方向删除(跨列)(沿着列标签横向执行Drop方法)删除掉第一行中参数为Id和Alley的数值
#统计指标示例-技术类
#Basic Analysis##
#(1)Missing Value定义缺失值,nan用法,找到缺省值.np.nan.是缺失标识符;(什么时候numpy中出现nan,当我们读取本地文件为float时,如果有缺失,或者做了不合适的计算。)
missSet = [np.nan,9999999999,-999999]
执行结果:

去重统计数值代码:
#(2)Count distinct#
#功能:纯整数位置索引的位置选择,主要是基于整数位置,但也可以与布尔数组一起使用。使用: 使用有点复杂 API 写的很清楚.iloc[行:列]冒号表示从*到 *逗号表示 * 和 *
len(df.iloc[:,0].unique())#.iloc是取第一列上所有行的所有数据,做unique函数去除其中重复的元素,并按元素由大到小返回一个新的无元素重复的元组或者列表处理
count_un = df.iloc[:,0:3].apply(lambda x:len(x.unique()))#是取二维数据中前3列的所有行数据,应用到lambda函数中X中取唯一值。

求和代码:
#(3)Zero Value#统计所有行第一列的参数合集
np.sum(df.iloc[:,0] == 0)#np中对第一列所有行数据等于0的值进行求和
count_zero = df.iloc[:,0:3].apply(lambda x:np.sum(x == 0))#df对象中对前3列的所有行数据等于0的值进行求和
执行结果:
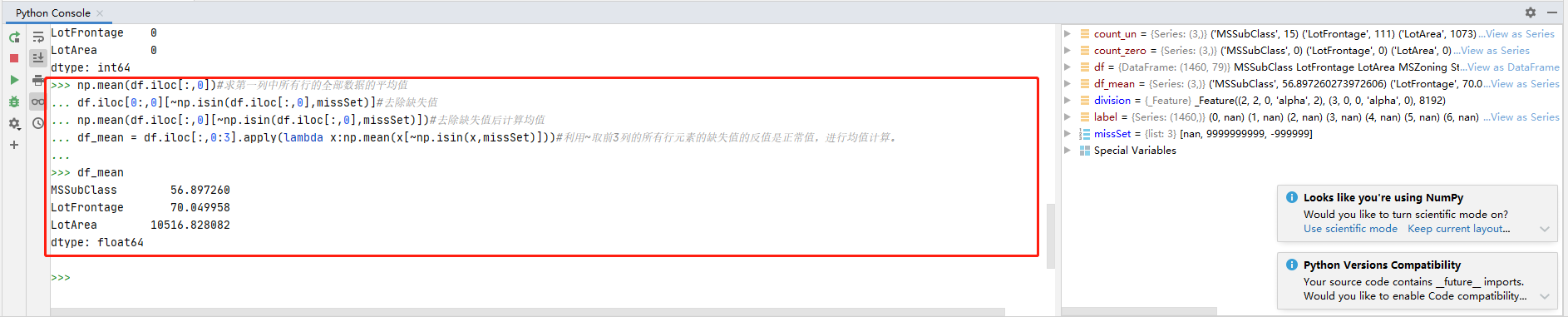
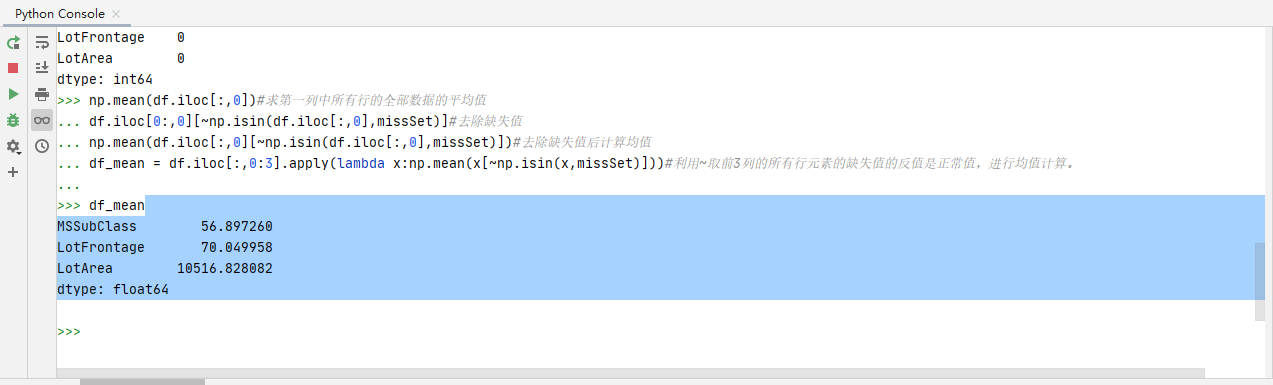
统计平均数的代码:
#统计指标示例-平均值/中位数
#(4)Mean Values#统计指标示例-均值/中位数
np.mean(df.iloc[:,0])#求第一列中所有行的全部数据的平均值
df.iloc[0:,0][~np.isin(df.iloc[:,0],missSet)]#去除缺失值
np.mean(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)])#去除缺失值后计算均值
df_mean = df.iloc[:,0:3].apply(lambda x:np.mean(x[~np.isin(x,missSet)]))#利用~取前3列的所有行元素的缺失值的反值是正常值,进行均值计算。
执行代码结果:
求矩阵的中位数:
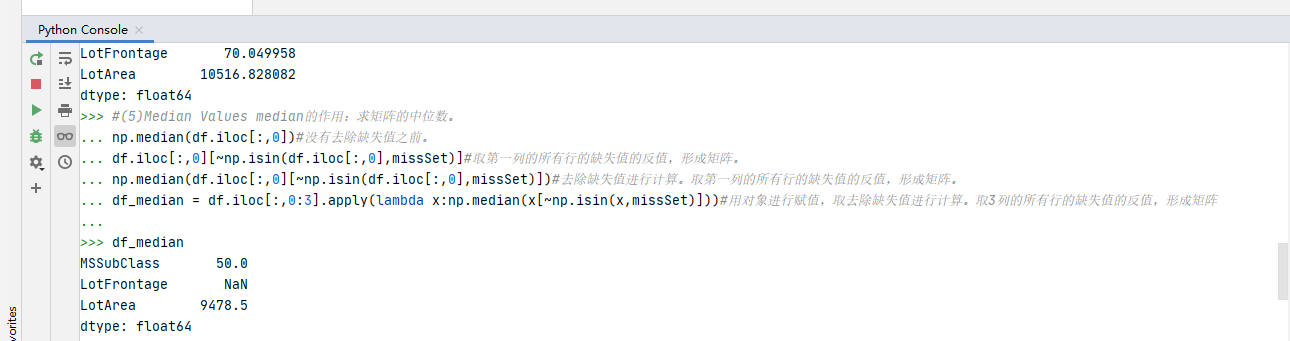
#(5)Median Values median的作用:求矩阵的中位数。
np.median(df.iloc[:,0])#没有去除缺失值之前。
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)]#取第一列的所有行的缺失值的反值,形成矩阵。
np.median(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)])#去除缺失值进行计算。取第一列的所有行的缺失值的反值,形成矩阵。
df_median = df.iloc[:,0:3].apply(lambda x:np.median(x[~np.isin(x,missSet)]))#用对象进行赋值,取去除缺失值进行计算。取3列的所有行的缺失值的反值,形成矩阵
执行代码结果:
求众数的代码:
#统计指标示例-众数
#(6)Mode Values
#stats.mode函数寻找数组或者矩阵每行/每列中最常出现成员以及出现的次数。
df_mode = df.iloc[:,0:3].apply(lambda x:stats.mode(x[~np.isin(x,missSet)])[0][0])#用对象赋值,取去除缺失值的前三列特征值的所有行数据进行计算,结果是数组矩阵,用【0】取第一行统计的数值【0】取首列名称。
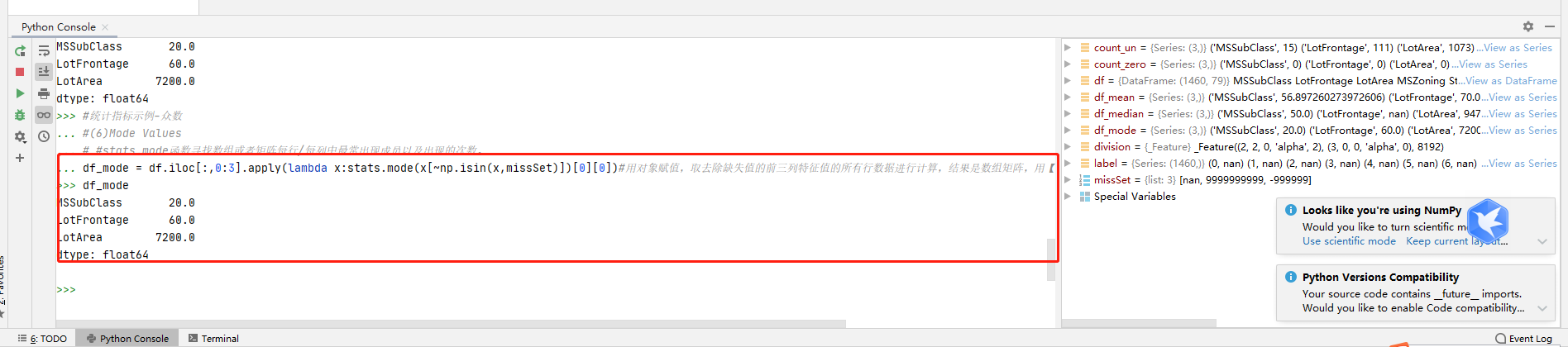
求众数的值计算:
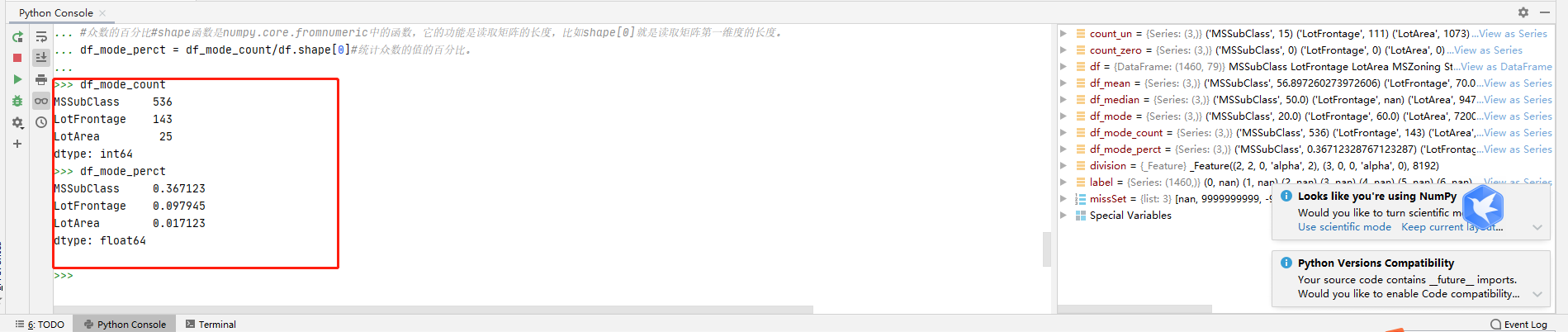
#(7)Mode Percentage#求众数统计值
df_mode_count = df.iloc[:,0:3].apply(lambda x: stats.mode(x[~np.isin(x,missSet)])[1][0])#用对象赋值,取去除缺失值的前三列特征值的所有行数据进行计算,结果是数组矩阵,用【1】取第二行统计的数值【0】取首列名称。
#众数的百分比#shape函数是numpy.core.fromnumeric中的函数,它的功能是读取矩阵的长度,比如shape[0]就是读取矩阵第一维度的长度。
df_mode_perct = df_mode_count/df.shape[0]#统计众数的值的百分比。
代码执行结果:
求最大最小值的代码:
#统计指标示例-最大值、最小值
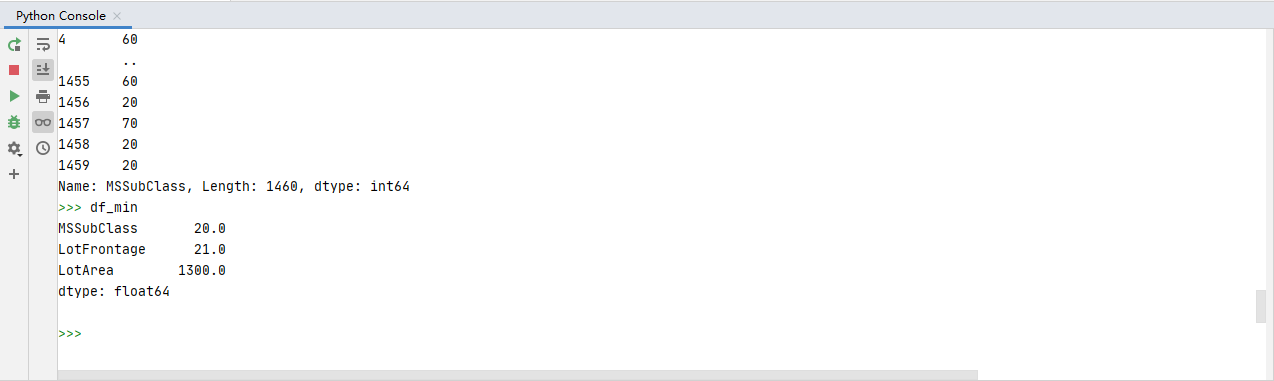
#(8)Min Values#
np.min(df.iloc[:,0])#
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)]#
np.min(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)])#去除缺失值后取正常值进行最小值计算
df_min = df.iloc[:,0:3].apply(lambda x:np.min(x[~np.isin(x,missSet)]))#用对象赋值取去除缺失值后取正常值进行最小值计算
执行结果:

求最大值的代码:
#(9)Max Values#
np.max(df.iloc[:,0])
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)]#去除缺失值
np.max(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)])#用取去除缺失值后取正常值进行最大值计算
df_max = df.iloc[:,0:3].apply(lambda x:np.max(x[~np.isin(x,missSet)]))#用对象赋值取去除缺失值后取正常值进行最大值计算
执行结果:


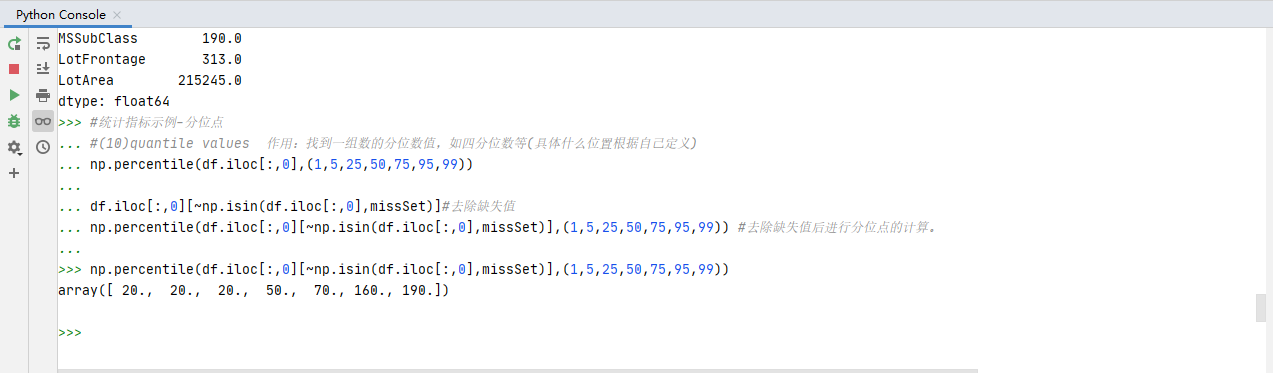
分为点的代码:
#统计指标示例-分位点
#(10)quantile values 作用:找到一组数的分位数值,如四分位数等(具体什么位置根据自己定义)
np.percentile(df.iloc[:,0],(1,5,25,50,75,95,99))
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)]#去除缺失值
np.percentile(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)],(1,5,25,50,75,95,99)) #去除缺失值后进行分位点的计算。
执行结果:
#特殊值的计算。enumerate参数为可遍历的变量,如字符串,列表等, 返回值为enumerate类
#DataFrame是一种表格型数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame既有行索引(index)也有列索引(column)。行索引和列索引是标签。
#DataFrame的创建有多种方式,不过最重要的还是根据dict进行创建,以及读取csv或者txt文件来创建。
#https://blog.csdn.net/leilei7407/article/details/104424642?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164203439616780264012048%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164203439616780264012048&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-2-104424642.first_rank_v2_pc_rank_v29&utm_term=DataFrame&spm=1018.2226.3001.4187
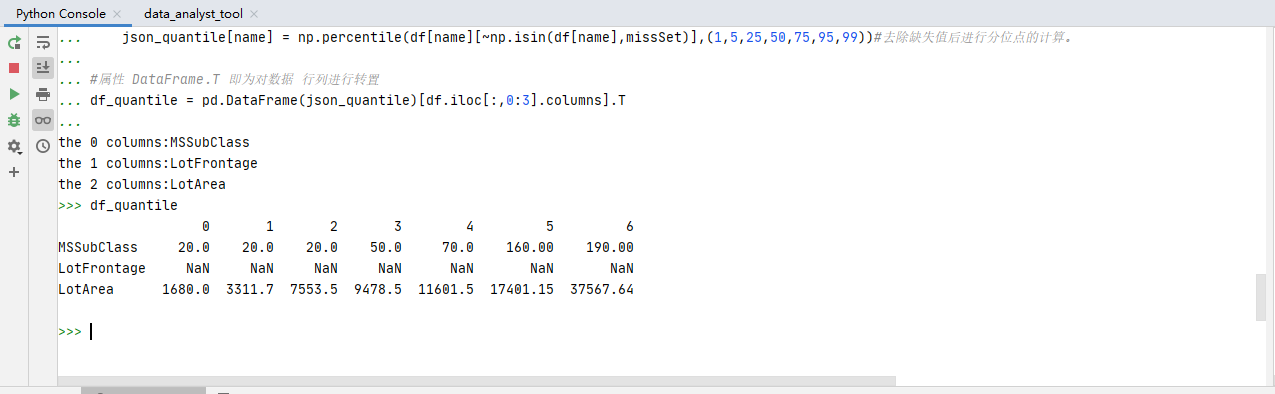
json_quantile = {}
for i,name in enumerate(df.iloc[:,0:3].columns):#取第一行前三列的数值
print('the {} columns:{}'.format(i, name))#打印出格式化的数值
json_quantile[name] = np.percentile(df[name][~np.isin(df[name],missSet)],(1,5,25,50,75,95,99))#去除缺失值后进行分位点的计算。
#属性 DataFrame.T 即为对数据 行列进行转置
df_quantile = pd.DataFrame(json_quantile)[df.iloc[:,0:3].columns].T
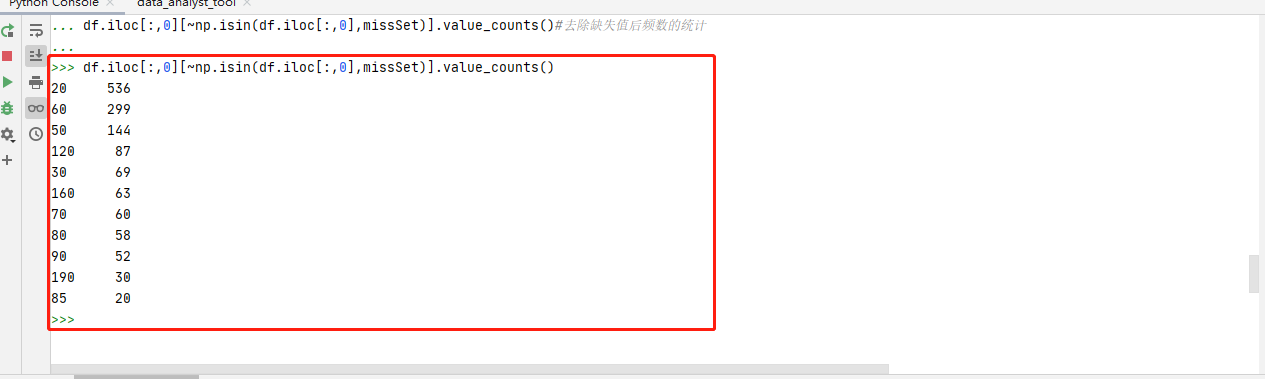
频数的代码:
#统计指示示例-频数
#(11)Frequent Values统计
df.iloc[:,0].value_counts().iloc[0:5,]#频数的统计
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)]#去除缺失值
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)].value_counts()#去除缺失值后频数的统计
代码运行结果:
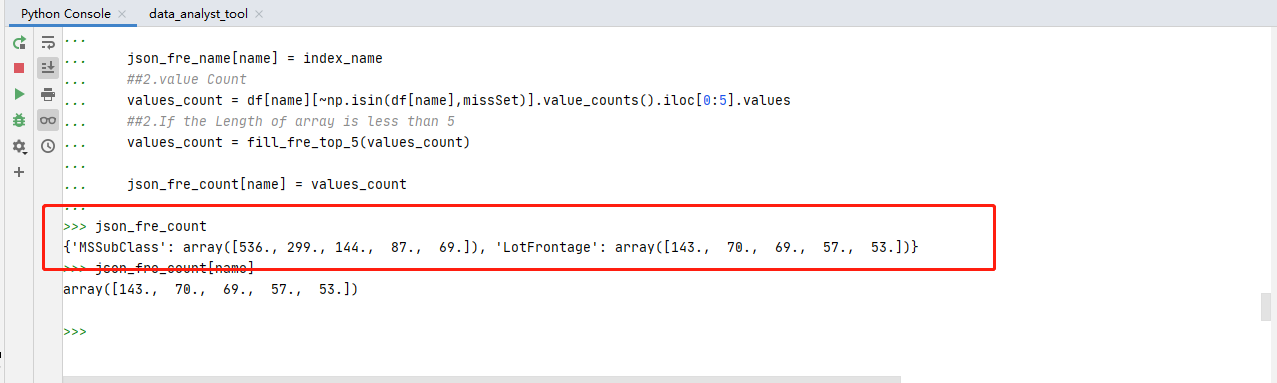
扩展小训练代码部分:
#扩展训练
#设置两个空字表
json_fre_name = {}
json_fre_count = {}
#设置一个函数
#取函数取值,返回一个矩阵
def fill_fre_top_5(x):
if(len(x))
对矩阵进行转置取值
df_fre_name = pd.DataFrame(json_fre_name)[df[['MSSubClass','LotFrontage']].columns].T
df_fre_count = pd.DataFrame(json_fre_count)[df[['MSSubClass','LotFrontage']].columns].T
df_fre = pd.concat([df_fre_name,df_fre_count],axis=1)

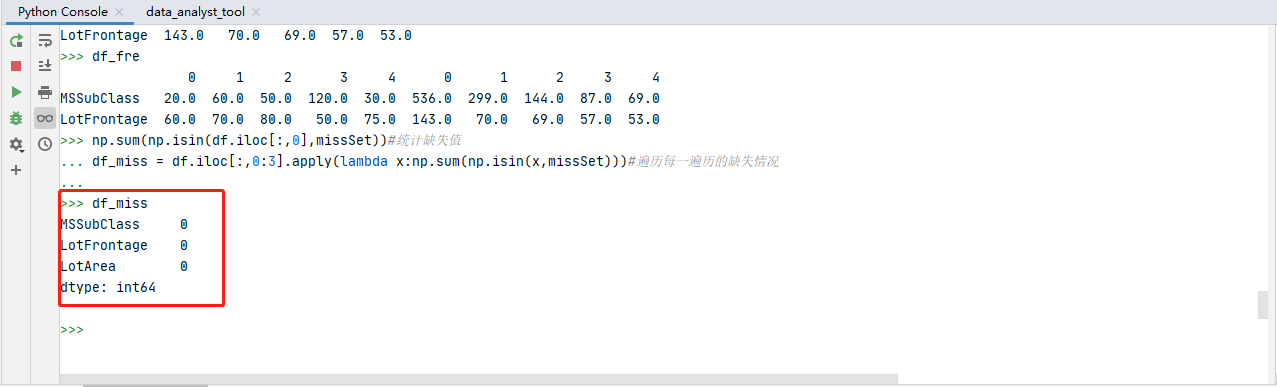
缺失值的统计的代码:
#统计指标示例-缺失值
#(12)Miss Values
np.sum(np.isin(df.iloc[:,0],missSet))#统计缺失值
df_miss = df.iloc[:,0:3].apply(lambda x:np.sum(np.isin(x,missSet)))#遍历每一遍历的缺失情况
执行结果:
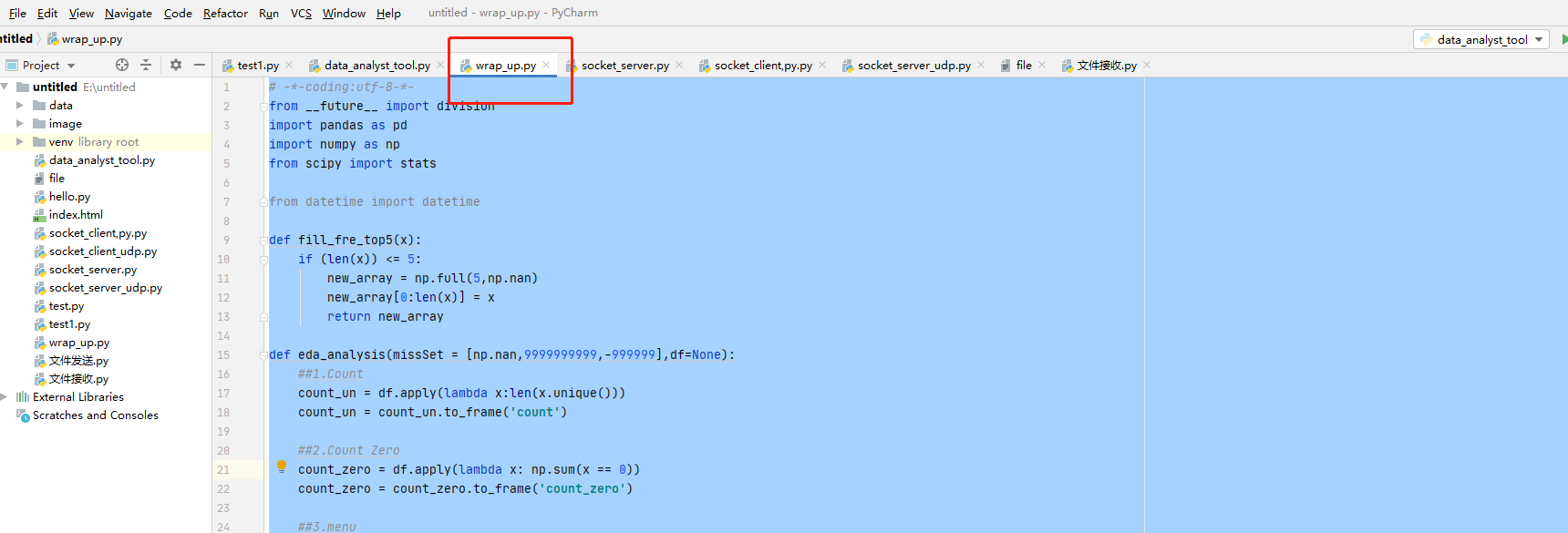
制作一个脚本,将所有工具进行整合。
-*-coding:utf-8-*-
from __future__ import division
import pandas as pd
import numpy as np
from scipy import stats
from datetime import datetime
def fill_fre_top5(x):
if (len(x))
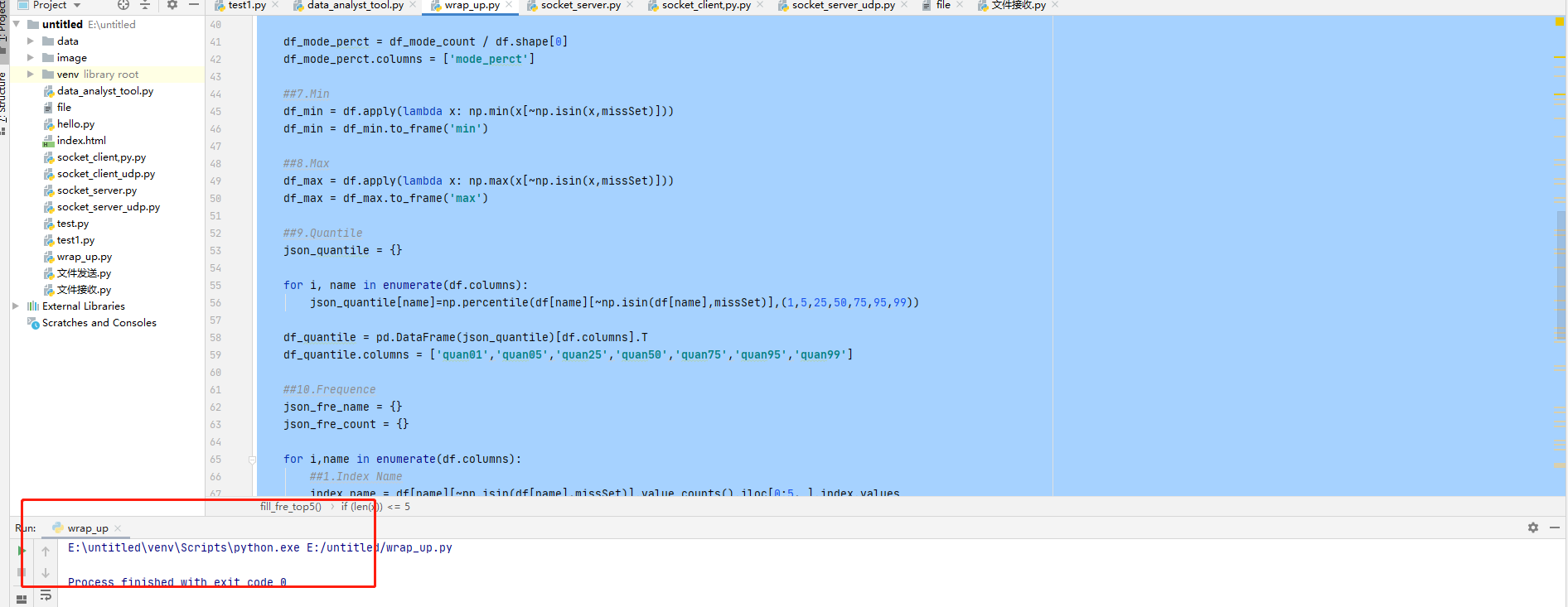
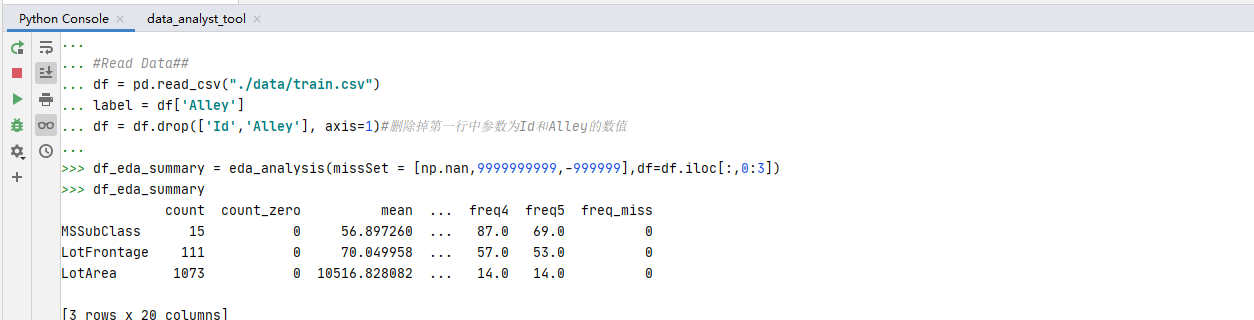
测试脚本,将制作好的Wrap_up导入进去进行测试,使用eda_analysis测试函数进行测试。
#-*-coding:utf-8-*-
from __future__ import division
from wrap_up import *
##0.Read Data##
#Read Data##
df = pd.read_csv("./data/train.csv")
label = df['Alley']
df = df.drop(['Id','Alley'], axis=1)#删除掉第一行中参数为Id和Alley的数值
#1.EDA##
df_eda_summary = eda_analysis(missSet = [np.nan,9999999999,-999999],df=df.iloc[:,0:3])

总结体会
Numpy的使用有求和统计、有分位统计、有频数、最大最小值统计等,Pandas是对数据进行抓取,对word、Excel、PDF的数据进行抓取。结合两者之所长,对数据进行筛选和清洗,达到对数据的要求。
感谢慕课网、CSDN不计其数的网友技术支持。
Original: https://blog.csdn.net/yi247630676/article/details/122448197
Author: 业里村牛欢喜
Title: Python使用numpy和Pandas来做数据分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/697200/
转载文章受原作者版权保护。转载请注明原作者出处!